




目录
1、xinference介绍
Xinference(全称Xorbits Inference)是一款由百度开发的性能强大且功能全面的分布式推理框架,专为大规模模型推理任务设计。以下是其主要特点和应用场景:
核心功能
-
支持多种AI模型:包括大语言模型(LLM)、语音识别模型、多模态模型等
-
一键部署:简化模型部署流程,支持内置前沿开源模型和用户自定义模型
-
分布式架构:支持跨设备和跨服务器部署,实现高并发推理
技术特性
-
异构硬件支持:可同时利用CPU和GPU进行推理,优化资源利用率
-
多种推理引擎:支持vLLM、llama.cpp、transformers等多种后端引擎
-
灵活API:提供RPC、RESTful API(兼容OpenAI协议)等多种接口
应用场景
-
私有化部署:保障数据隐私安全,适合企业和个人使用
-
模型性能优化:专注于降低推理延迟,提高吞吐量
-
第三方集成:可与LangChain等流行库无缝对接
部署方式
-
支持多种安装方式:包括pip安装、Docker部署等
-
跨平台支持:可在Linux、Windows、MacOS等系统运行
该框架通过简化模型部署流程和优化推理性能,帮助开发者在个人电脑或分布式集群中高效运行各类AI模型。
2、准备工作
-
Xinference 使用 GPU 加速推理,镜像需要在有 GPU 显卡并且安装 CUDA 的机器上运行。
-
保证 CUDA 在机器上正确安装。可以使用
nvidia-smi检查是否正确运行。
# 确保宿主机已安装 NVIDIA 驱动
$ nvidia-smi
Mon Jul 7 14:01:36 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 561.19 Driver Version: 561.19 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+-
镜像中的 CUDA 版本为
12.4。为了不出现预期之外的问题,请将宿主机的 CUDA 版本和 NVIDIA Driver 版本分别升级到12.4和550以上。 -
请确保已安装 NVIDIA Container Toolkit 。
3、xinference镜像介绍
3.1、使用Docker Hub 拉取镜像
您可以直接通过 Docker Hub 来获取最新的或特定版本的 Xinference 镜像。
-
对于常规用户(国内需要魔法上网):
-
如果您能够访问 Docker Hub,可以直接使用以下命令拉取官方镜像:
docker pull xprobe/xinference:<tag> -
可用标签包括
nightly-main,v<release version>, 和latest。
-
-
对于受限于网络环境的用户:
-
如果您遇到访问 Docker Hub 的困难,可以使用阿里云提供的镜像地址来拉取。例如:
docker pull crpi-49yei0hvmhr144pw.cn-hangzhou.personal.cr.aliyuncs.com/xprobe_xinference2/xinference:<tag>
-
3.2、镜像标签说明
-
nightly-main: 这个镜像是每天从 GitHub main 分支构建的,不保证稳定性和可靠性。 -
v<release version>: 在 Xinference 每次发布时制作的版本,通常被认为是稳定的。 -
latest: 该标签指向最新的正式发布的版本。
3.3、CPU 版本
如果您需要特定于 CPU 的镜像,可以在标签后加上 -cpu 后缀。例如:
docker pull xprobe/xinference:nightly-main-cpu或者使用阿里云提供的地址:
docker pull crpi-49yei0hvmhr144pw.cn-hangzhou.personal.cr.aliyuncs.com/xprobe_xinference2/xinference:nightly-main-cpu4、Xinference单机部署
基于Xinference v1.7.0.post1版本或更新版本,以下是单机部署的详细步骤:
4.1、拉取 Xinference 镜像
# CPU 模式
$ docker pull xprobe/xinference:v1.7.0.post1-cpu
# 启用 GPU 加速(需 NVIDIA 驱动)
$ docker pull xprobe/xinference:v1.7.0.post1
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
xprobe/xinference v1.7.0.post1 0949777d1ea9 8 days ago 27GB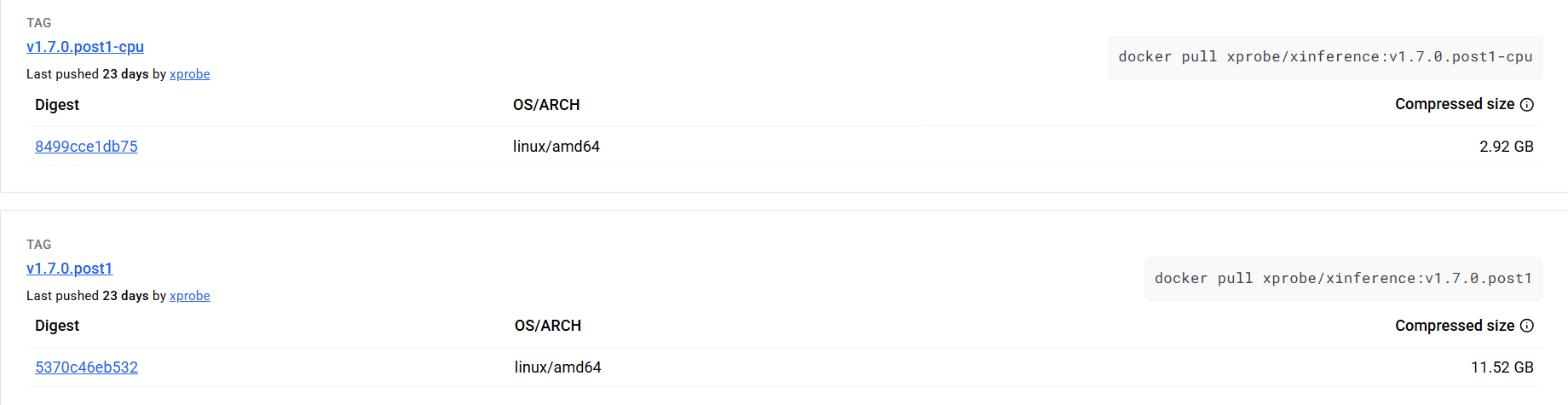
4.2、启动容器语法
# CPU 模式(根据硬件选择命令)
docker run -d -p 9998:9997 --name xinference xprobe/xinference:v1.7.0.post1-cpu
# 启用 GPU 加速(需 NVIDIA 驱动,根据硬件选择命令)
docker run -d --gpus all -p 9998:9997 --name xinference xprobe/xinference:v1.7.0.post1-cpu
# 限制 GPU 显存,为容器分配指定 GPU 资源
docker run -d --gpus '"device=0,1"' -p 9998:9998 \
-e NVIDIA_VISIBLE_DEVICES=0,1 \
xprobe/xinference:latest
# 调整容器资源限制,限制 CPU 和内存使用
docker run -d -p 9998:9998 \
--cpus 4 \
--memory 16g \
xprobe/xinference:latest
# 启用 HTTPS
docker run -d -p 443:9998 \
-v /etc/ssl/certs:/etc/ssl/certs \
xprobe/xinference:latest \
--tls-certfile=/etc/ssl/certs/server.crt \
--tls-keyfile=/etc/ssl/certs/server.key4.3、挂载模型目录
默认情况下,镜像中不包含任何模型文件,使用过程中会在容器内下载模型。如果需要使用已经下载好的模型,需要将宿主机的目录挂载到容器内。这种情况下,需要在运行容器时指定本地卷,并且为 Xinference 配置环境变量。
docker run -v </on/your/host>:</on/the/container> -e XINFERENCE_HOME=</on/the/container> -p 9998:9997 --gpus all xprobe/xinference:v<your_version> xinference-local -H 0.0.0.0上述命令的原理是将主机上指定的目录挂载到容器中,并设置 XINFERENCE_HOME 环境变量指向容器内的该目录。这样,所有下载的模型文件将存储在您在主机上指定的目录中。您无需担心在 Docker 容器停止时丢失这些文件,下次运行容器时,您可以直接使用现有的模型,无需重复下载。
如果你在宿主机使用的默认路径下载的模型,由于 xinference cache 目录是用的软链的方式存储模型,需要将原文件所在的目录也挂载到容器内。例如你使用 huggingface 和 modelscope 作为模型仓库,那么需要将这两个对应的目录挂载到容器内,一般对应的 cache 目录分别在 <home_path>/.cache/huggingface 和 <home_path>/.cache/modelscope,使用的命令如下:
docker run \
-v </your/home/path>/.xinference:/root/.xinference \
-v </your/home/path>/.cache/huggingface:/root/.cache/huggingface \
-v </your/home/path>/.cache/modelscope:/root/.cache/modelscope \
-p 9997:9997 \
--gpus all \
xprobe/xinference:v<your_version> \
xinference-local -H 0.0.0.04.4、单机部署完整命令
Windows下powershell中执行:
docker run --restart=always -d `
--log-driver json-file --log-opt max-size=100m --log-opt max-file=2 `
--name xinference `
-v E:/sys/xinference/.xinference:/root/.xinference `
-v E:/sys/xinference/.cache/huggingface:/root/.cache/huggingface `
-v E:/sys/xinference/.cache/modelscope:/root/.cache/modelscope `
-p 9998:9997 `
--gpus all `
xprobe/xinference:v1.7.0.post1 `
xinference-local -H 0.0.0.0 --log-level info启动成功等待1分钟左右在访问xinference:http://localhost:9998 或 http://192.168.2.100:9998/
参数详解:
-
--gpus必须指定,表示镜像必须运行在有 GPU 的机器上,否则会出现错误。 -
-d以守护进程(后台)模式运行容器,避免阻塞终端。 -
--name xinference为容器指定名称为xinference,便于后续管理(如停止、重启) -
-H 0.0.0.0也是必须指定的,否则在容器外无法连接到 Xinference 服务。 -
E:/sys/xinference/.xinference:/root/.xinference持久化存储 Xinference 的配置文件(如模型元数据、服务配置)。 -
E:/sys/xinference/.cache/huggingface:/root/.cache/huggingface缓存从 Hugging Face 下载的模型文件,避免重复下载。 -
E:/sys/xinference/.cache/modelscope:/root/.cache/modelscope缓存从 ModelScope 下载的模型文件,避免重复下载。
4.5、验证部署状态
访问 Web UI:http://localhost:9998,若看到管理界面则部署成功。
5、Xinference模型部署方法
5.1、UI操作启动模型(方法1)
-
访问
http://localhost:9998→ 进入"Launch Model"标签 -
选择模型(如
qwen-chat)→ 设置参数(如量化等级、引擎类型)→ 点击启动 -
首次启动会自动下载模型文件并缓存至
~/.xinference/cache。
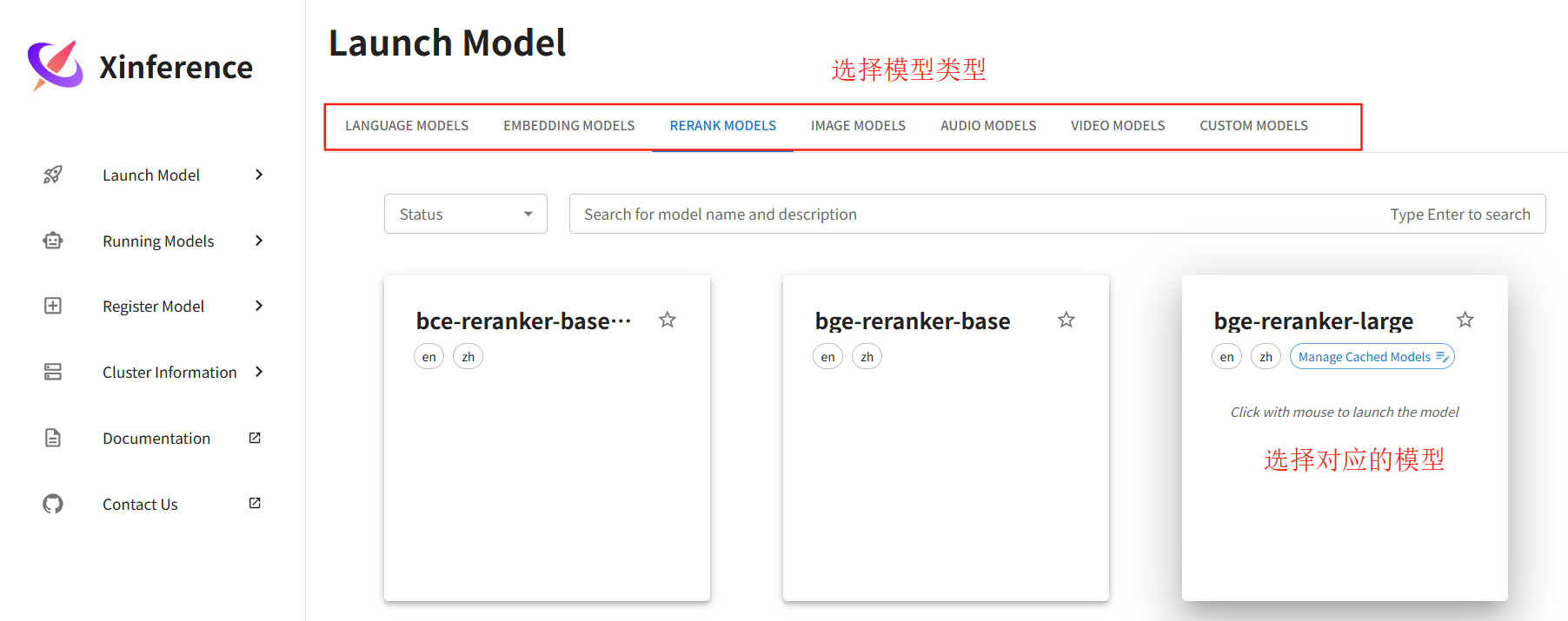
5.2、命令行启动模型(方法2)
进入容器内docker exec -it xinference bash启动模型,执行如下命令:
xinference launch --model-name bge-large-zh-v1.5 --model-type embedding
# 启动 Rerank 模型(如 bge-reranker-large)
xinference launch --model-name bge-reranker-large --model-type rerank
# 启动 Embedding 模型(如 bge-large-en)
xinference launch --model-name bge-large-en --model-type embedding
# 启动 LLM(如 Llama3-8B)
xinference launch --model-name llama-3-8b-instruct --model-type LLM --size-in-billions 8 --quantization 4
docker exec -it xinference bash -c "xinference launch --model-name bge-reranker-large --model-type rerank"5.3、通过 API 启动模型
直接通过 REST API 动态加载模型:
# 启动 Rerank 模型
curl -X POST "http://localhost:9998/v1/models" \
-H "Content-Type: application/json" \
-d '{
"model_type": "rerank",
"model_name": "bge-reranker-large",
"model_format": "pytorch"
}'5.4、查看正在运行的模型
访问http://localhost:9998 → 进入"Running Models"标签.
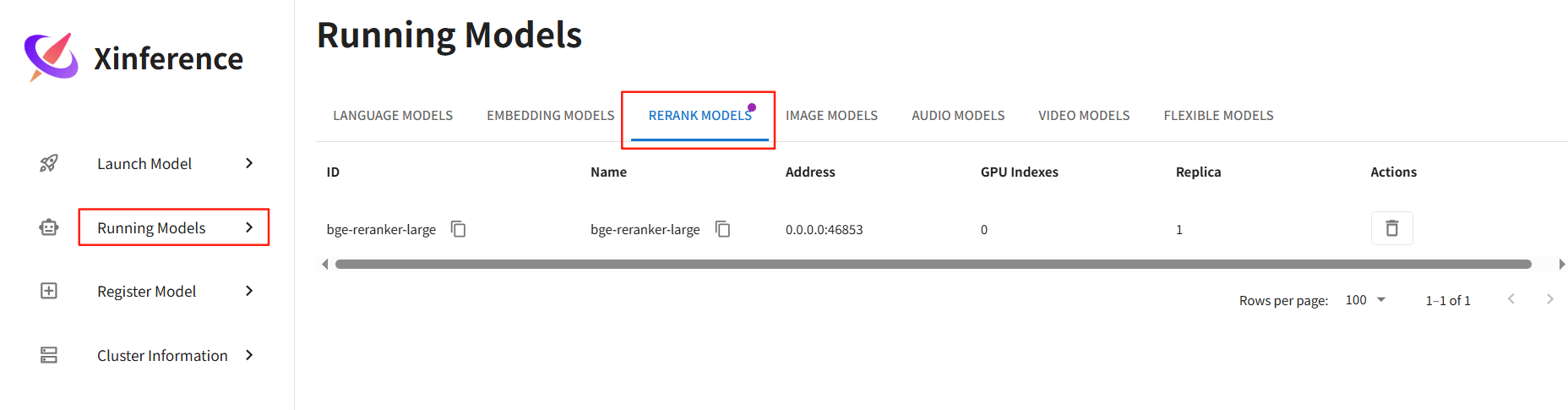
# 方式一
http://localhost:9998/v1/models
# 方式二
$ docker exec -it xinference bash
$ root@c3e9add70d72:/opt/inference# xinference list
UID Type Name
------------------ ------ ------------------
bge-reranker-large rerank bge-reranker-large
# 方式三
访问Xinference:http://localhost:9998/
点击“Running Models”,查看已加载模型

















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









