




大家好,我是爱酱。本篇将会系统梳理神经网络架构(Neural Network Architecture)与深度学习模型(Deep Learning Model)的核心原理、主流方法、数学表达、工程实践与未来趋势,配合数学公式,帮助你全面理解这些概念。
注:本文章含大量数学算式、详细例子说明,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
注:本文章为入门介绍,爱酱会在之后逐一出单独文章介绍不同主流神经网络架构,如CNN、RNN、LSTM、Transformer、GAN、Autoencoder、GNN等,敬请期待!
一、神经网络架构的基本概念
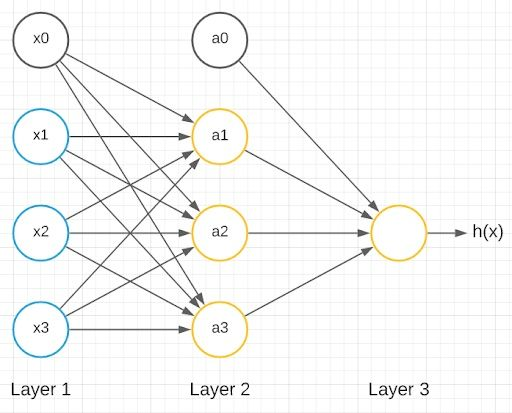
神经网络(Neural Network, NN)是一类受生物神经系统启发、由大量“神经元”节点组成的计算模型。深度学习(Deep Learning)则是以多层神经网络为核心的机器学习分支。
-
基本结构:输入层(Input Layer)、隐藏层(Hidden Layer)、输出层(Output Layer)
-
信息流:数据从输入层流向输出层,经过若干隐藏层,每层节点与下一层全连接或部分连接
-
数学表达:
其中
为第
层激活,
和
分别为权重和偏置,
为激活函数。
二、主流神经网络架构与深度学习模型
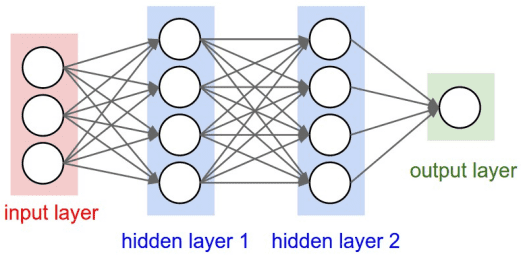
1. 前馈神经网络(Feedforward Neural Network, FNN)
-
结构:最基础的神经网络,数据单向流动,无环路
-
应用:回归、分类、简单模式识别
-
数学表达:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















与深度学习模型(Deep Learning):核心原理、数学表达、工程实践与未来趋势|主流神经网络架构与深度学习模型、对比与应用场景、优化流程&spm=1001.2101.3001.5002&articleId=149211167&d=1&t=3&u=6baa88383cb9405fb745bcc2c3e786d6)
 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









