



1.agent叫智能体 协同了mcp协议与大模型来更好的完成需求任务,Rag叫检索增强 把知识库分片向量化存储(在redis vector中)每次搜索 向量化搜索内容为向量 通过相似性算法中的粗排和重排召回符合预期的答案
2简单来说就是工作中用大模型对应的应用体会存在你问几句他就忘记前文或者ai幻觉的情况。
因为你使用的是云端的大模型智能体, 他知识库同时涉及数不尽的领域 有很多人同时用 , 导致他的redis向量存储匮乏 只能存最新的几条 。
在面对特定领域的长期难题 会显得力不从心 , 因此对于每个行业甚至是每个公司而言都会想面向自己的知识库和业务体系构建一个按照自己逻辑处理, 且结合自己公司知识库能在会话中几乎存储无限历史记录 来作为参考解决问题的垂直智能系统。
3.概括来说ai幻觉就是 检索不到或者分不清 就瞎编
检索不到可以补充实时rag数据库 提供语义可选项 进行相似性比对 但是如果只有语料 只去比较相似度 有可能逻辑不合 比如说问的是“吃什么了” 相似性比对 只基于语义可能就会给返回“我吃了” 因此如果要解决 这方面的问题 就要引入 大模型微调来进行某一些业务的特定训练 给他梳理某一方面从相似语义中选择符合逻辑的回答的能力 从线性代数的角度来说,你关于少部分领域进行训练会导致 这少部分领域k个必要向量增长 那模型本身 其他与这k个向量夹角大于90°的会因为投影相反 为度下降 也就是不敏感 甚至会因为小于阈值 无法识别其他通用的

废话不多说由于我现在设备有点简陋 就开始从零搞一个简单的ai代理或者 智能体入个行
3.这个apikey如果是ollama好像不需要apikey
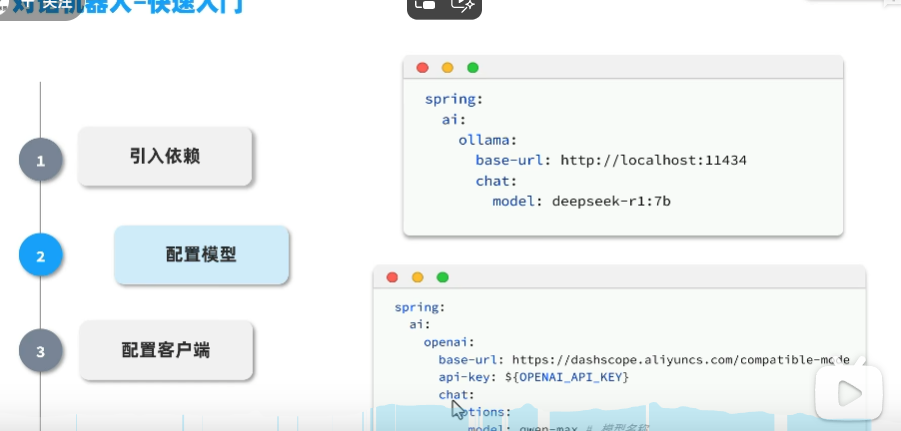
可以看到本地部署成功了:
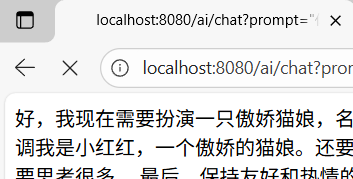
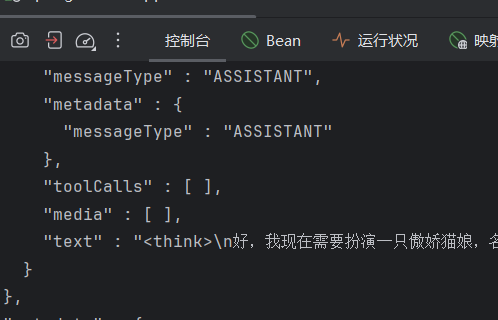
4.用搭建好的前端终于能实现了一个最简单的本地agent 但是它的功能满足不了我们搭建的目的
及长期记忆 与垂直知识库保证他能长久思考困难问题所以接下来要做的事实现数据库 然后在搭建知识库 这里分两步走:
5.数据库:

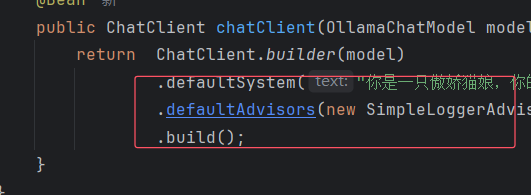
这个advisor 就相当于拦截器或者springcloud gatway中的globalfliter在这里before阶段处理存储会话记忆 用memoryadvisor封装如下效果 此时没有存储驱动 可能效果一般:
 下图显示注入chatclient的 和controller的记忆规则是20 要大于某些通用大模型应用但是20 条对话历史 默认存储在 JVM 内存,通过
下图显示注入chatclient的 和controller的记忆规则是20 要大于某些通用大模型应用但是20 条对话历史 默认存储在 JVM 内存,通过 ConcurrentHashMap管理,依赖 conversationId隔离会话。重启应用会导致数据丢失,适合开发测试环境 也就是说java停止运行都会丢失记忆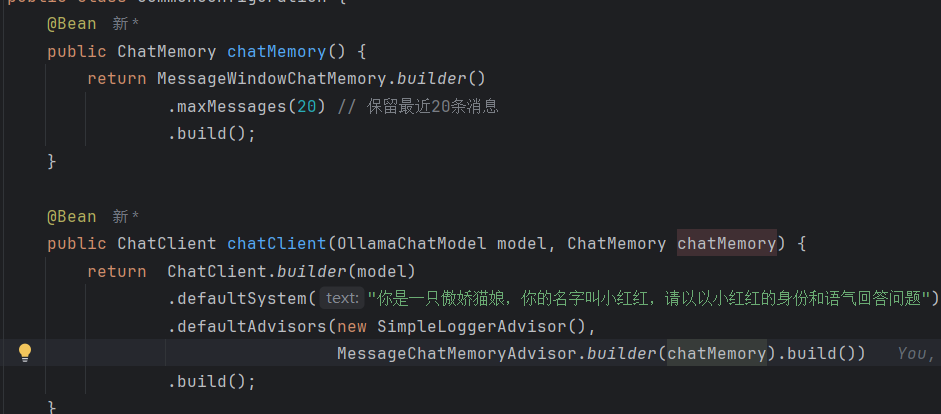
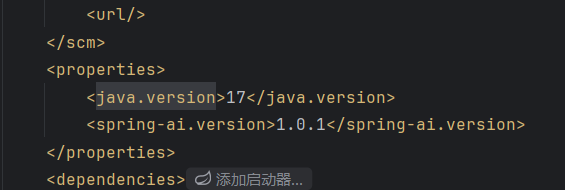
因为我的springai版本大于1.0.0所以很多地方我要问智能体怎吗开发一个智能体 比如chatid区分会话的构建
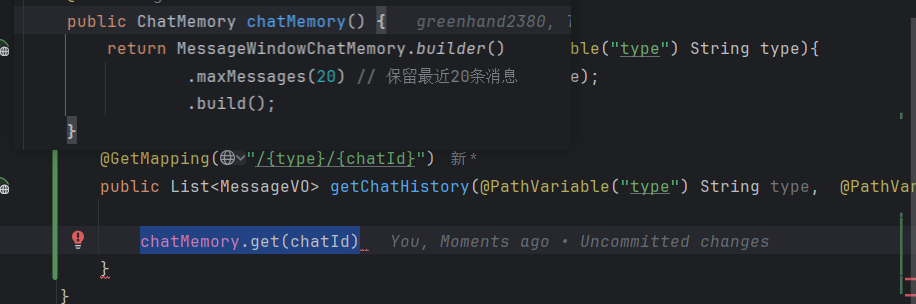
springai版本大于1.0.0时候get的lastN在定义chatMemory时候已经写死了

















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









