




大家好,我是爱酱。上次我们在聊到数据准备和数据挖掘流程就承诺会在下篇文章聊聊如何根据不同任务选择合适的算法。现在,爱酱就来兑现承诺,带大家有系统地梳理:面对不同任务,如何选择合适的机器学习算法?
注:本文章颇长近3000字,建议先收藏再慢慢观看。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、明确你的任务类型
选择算法的第一步,是明确你的任务属于哪一类。常见用于应付不同任务类型的机器学习技术(Machine Learning Techniques)主要有以下五种:
-
分类(Classification):把数据分到不同类别,比如垃圾邮件识别、识别图片中的是猫猫还是狗狗。
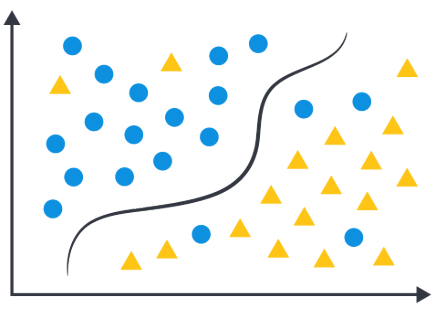
-
回归(Regression):预测连续数值,比如房价预测、销量预测。
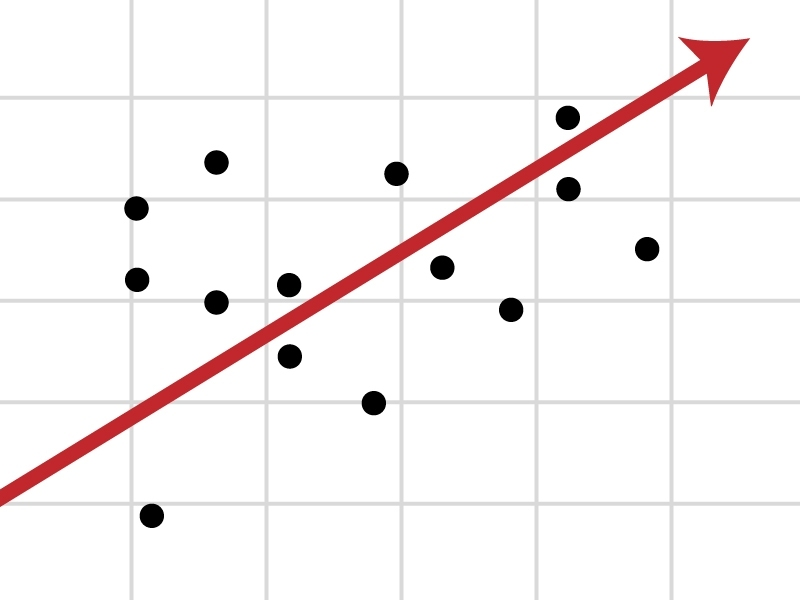
-
聚类(Clustering):无监督地发现数据中的分组,比如客户分群、市场细分。
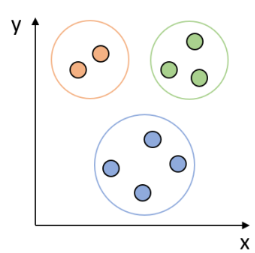
-
降维(Dimensionality Reduction):压缩特征(Features)数量,便于可视化或后续建模,比如PCA、t-SNE。
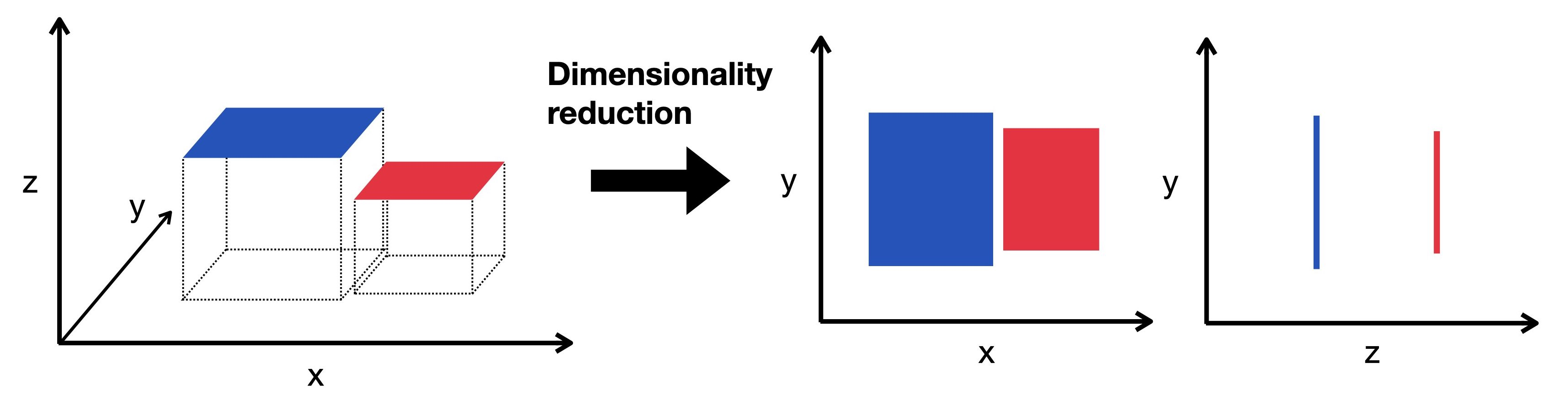
- 强化学习(Reinforcement Learning):让模型通过试错学习最优策略,比如游戏AI、自动驾驶。这部分比较深入,我们就先不深入探讨。后续有时间,我可以慢慢补上这些概念。
以上五种就是我们常见用以处理任务的五大类,但其实这五种也可以进一步被归纳进三大类学习模式(Learning Mode)中。
二、典型机器学习(Classical Machine Learning)类型
在典型机器学习里,其实可以分为两大部分:
监督式学习(Supervised Learning) 与 非监督式学习(Unsupervised Learning)。分类和回归属于监督学习,需要带标签(Tag)的数据,例如猫猫图片的标签为Cat,狗狗图片的标签为Dog等。模型通过学习已有样本的输入输出关系来进行预测。聚类和降维属于非监督学习,不依赖标签,主要通过分析数据的内在结构和分布来发现规律(Patterns)。好了,那么强化学习呢?其实,强化学习并不算是典型机器学习。这是一种更新晋、复杂的学习模式。因此,他算是一种特殊类型,模型会通过与环境交互、不断试错,途中回馈奖励或惩罚(Reward & Penalty),最终学会最优策略。理解每种技术的监督属性,有助于我们根据具体任务和数据类型选择最合适的算法。
三、如何根据任务类型选择合适的机器学习算法?
先声明一下,下面列出的是大多数应对五大任务种类的主流算法,以及他们常被应用的条件。以下内容可能会出现一些较复杂的用语,大伙不明白的可以留言问我或是到网上查询。至于实际上如何利用,或者一些特殊情况的特例不能一一列明,望谅解。事不宜迟,我们开始吧。
1. 分类(Classification)——监督学习
任务简介:
将数据分到不同类别,如垃圾邮件识别、图片中的猫狗分类等。
常用算法:
-
逻辑回归(Logistic Regression):适用于二分类(Binary Classification)或多分类(Multi-class Classification)的线性(Linear)问题,简单高效。
-
决策树(Decision Tree):适合处理非线性(Non-Linear)特征,结构清晰易解释。
-
随机森林(Random Forest):集成多棵决策树,提升准确率,防止过拟合(Overfitting)。
-
支持向量机(SVM,Support Vector Machine):适合高维数据(High-dimensional Data),能处理线性和非线性分类。
-
K近邻(KNN):基于“邻居”投票,适合小数据集。
-
朴素贝叶斯(Naive Bayes):适合文本分类、特征独立性强的数据。
2. 回归(Regression)——监督学习
任务简介:
预测连续数值,如房价预测、销量预测等。
常用算法:
-
线性回归(Linear Regression):最基础的回归方法,适合线性关系。
-
L2 岭回归(L2 Regularization / Ridge Regression)、L1 Lasso回归(L1 Regularization / Lasso Regression)、弹性网(Elastic Net):带正则化(Regularization)项,防止过拟合,适合特征(Feature)多且相关性(Correlation)强的数据。
-
决策树回归(Decision Tree Regressor)、随机森林回归(Random Forest Regressor):适合复杂非线性数据。
-
支持向量回归(SVR):适合高维特征和非线性关系。
-
神经网络(ANNs):适合大规模复杂数据。
3. 聚类(Clustering)——无监督学习
任务简介:
自动发现数据中的分组结构,如客户分群、市场细分等。
常用算法:
-
K均值聚类(K-Means):最常用,适合大多数聚类任务,易于实现。
-
层次聚类(Hierarchical Clustering):适合需要分层结构的场景。
-
DBSCAN:能发现任意形状的簇,适合异常点较多的数据。
4. 降维(Dimensionality Reduction)——无监督学习
任务简介:
压缩特征数量,便于可视化或后续建模,如PCA、t-SNE等。
常用算法:
-
主成分分析(PCA):最常用的线性降维方法。
-
奇异值分解(SVD)、非负矩阵分解(NMF):适合矩阵(Matrix)数据。
-
t-SNE、Isomap、LLE等流形学习方法:适合高维复杂数据的可视化。
5. 强化学习(Reinforcement Learning)——特殊类型
任务简介:
模型通过与环境交互、试错获得最优策略,如游戏AI、自动驾驶等。
常用算法:
-
Q-Learning:经典的无模型强化学习算法。
-
SARSA:与Q-Learning类似,适合有随机性的环境。
-
深度Q网络(DQN)、PPO、A2C、DDPG等:适合复杂环境和大规模状态空间。
四、实际选择流程总结
-
明确问题类型(分类、回归、聚类等)
-
分析数据特征(数据量、维度、类型、是否有标签)
-
结合实际需求(可解释性、资源、准确率等)
-
优先尝试简单模型(如表现不佳再用复杂模型)
-
交叉验证与调参(评估多种算法效果,选择最优解)
五、温馨提示
-
记住,没有“万能算法”,只有“最适合当前任务的数据和需求”的算法。
-
可以借助 scikit-learn 官方的[算法选择流程图],快速定位常用算法。这里也贴上网站:scikit-learn: machine learning in Python — scikit-learn 1.7.0 documentation
六、结语
选择合适的算法,是机器学习项目成功的关键一步。理解任务、了解数据、结合实际需求,才能做出科学高效的选择。下期我们可以聊聊模型训练后的评估与优化,或者伙伴们对任何一种算法特别感兴趣,我可以可以单独出文章介绍,比如是强化学习,请敬请期待!
谢谢大家看到这里,新频道发展不易,请不要吝惜你的每个点赞/关注/收藏!我是爱酱,我们下次再见,谢谢收看!






















 到【灌水乐园】发言
到【灌水乐园】发言







