




目录
1、Ollama 简介
Ollama 是一个开源的大语言模型(LLM)本地化部署与管理平台,核心目标是简化私有化模型部署流程。其主要特点包括:
-
私有化部署:
-
完全离线运行,无需网络连接,保障数据隐私安全(如企业敏感文档、医疗数据)。
-
-
多模型支持:
-
支持通义千问(Qwen)、小羊驼系列(Alpaca)、DeepSeek 等 1700+ 预训练模型,涵盖文本生成、代码补全、多模态任务等。
-
-
极简操作:
-
开发者通过命令行即可管理模型:
-
ollama run qwen:运行通义千问模型。 -
ollama list:查看已安装模型。
-
-
-
开放生态:
-
兼容 OpenAI API 接口,支持集成 Python、SpringAI 等开发框架。
-
2、下载 Ollama
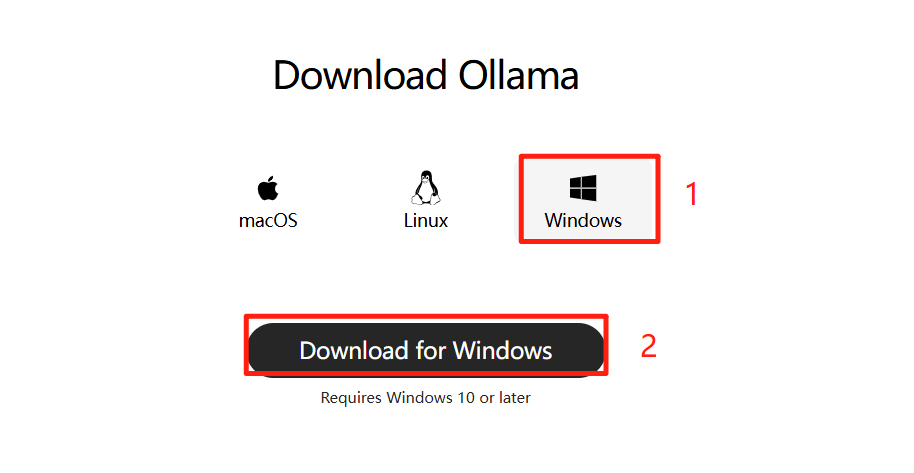
访问 Ollama 官方主页:Ollama。支持 macOS, Linux 和 Windows 系统,点击下载按钮获取 OllamaSetup.exe 安装程序。
3、安装 Ollama
双击安装文件,点击「Install」开始安装。目前的 Ollama 默认安装路径为 C:\Users\Administrator\AppData\Local\Programs\Ollama,并不会让用户自定义选择安装路径。
安装完成后,会在电脑上出现 Ollama 图标。可以不用先启动 Ollama。
4、环境变量配置
4.1、OLLAMA_MODELS 环境变量配置
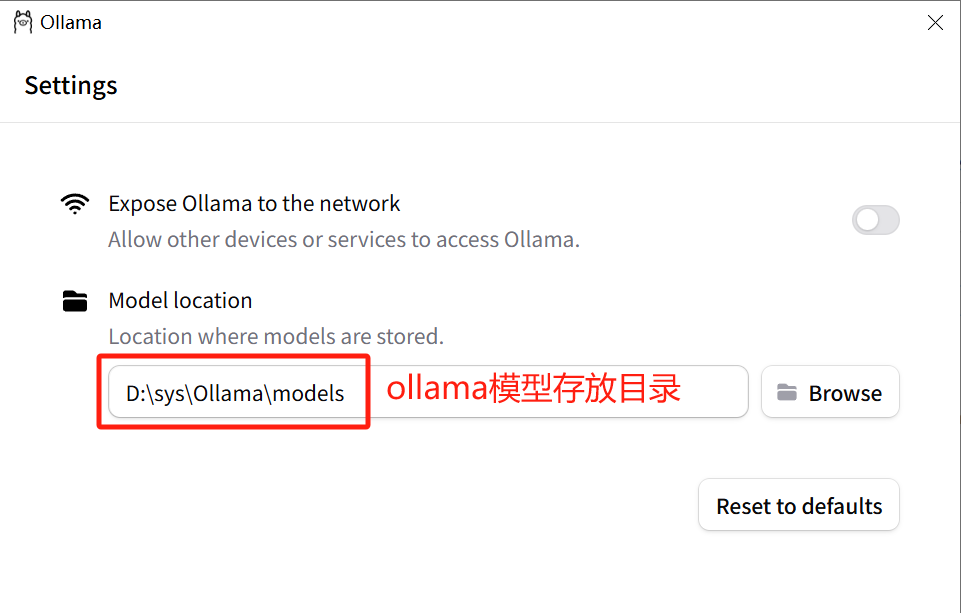
Ollama 默认把模型下载到 C 盘,如果想更换模型下载位置,可以新增环境变量 OLLAMA_MODELS,设置为模型下载的路径。建议将模型存储在其他盘以避免影响电脑运行速度。
-
操作步骤:
-
打开【系统环境变量】。
-
新建一个系统变量
OLLAMA_MODELS,并设置其值(路径)为D:\sys\Ollama\models。
-
4.2、OLLAMA_HOST 环境变量配置
OLLAMA_HOST 是 Ollama 的核心环境变量之一,主要用于控制 Ollama 服务的网络访问范围和监听地址,直接影响服务的可见性与连接方式。
-
操作步骤:
-
打开【系统环境变量】。
-
新建一个系统变量
OLLAMA_HOST,并设置其值为0.0.0.0。这样可以开放所有网络接口,允许局域网内其他设备通过 IP 地址访问 Ollama 服务。
-
启动 Ollama 后,在右键图标中点击「Settings」,确认环境变量已配置成功。
5、运行 Ollama
将上述更改的环境变量保存后,在【开始】菜单中找到并重新启动 Ollama。或者在命令提示符(cmd)中,导航到 ollama.exe 的所在位置,并执行以下命令:
cd C:\Users\Administrator\AppData\Local\Programs\Ollama然后运行 Ollama。
6、核心操作命令
6.1 运行模型
命令格式
ollama run <模型名称>[:<版本>]示例
$ ollama run deepseek-r1:7b
$ ollama run qwen2.5:7b
$ ollama run qwen2.5:14b
pulling manifest
pulling 2049f5674b1e: 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████ ▏ 9.0 GB/9.0 GB 11 MB/s 0s
pulling 66b9ea09bd5b: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████▏ 68 B
pulling eb4402837c78: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.5 KB
pulling 832dd9e00a68: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB
pulling db59b814cab7: 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████▏ 488 B
verifying sha256 digest
writing manifest
success-
功能:运行指定版本的 DeepSeek-R1 模型(7B 参数版本)。
-
首次执行:首次执行该命令时,Ollama 会从官方模型库下载模型。
6.2 Ollama 公网地址
默认端口为 11434,访问地址为:
http://localhost:11434/-
功能:在浏览器中访问上述地址,即可看到 Ollama 正在运行的模型,并通过 Web 界面与模型进行交互。
6.3 核心操作命令
列出已安装模型
$ ollama list
NAME ID SIZE MODIFIED
qwen2.5:7b 845dbda0ea48 4.7 GB 13 days ago
deepseek-r1:7b 755ced02ce7b 4.7 GB 2 weeks ago
qwen2.5:14b 7cdf5a0187d5 9.0 GB 2 minutes ago
$ http://localhost:11434/v1/models-
功能:列出当前已安装的所有模型及其版本。
删除模型
ollama rm <模型名称>[:<版本>]
eg:ollama rm qwen2.5:14b-
功能:删除指定的模型及其版本,释放存储空间。
查看帮助信息
ollama --help-
功能:显示 Ollama 的帮助信息,包括所有可用命令及其简要说明。


















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









