题目:
1、中文大写金额数字前应标明“人民币”字样。中文大写金额数字应用壹、贰、叁、肆、伍、陆、柒、捌、玖、拾、佰、仟、万、亿、元、角、分、零、整等字样填写。
2、中文大写金额数字到“元”为止的,在“元”之后,应写“整字,如532.00应写成“人民币伍佰叁拾贰元整”。在”角“和”分“后面不写”整字。
3、阿拉伯数字中间有“0”时,中文大写要写“零”字,阿拉伯数字中间连续有几个“0”时,中文大写金额中间只写一个“零”字,如6007.14,应写成“人民币陆仟零柒元壹角肆分“。
4、10应写作“拾”,100应写作“壹佰”。例如,1010.00应写作“人民币壹仟零拾元整”,110.00应写作“人民币壹佰拾元整”
5、十万以上的数字接千不用加“零”,例如,30105000.00应写作“人民币叁仟零拾万伍仟元整”
样例:
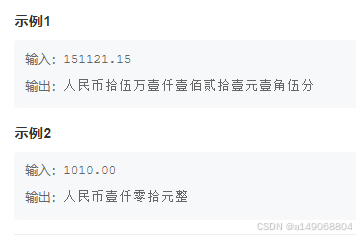
个人思路:
1、使用字符串的方法进行实现,如果使用数字计算,可能会导致较大的计算量,切逻辑较为混乱。
2、将人民币通过字符串的形式输入,将整数部分和小数部分分开存储,并获取到他们各自的长度。
3、首先将零 壹 贰 叁 肆 伍 陆等中文字体按他们的顺序存入到字符数组中,如壹在数组中的下标就是1.更方便打印输出
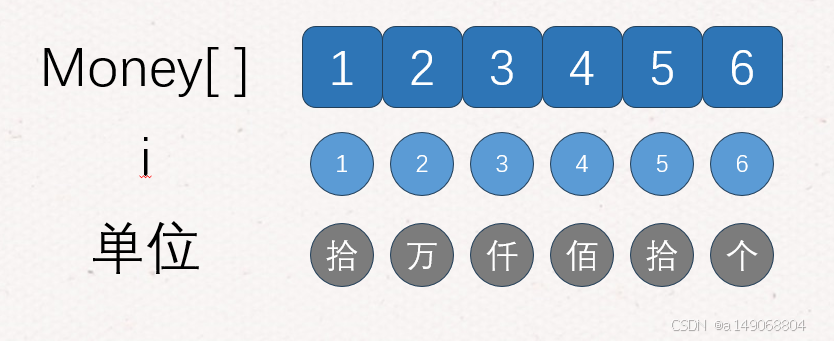
4、对于人民币的读法,我们是从左向右读,但其实,我们需要先从末尾数单位,如123456从6开始数,个十百千万十万,所以他被读作 -》拾贰万叁仟肆佰伍拾陆元整。如下图可以知道,每四个单位就是一个组,什么意思呢,后四位的单位是元、拾、佰、仟,如果再有四位,就是万、拾、佰、仟,再有四位就是亿、拾、佰、仟,所以单位存储到字符中我们分为三组,如上所说的四组。
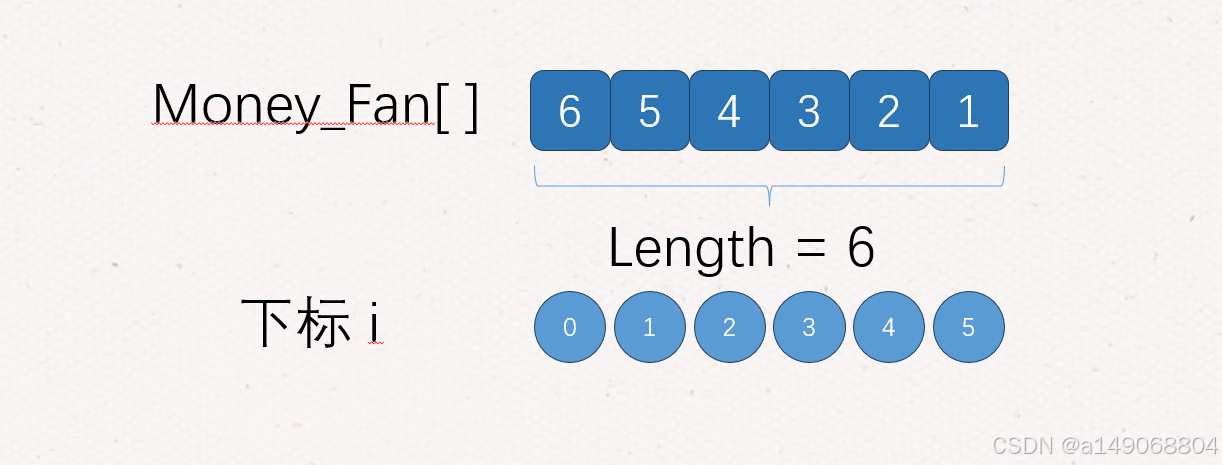
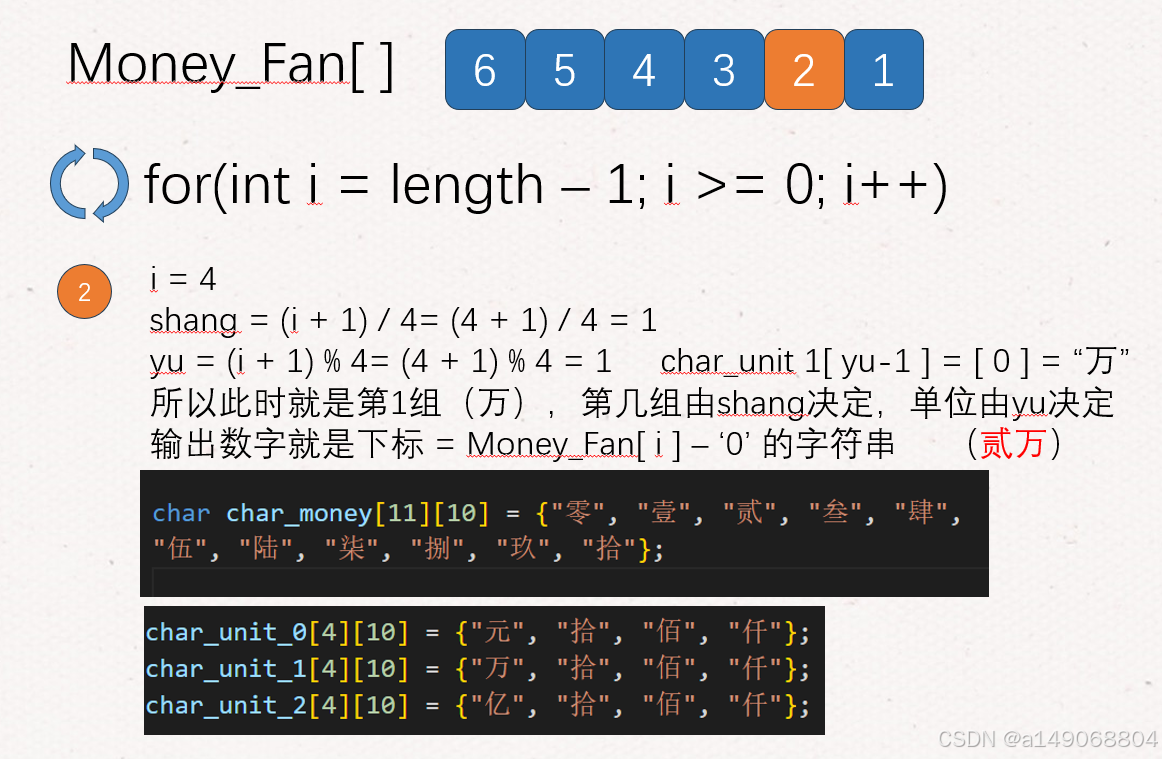
5、那么我们如何判断是第几组呢,是什么单位呢,很简单,我们需要将他倒序存储,当前遍历到的下标+1除以4就是第几组,也就是元、还是万、还是亿,下标+1取余4就是什么单位了,如下图

6、这是主要思路,一些比较细枝末节的输出要求如没有小数部分输出整,如对于壹拾不输出壹直接输出拾等等不再赘述
7、对于小数部分就比较简单了,直接判断有无小数部分,按照上面的方法输出对应的中文字体和单位即可
8、自测输入

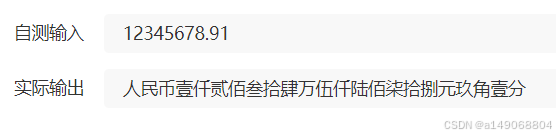

#include <stdio.h>
#include <string.h>
char char_money[11][10] = {"零", "壹", "贰", "叁", "肆", "伍", "陆", "柒", "捌", "玖", "拾"};
char char_unit_0[4][10] = {"元", "拾", "佰", "仟"};
char char_unit_1[4][10] = {"万", "拾", "佰", "仟"};
char char_unit_2[4][10] = {"亿", "拾", "佰", "仟"};
char char_unit_3[2][10] = {"角", "分"};
int main() {
char money[20];
char money_FanInt[20];
char money_Float[5];
char printf_money[50][10];
scanf("%s", money);
char ch;
int length = strlen(money);
int length_int = 0;
int length_float = 0;
int q = 0;
int shang = 4;
int yu = 0;
for (int i = 0; i < length; i++) { // 获取整数的长度和小数的长度
if (q == 0 && (money[i] != '.')) {
length_int++;
} else if (money[i] == '.') {
q++;
} else if (q == 1) {
length_float++;
}
}
q = 0;
for (int i = length_int - 1; i >= 0; i--) { // 得到整数部分倒序字符串
money_FanInt[q] = money[i];
q++;
}
if (length_float > 0) { // 得到小数部分字符串
q = 0;
for (int i = length_int + 1; i < length; i++) {
money_Float[q] = money[i];
q++;
}
}
printf("人民币");
if (length_int == 1 && money_FanInt[0] == '0') { // 特殊情况如0.38,不输出整数部分
} else {
for (int i = length_int - 1; i >= 0; i--) {
shang = (i + 1) / 4;
yu = (i + 1) % 4;
if (yu == 0) {
yu = 4;
}
int index = money_FanInt[i] - '0';
if (index == 1 && yu == 2); // 样例中1010要求输出壹仟零拾元整,不是壹仟零壹拾元整,所以特殊情况单独判断
else if(index == 0 && i == 0) // 当个位数是0,如310,叁佰壹拾元
{
printf("元");
}
else {
printf("%s", char_money[index]);
}
if (index == 0)
{}
else {
if (shang == 0) {
printf("%s", char_unit_0[yu - 1]);
} else if (shang == 1) {
printf("%s", char_unit_1[yu - 1]);
} else if (shang == 2) {
printf("%s", char_unit_2[yu - 1]);
}
}
}
}
if(length_float == 0 || (length_float == 1&& money_Float[0] == '0') || (length_float == 2 && money_Float[0] == '0' && money_Float[1] == '0'))
{
printf("整");
}
else if (length_float == 1) {
int index = money_Float[0] - '0';
printf("%s%s", char_money[index], char_unit_3[0]);
} else if (length_float == 2) {
int index = money_Float[0] - '0';
if (index == 0) {
} else {
{
printf("%s%s", char_money[index], char_unit_3[0]);
}
}
index = money_Float[1] - '0';
if(index == 0)
{
}
else {
printf("%s%s", char_money[index], char_unit_3[1]);
}
}
return 0;
}
























 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









