



1.首先需要安装这四个 分别是框架 检验工具 压力测试 数据记录及硬件监控

2.偷学了下ai-cli:CloudBase AI CLI 使用文档 | 腾讯云开发 CloudBase - 一站式后端云服务
大概明白wsl powershell 怎么运行 npm怎么处理源和缓存 因为claudecode逼事多 所以换成了腾讯的这个工具试了试 感觉前端亡朝了
3 为了学习大模型微调 补充了下知识 :每个conda 都是一个大号的进程 在jupyter kernel多进程运行 用jupyter前端加以控制 这也就是这俩为什么变成大模型运行的标配的原因
原来python不仅能访问操作系统机器目录 还有计算机物理交互接口
if cuda_available: # 版本信息 print(f"PyTorch Version: {torch.__version__}") print(f"CUDA Version: {torch.version.cuda}") print(f"cuDNN Version: {torch.backends.cudnn.version()}") # 设备枚举 device_count = torch.cuda.device_count() print(f"\nNumber of GPUs: {device_count}") # 遍历每个GPU for i in range(device_count): print(f"\nGPU {i}: {torch.cuda.get_device_name(i)}") props = torch.cuda.get_device_properties(i) total_mem = props.total_memory / (1024 ** 3) allocated = torch.cuda.memory_allocated(i) / (1024 ** 3) free = total_mem - allocated print(f" Compute Capability: {props.major}.{props.minor}") print(f" Total Memory: {total_mem:.2f} GB") print(f" Allocated: {allocated:.2f} GB | Free: {free:.2f} GB") else: print("\nPossible reasons: Missing NVIDIA driver, CUDA toolkit, or incompatible PyTorch build.")
物理性:代码直接操作计算机的真实GPU硬件,显存与算力均为物理资源。
Conda作用:仅通过管理软件依赖(如PyTorch版本、CUDA工具链)控制代码访问GPU的方式,不虚拟化硬件。
环境变量:CUDA_VISIBLE_DEVICES可动态重映射物理GPU的逻辑索引,但不改变硬件归属
PyTorch 是 计算引擎:接收 Conda 配置好的环境后,直接操作 GPU 执行计算任务
4.先面向claude code进行粗学一下 整体分为:
1.数据准备脚本创建prompt 2.配置DeepSeek模型和LoRA参数 3.训练配置 - 正在创建训练脚本 导入大量训练参数(
🔧 LoRA注入(第3步):
- 作用:给模型"做手术",插入可训练的小矩阵
- 控制:哪些层可以训练(target_modules)、LoRA秩多大(r=16)
- 类比:给汽车换专业方向盘(只改方向盘,不动发动机)
⚙️ 训练配置(第4步):
- 作用:设置"训练过程"的参数
- 控制:学习多快(learning_rate)、一次看多少数据(batch_size)、训练多久(max_steps)
- 类比:驾校教练怎么教你开车(开多快、练多久、什么时候休息)
🎯 简单理解:
- LoRA = 决定"改什么"(只改方向盘 vs 改整个发动机)
完全独立的两件事! LoRA是模型结构改造,训练配置是学习过程控制。
)4 然后创建训练对象 在训练结束后保存lora权重作为 快照 用于专业化快速配置
5 训练完之后还要保留权重 作为快速加载的快照
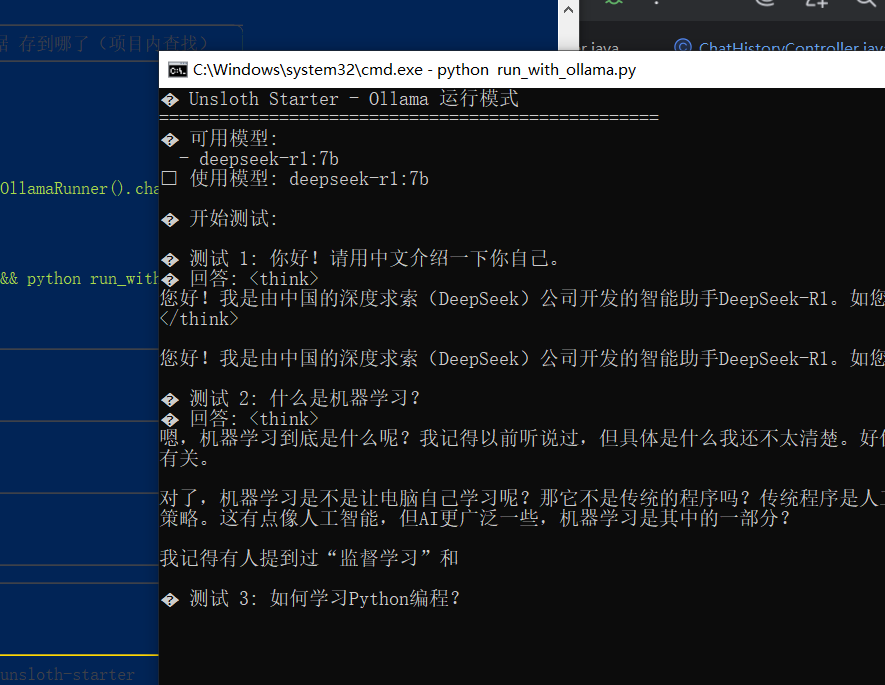
我基于前面的学的ai -cli 搭出来 一个这模样的 项目 他会测试后 开启对话

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









