



一种用于设计对工艺偏差敏感的纳米级超低功耗求和电路的电流模式电路级技术
摘要
高性能‐超低功耗电子器件的巨大需求推动了能够降低传播延迟(tp)和减少功耗(PWR)的电路结构的发展。MOS电流模式逻辑(MCML)结构作为一种有前景的逻辑结构,能够在可接受的功耗水平下提供高工作速度。本文提出了一种采用负载控制器电路的MCML全加器,并在超阈值区和亚阈值区下,从多个设计指标方面将MCML全加器与混合CMOS全加器进行了比较。带有负载控制器的MCML拓扑在超阈值区具有高工作速度和低功耗的特点。相同的电路结构在亚阈值区工作时,相比其混合CMOS对应电路,也表现出更高的工作速度和超低功耗。功耗分析表明,基于MCML的全加器相比混合CMOS结构更加鲁棒。特别是在16纳米工艺节点下,MCML全加器设计在超阈值(亚阈值)工作区域实现了3.77×(2.38×)倍的传播延迟改进、10.43×(3.45×)倍的平均功耗降低、39.43×(8.21×)倍更低的功耗‐延迟积(PDP)以及149.07×(19.55×)倍的能延积(EDP)提升。上述结果还使用台积电(TSMC)行业标准的0.18‐μm工艺模型参数进行了验证,在MCML和混合CMOS全加器的设计指标中观察到了类似的趋势。
1 引言
许多新兴应用,如助听器、iPod,需要超低功耗(ULP)工作以延长电池寿命。便携式电子设备在更小的面积内集成了多种功能,但与此同时,电池寿命的要求变得更加严苛。由于这些设备的高功耗,消费电子行业正面临问题。在这方面,电子设备中的功耗是确保这些时尚应用正常功能和成功运行最紧迫的问题。
因此,电池寿命短和电子电路的开关速度成为这些设备进一步发展的主要限制因素(Allam和Elmasry 2001)。在便携式电子行业中,任何在降低功耗的同时提供高工作速度的技术都是最受青睐的。
亚阈值区由于降低了VDD,被认为是能效较高的工作区域。与超阈值区中的强反型层不同,亚阈值区存在弱反型区。弱反型层所需的电荷量远小于建立表面电势所需的电荷量。由于亚阈值电路工作时使用低电源电压,因此电路可实现最小能耗。正因如此,亚阈值工作已成为超低功耗(ULP)研究的热门方向。
在实际应用环境中最常使用的电路之一是全加器电路。全加器存在于众多算术电路的核心电路拓扑中,例如减法器、乘法器等(Chang 等人 2005;Ko 等人 1995;Kwon 等人 2000;Shams 等人 2002;Song 和 De Micheli 1991;Doka‐nia 和 Islam 2015)。行波进位加法器、超前进位加法器、保留进位加法器以及阵列乘法器是广泛使用全加器的最常见计算机算术应用。在这些链式结构的应用中,从“进位输入”到“进位输出”的进位传播在全加器电路中至关重要。这要求快速生成“进位输出”信号,否则将导致更高的传播延迟。
降低电压摆幅显著减少了电子电路的功耗。过去的研究为此提供了证据。与标准全摆幅直流‐直流转换器相比,低摆幅直流‐直流转换器表现出更低的(27.9%)功耗(Kur‐sun et al. 2004; Audzevich et al. 2014)。此外,(Liu and Kursun 2006; Rjoub et al. 1998; Kursun and Friedman 2002, 2005)中提出了多种通过降低电压摆幅来减少动态逻辑电路功耗的技术。
较大的电压摆幅可以拓宽两个稳定工作点之间的距离,从而在逻辑和存储应用中提供更优的噪声容限,但代价是高功耗(Chung et al. 2007)。如前所述,对于超低功耗应用而言,高功耗是不希望的,延长电池寿命和实现高速工作才是首要关注的问题。本文探索了一种调控电压摆幅的方法,而电压摆幅在传播延迟的估算中具有重要意义。本文提出了一种基于MOS电流模式逻辑(MCML)的全加器,该全加器由所提出的负载控制器进行偏置。基于MCML的电路相较于其混合CMOS对应电路具有显著更低的传播延迟(Goel et al. 2006)。所提出的设计成功地将电压摆幅降至足够低的程度,完全抵消了基于MCML的电路所表现出的高功耗。
为了验证结果,使用亚利桑那州立大学(ASU)纳米级集成与建模(NIMO)小组开发的16纳米预测技术模型(16‐nm PTM)在SPICE中进行了大量仿真(Predictive Technology Model. 2008),随后采用台积电(TSMC)工业标准的0.18‐μm工艺模型参数进行验证。
本文其余部分组织如下。第2节描述“负载控制器”。基于混合CMOS和MCML的全加器设计在第3节中简要说明。第4节解释了仿真设置。第5节提出了基于混合CMOS和MCML的全加器设计的性能比较。第6节简要介绍了结果的验证。最后,结论在最后一节中给出。
2 负载控制器
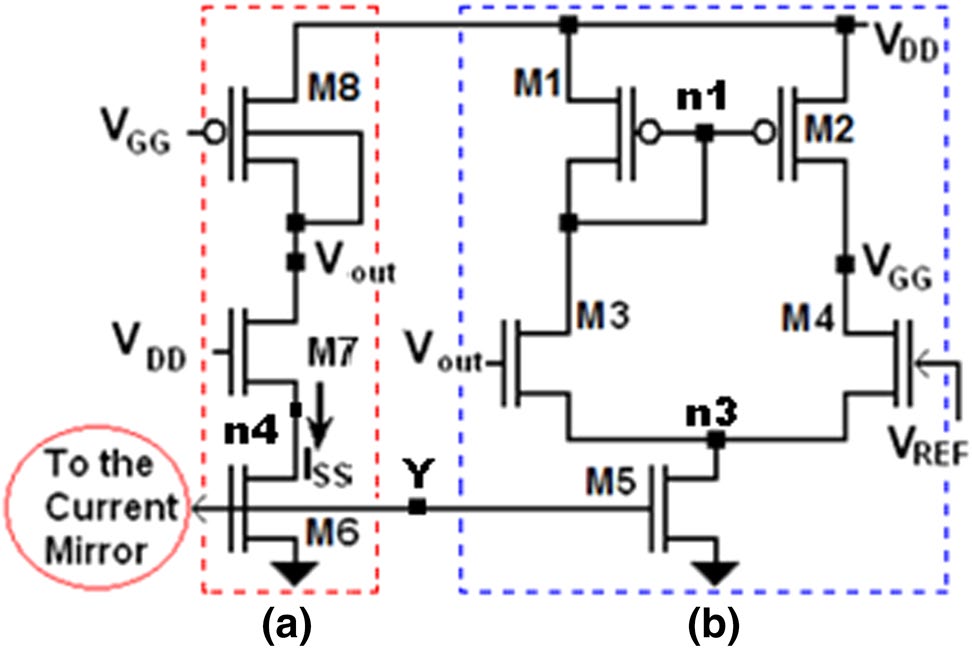
通过降低MCML电路输出节点的电压摆幅,可以减少动态开关功耗。本文提出了一种负载控制器(LC)电路,该电路由复制偏置电路和电压摆幅控制器(VSC)组成(见图1)。电压摆幅控制器向复制偏置电路提供反馈,以实现期望的电压摆幅。电压摆幅(ΔV)定义为LC的复制偏置电路中电源电压(VDD)与负载晶体管(M7/M8)的漏极电压之间的电压差。所提出的LC用于偏置第3节中描述的MCML全加器电路。
负载控制器采用最小尺寸器件实现,即所有MOSFET的沟道长度均为16纳米,其中MOSFET M1、M2和M8的宽度为32纳米,其余所有MOSFET(M3/4/5/6/7)的宽度为16纳米。
VSC将VREF作为输入,并产生一个电压VGG,以帮助生成所需的输出电压摆幅。只需改变VREF的值,即可控制电压摆幅的幅度。该技术有助于减少对设定LC复制偏置电路中负载晶体管M8适当电阻率及相应电压降所需精确值VGG的估计。
该电路提供的电压摆幅(ΔV)可以通过从电源电压(VDD)中减去参考电压(VREF)来计算。数学上,
(1) V = VDD − VREF

电压摆幅控制器的主要目的是提供一个VGG,使得M7/M8的漏极电压等于目标值VREF,从而获得VDROP = RP × ISS = VDD − VREF,进而将Rp(负载晶体管M8的电阻)设置为(VDD − VREF)/ISS。
由于温度变化对所有器件的影响相同,因此该机制对温度变化不敏感。实现这种鲁棒性的机制将在下一段中进行解释。
在复制偏置电路中,pMOS (M8) 表示负载晶体管,nMOS (M7) 是 MCML 全加器下拉网络的复制等效电路(如下一节中稍后所示的图 3和 4)。电流镜用于提供恒定电流 ISS。单级运算放大器(差分对)用于提供负反馈,以将 VGG维持在期望的水平。
最初,在负载控制电路的电压摆幅控制器中设置一个期望的VREF。M7/M8的漏极电压在VREF附近波动,并出现以下两种情况:
- 当M7/M8的漏极电压(即VOUT)小于VREF时,差分对的输出即VGG将导致负载晶体管M8的电阻率降低。这将表现为负载晶体管M8上的压降减小,并且M7/M8的漏极电压(即VOUT)将更接近于VREF。因此,M7/M8的漏极电压将持续增加,直到达到某一点,使得M7/M8的漏极电压(即VOUT)超过VREF。
- 当M7/M8的漏极电压(即VOUT)大于VREF时,差分对的输出即VGG将呈现较高的正电压,导致负载晶体管M8的电阻率增加。这将表现为负载晶体管M8上的压降增大,并且M7/M8的漏极电压(即VOUT)会降低至达到VREF。因此,M7/M8的漏极电压(即VOUT)将持续降低,直到达到某一点,使得M7/M8的漏极电压(即VOUT)低于VREF。
因此,VSC应用上述机制产生一个VGG,有助于根据应用需求生成所需的电压摆幅。基于MCML的全加器采用所提出的负载控制器实现,该控制器调节MCML全加器的负载电阻,从而将电压摆幅维持在期望的水平。这使得MCML全加器在第5.4节中观察到的PVT(工艺、电压和温度)变化下仍具有鲁棒性。
3 提出的电路——进位和和函数
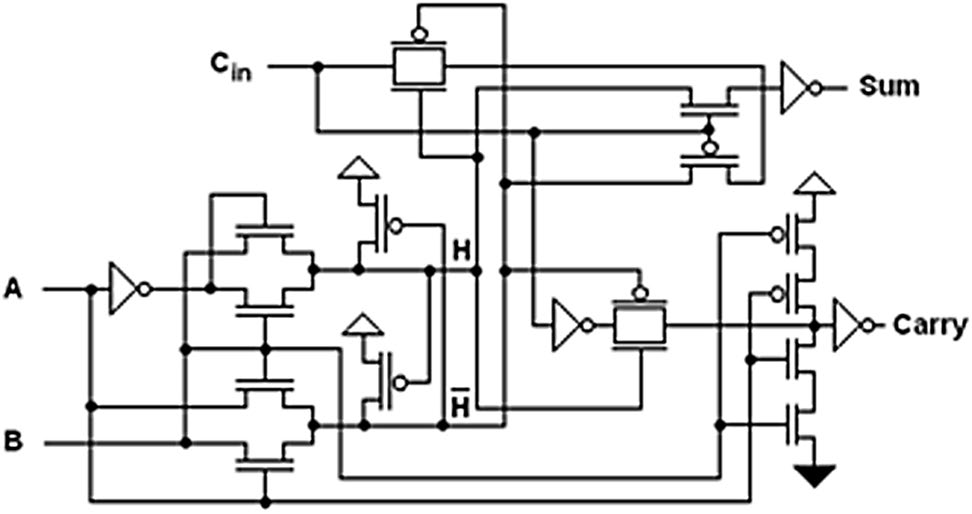
用于与所提出的MCML全加器进行比较的混合CMOS全加器如图 2 所示(Goel 等,2006)。由于存在输出静态反相器,该电路可提供完整的电压摆幅和良好的驱动能力。

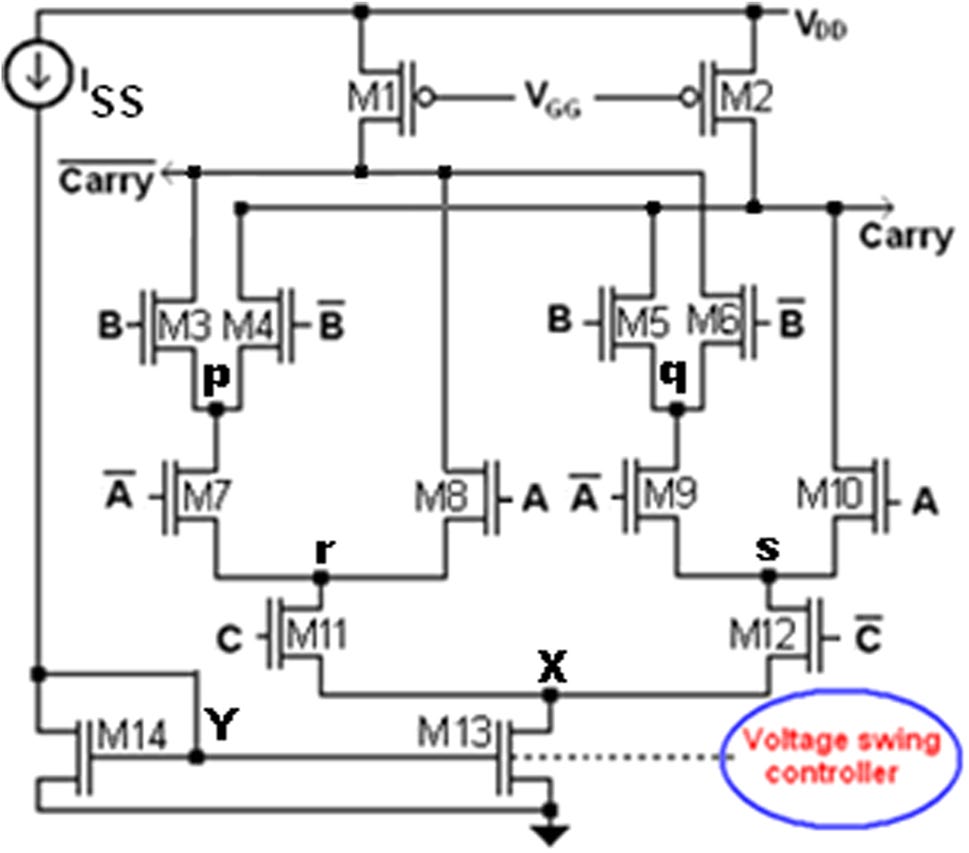
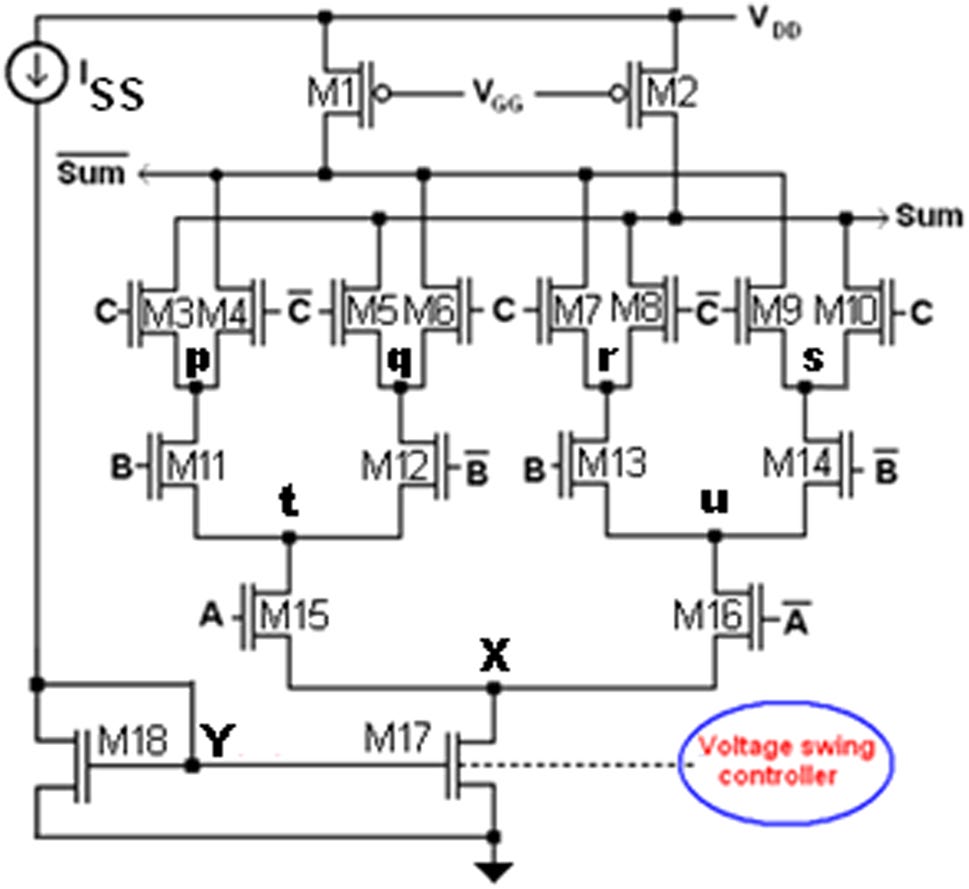
然而,由于存在大量内部节点和静态反相器,与静态CMOS和TG拓扑等其他CMOS全加器相比,其功耗更高,如(Islam和Hassan 2011)所示。进位和和函数的所提出的MCML全加器电路分别如图3和4所示。该电路采用最小尺寸器件实现,即所有MOSFET的沟道长度均为16纳米,M1和M2的宽度为32纳米,其余所有MOSFET(M3–M16)的宽度为16纳米。类似地,所提出的MCML全加器的和函数也采用最小尺寸器件实现,即所有MOSFET的沟道长度均为16纳米,M1和M2的宽度为32纳米,其余所有MOSFET(M3–M18)的宽度为16纳米。
该电路继承了MCML拓扑的高工作速度特性,由于其具有低电压摆幅,因而传播延迟较小。MCML电路设计方法固有的较高功耗,可通过合理调节电压摆幅以降低功耗来加以平衡。
3.1 MCML全加器——通用工作原理
MCML电路需要输入及其互补信号以实现其功能,如图 3、4和5所示。
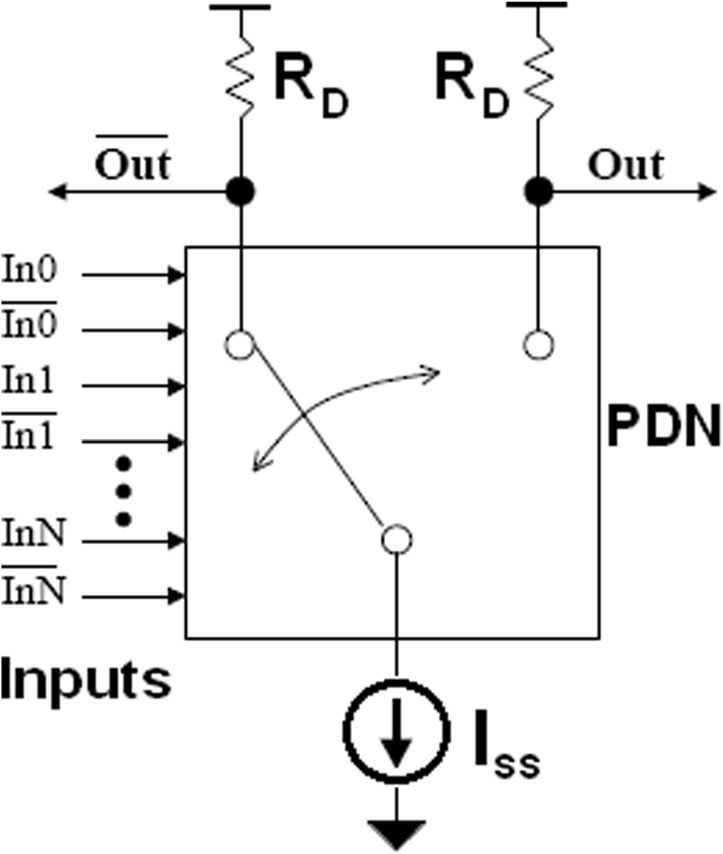
MCML拓扑的基本功能可以通过研究其三个主要组成部分来了解——它们是上拉电阻(RD)(或上拉MOS的沟道电阻)、下拉网络(PDN)和偏置电流(ISS)。上拉网络也可以通过工作在线性区的pMOS晶体管来实现。逻辑功能由连接在电阻和电流源之间的逻辑块(PDN)实现。参考电流ISS通过电流镜(电流源)经由其二极管连接的输入晶体管M14和M13(在进位函数发生器中)、M17(在和函数发生器中)、M5(在电压摆幅控制器中)以及M6(在复制偏置电路中)进行分配。图3和4中的虚线表示各电流源(M13/17/5/6)的栅极连接在一起,以便在每个单元中复制相同大小的偏置电流。此外,在设计多位加法器时,可以复制和与进位位单元,并将它们所有电流源的栅极连接在一起,并接到一个单一的负载控制器。PDN是一个差分对,同时实现真实逻辑功能及其补码。PDN网络根据所实现的逻辑功能,从其中一个上拉电阻(pMOS晶体管的沟道电阻,其栅极由LC中的VGG 偏置,如图3和4所示)汲取电流ISS。偏置电流(ISS)仅流过那些在特定高输入向量下其PDN导通的上拉电阻(pMOS晶体管),从而产生相等的电压降到 ΔV = ISS × RD在该支路以及对应于该电阻(pMOS晶体管)的输出节点(Out 在图 5 的情况下,以及图 进位 和 和 在图 3 和 4中分别对应的输出节点)处的电位低于 VDD达 ΔV。由于没有电流流过另一个上拉电阻(pMOS晶体管),对应于该电阻(pMOS晶体管)的输出节点(在图5中为Out,在图3和图4中分别为进位和和)被上拉至VDD。
因此,其中一个输出节点(在图5中为Out,在图3和图4中分别为进位和和)的电压为VDD,而另一个输出节点(在图5中为Out,在图3和图4中分别为进位和和)的电压为VDD − ISS × RD。因此,输出节点处的逻辑摆幅为Out – Out,其值由下式给出
(2) Out − Out = VDD − (VDD − ISSRD) = RD × ISS = ΔV
因此,输出(进位和和)及其补码输出(进位和和)被同时生成,从而避免了使用反相器的需求。
3.2 亚阈值—低电压摆幅电路
长期以来人们已经认识到,对于大多数逻辑电路家族而言,最小能耗点出现在亚阈值区,而最小能量的值由亚阈值漏电流决定(Roy 等人 2003;Zhai 等人 2006;Pu 等人2009;Kwong 等人 2008;Jocke 等人 2009;Wang 和 Chandrakasan 2004;Gubbi 和 Amrutur 2015)。尽管工作在亚阈值区的电路速度可能会显著降低,但可以在需要时应用适当的架构方法以满足速度约束。本研究针对设计全加器电路提出了一种新的架构方法,以实现较短的传播延迟并降低功耗。该目标通过在亚阈值区使用 MOS电流模式逻辑(MCML)并以尽可能低的电压摆幅来设计全加器电路实现。换句话说,若以适当的电压摆幅进行设计,则工作在亚阈值区的MCML全加器电路能够以最低可能的功耗提供最高可能的工作频率。因此,我们设计策略的关键在于选择 ΔV。这是通过使用图 1 所示的LC实现的。
4 仿真设置
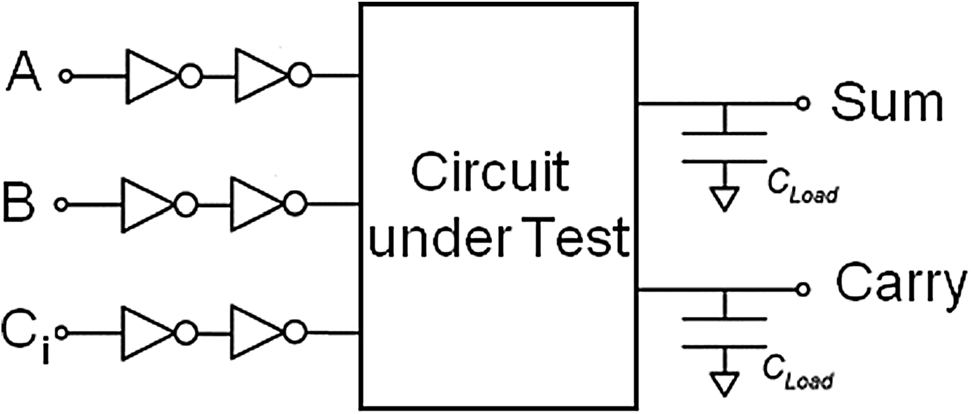
通过为测试电路的所有输入提供输入缓冲器,实现了更真实的仿真方法。输出端子加载了LOAD为4皮法的负载电容(CLOAD)。所使用的通用仿真测试平台如图 6 所示。
被测电路(即混合CMOS和MCML全加器)的性能通过传播延迟、平均功耗、功耗‐延迟积和能量延迟积等设计指标进行评估。
5 仿真结果与讨论
本节估算所提出的MCML全加器电路的tp、PWR、PDP 和 EDP,并将估算结果与混合CMOS全加器电路进行比较(见图 2、3、4)。这些设计指标在超阈值和亚阈值工作区均进行了估算。以下各小节将讨论旨在实现最小延迟、功耗、PDP和EDP的全加器之间的比较。
5.1 传播延迟分析
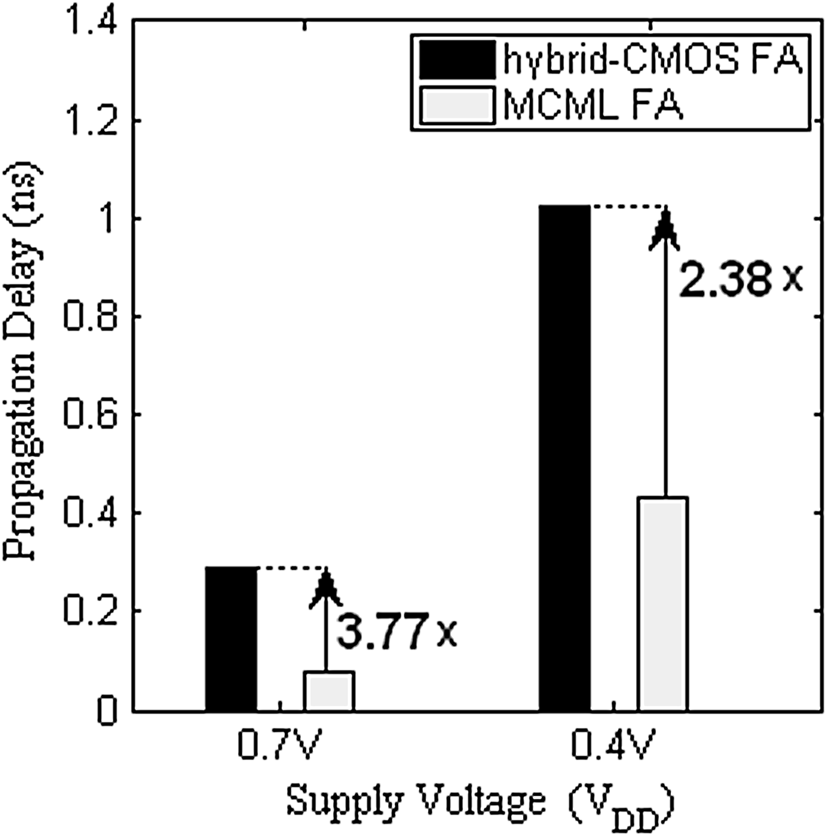
传播延迟在超阈值和亚阈值区的工作区域均进行了估算。所提出的MCML全加器设计在超阈值(亚阈值)区的延迟比混合CMOS全加器设计缩短了2.38×(3.77×),如表1 和 2所示,并在图7中绘制。当从超阈值区切换到亚阈值区时,电路的传播延迟增加。从表1 和 2中的仿真结果可以明显看出,混合CMOS和MCML全加器在亚阈值区的传播延迟均有所增加。但MCML全加器无论是在超阈值区还是亚阈值区,其延迟均小于混合CMOS全加器。
MCML电路的延迟是ΔV、ISS 和 CL 的函数,表示为(Musicer 2002)。
(3) tP, MCML = RC = (V / ISS) × C
(4) C = CGD,n + CDB,n + CGD,p + CDB,p + CL
其中
NMOS电容 CGD,n约等于栅极和漏极之间的重叠电容,其定义为(Alioto 和 Palumbo 2003)
(5) CGD,n = Cgd0 Weff
以及CDB,n和CDB,p 是结电容。CGD,p 是由于重叠和本征电容CGD,p,int共同作用的结果,即
(6) CGD,p = Cgd0 Weff,p + CGD,p,int
其中,
(7) CGD, p ,int = ∂QD / ∂VD = (3/4) Abulk W LCox
参数 Abulk 已在(Alioto 和 Palumbo 2003)中适当定义。最后,CL 是每个输出节点上的负载电容,主要由扇出门的门电路电容、输出晶体管的漏极扩散电容以及互连电容组成。
类似地,混合CMOS加法器的传播延迟可以建模为
(8) tP, CMOS = R’C = (VDD / ID) × C
因此,可以看出
(10) tP, MCML / tP, CMOS ∝ V / VDD ∝ (VDD − VREF) / VDD
这证明了由于电压摆幅减小,MCML全加器的工作速度更快。对于高速应用,电压摆幅 ΔV 可以比电源电压更小,通常比 VDD 低两到十倍。
表 1 和 2 中报告的仿真结果与公式(3)和(8)中给出的MCML和CMOS‐混合全加器电路的传播延迟模型一致。
5.2 平均功耗分析
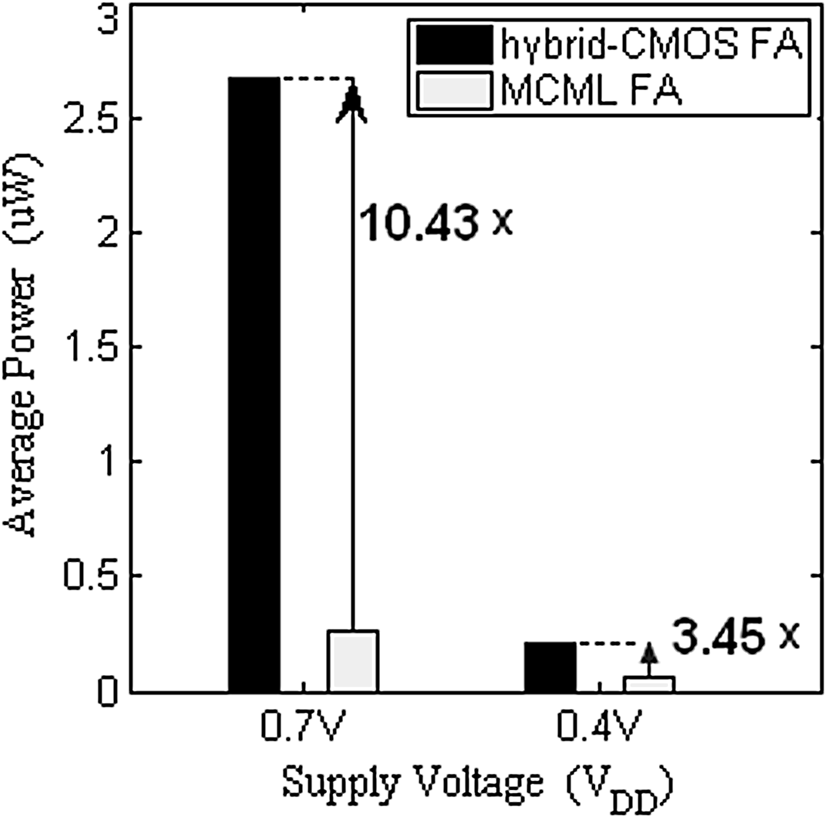
平均功耗在超阈值和亚阈值工作区域均进行了估算。所提出的设计在超阈值区域的平均功耗节省了10.43×(3.45×)。(亚阈值)区域,如表1和2所示。这些数据也在图8中进行了绘图,以便清晰地进行比较。传播延迟降低且功耗低是本文所提出设计的重要成果,使其成为极低功耗应用的理想选择。
5.3 功耗延迟积和能量延迟积分析
PDP(= Pav g × tp,其中 Pav g 为平均功耗)在超阈值和亚阈值区的工作中均进行了估算。
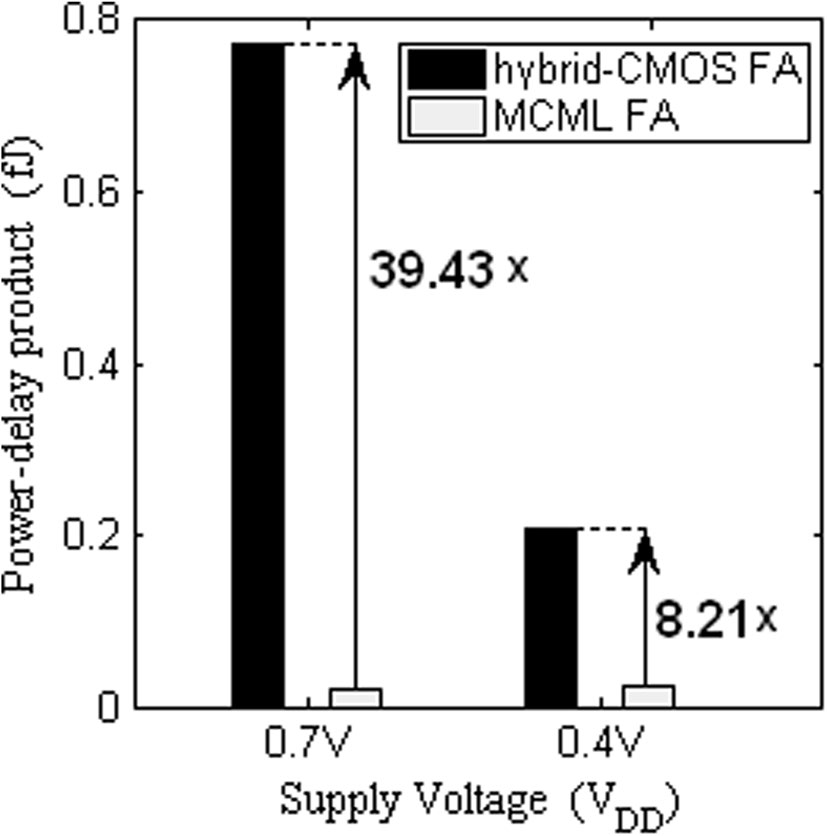
所提出的 MCML 全加器设计在超阈值(亚阈值)区的PDP 比混合CMOS全加器电路降低了 39.43× (8.21×)。如表 1 和 2 所示。为了便于比较,这些数据也在图 9 中进行了绘制。
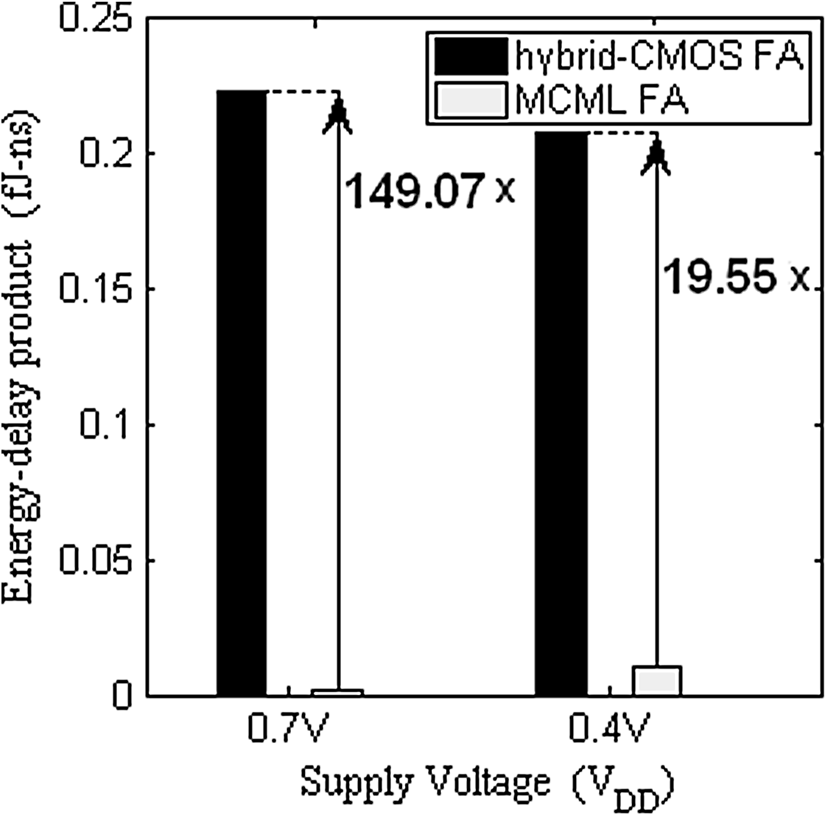
PDP 是一种衡量门电路开关所需能量的质量指标,这无疑是一个重要特性。通过降低电源电压并保持门电路的功能性,PDP 可以任意降低,但这会显著牺牲性能。PDP 并未将性能和能量的度量结合起来,因此,更好的设计指标应同时包含性能和能量的度量。能量延迟积(EDP)正是如此。因此,本文将 EDP 与 PDP 一并作为全加器单元的设计指标。所提出的设计在超阈值(亚阈值)区域实现了 149.07×(19.55×) 更低的 EDP,如表 1 和 2 所示。相同结果也在图 10 中进行了绘图,以便清晰地进行比较。
MCML全加器在超阈值和亚阈值区表现出更低的PDP和EDP,表明其优于混合CMOS全加器。因此,本文提出的MCML全加器适用于高速和超低功耗应用。
1位MCML全加器单元的PDP和EDP可表示为(Musicer 2002)。
(11) PDPMCML = PMCML × tp,MCML = VDDISS × (V / ISS) C
(12) PDPMCML = VDDΔVC
(13) EDPMCML = PDPMCML × tp,MCML
(14) EDPMCML = (V² VDD C²) / ISS
类似地,1位混合CMOS全加器的PDP和EDP表达式如下所示
(15) PDPHybrid = PHybrid × tp,Hybrid = CV²DD
(16) EDP Hybrid = PDP Hybrid × tp,Hybrid
(17) EDP Hybrid = C² V³DD / [μN Cox W / 2L (VDD − Vth)² (1 + θ(VDD − Vth))]
从(11)–(17)可以推断出
(18) PDP MCML / PDP Hybrid ∝ V / VDD ∝ (VDD − VREF) / VDD
and
(19) EDPMCML / EDP Hybrid ∝ (ΔV / VDD)² ∝ ((VDD − VREF) / VDD)²
5.4 鲁棒性分析
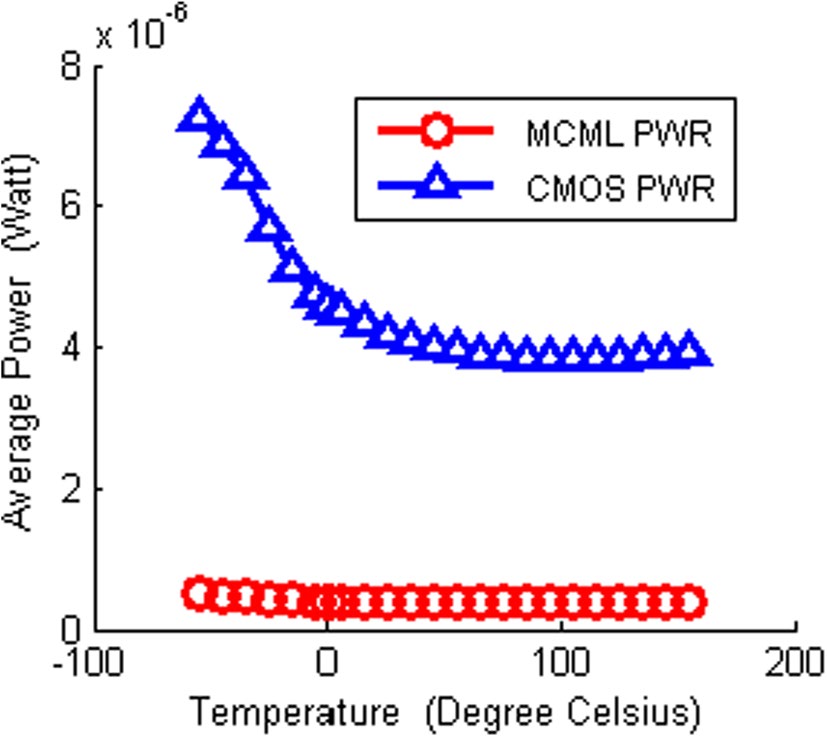
对CMOS和MCML全加器电路在温度变化下的平均功耗进行了分析,结果列于表 3 中。为了便于可视化,结果也绘制在图 12 中。
可以观察到,MCML全加器在室温下比混合CMOS全加器的平均功耗低10.83 × 。它还表现出对温度变化引起的平均功耗变化较小,证明了其鲁棒性。这归因于基于MCML的全加器采用了所提出的LC,该LC控制了MCML全加器的负载电阻,从而将电压摆幅维持在期望的水平内。这使得MCML全加器对PVT变化具有鲁棒性。
如图12所示的混合CMOS全加器电路的平均耗散功率在低温和高温范围内的变化可分别进行研究,因为电路在较低和较高温度值下表现出不同的特性。具体如下:
- 较低温度值(−55至100 °C):在此温度范围内,随着温度升高,平均功耗显著下降。这种行为主要归因于迁移率对温度的依赖性,其关系由以下公式给出:
(21) μ = qt / m∗
其中 μ为载流子迁移率,q 为载流子电荷,t 为平均自由时间,m*为载流子的电导有效质量。
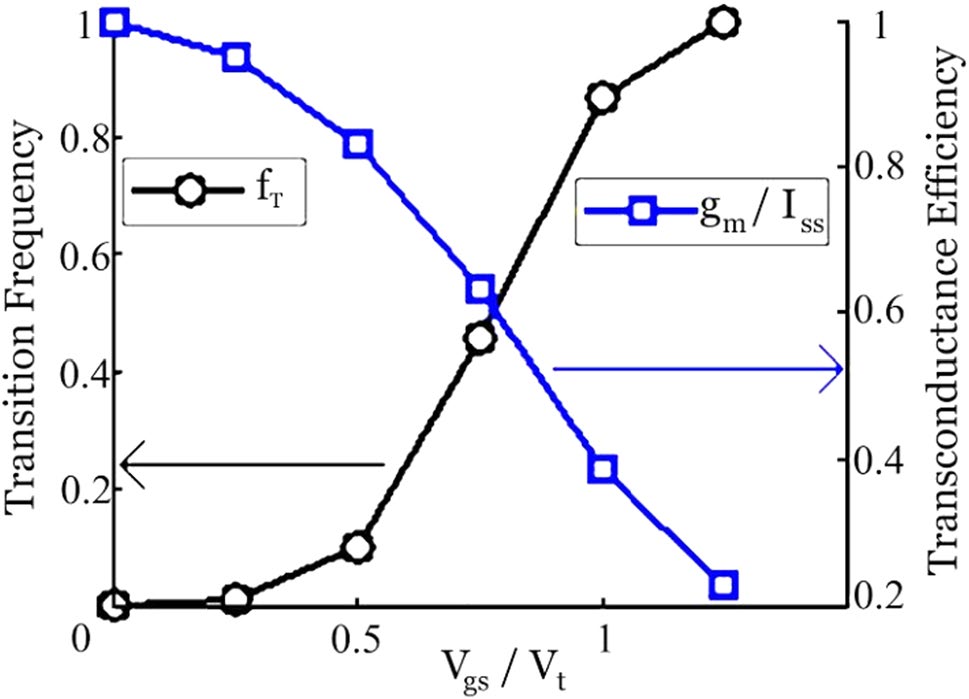
随着温度升高,由于激发载流子的碰撞增加,平均自由时间减少,因此载流子的迁移率降低。因此,由于迁移率降低,流经器件的电流也随之减少,如图 13 所示(Zhao 和 Jiang 2011)。通过在感兴趣的时间周期内对瞬时功率进行积分,可以求得消耗的平均功率。
(22) Pavg = (1/T) ∫₀ᵀ p(t)dt = (VDD/T) ∫₀ᵀ i(t)dt
其中p(t)是从电源电压VDD汲取的瞬时功率,i(t)是在0到T的时间间隔内从VDD汲取的电流。
由于平均功耗与流经器件的电流成正比,因此温度升高导致电流减小,从而引起平均耗散功率降低,如表3 和 图 12所示。
- 较高温度值(101–155 °C):随着温度升高,迁移率几乎保持不变(见图 13)(Zhao 和 Jiang 2011),因此器件电流几乎不随温度变化。这表明在高温值下平均功耗几乎恒定。我们在表3中报告并绘制在图12中的观察结果证实了这一事实。
6 验证
我们通过使用台积电的行业标准0.18‐μm技术模型参数进行仿真,验证了本工作基于16纳米预测技术模型的仿真结果。晶体管的尺寸设置与16纳米技术节点的情况相同,并且对两个全加器单元估算了相同的设计指标。结果列于表4中。可以看出,在速度和功耗方面均呈现出相似的趋势。这验证了所提出设计在未来技术(如16纳米)中的可扩展性。
6.1 工艺角分析
针对MCML加法器考虑的所有设计指标均在5个工艺角(即NN(标称)、SS(慢速)、FF(快速)、FS和SF)下进行估算。这些工艺角分别对应于快速或慢速NMOS与PMOS晶体管的组合。慢速器件意味着更厚的栅氧化层、更高的器件阈值以及降低的载流子迁移率,这导致在相同栅极驱动下漏极电流减小。相反,快速器件表示更薄的栅氧化层、更低的器件阈值降低和载流子迁移率增加,导致在相同栅极驱动下漏极电流增大。众所周知,慢速角对应较长的延迟,而快速角对应较高的功耗。结果如表5所示。
可以看出,MCML全加器即使在SS角条件下也提供了更低的传播延迟(3.74 ns),相比之下,混合CMOS全加器在标称工艺角下的传播延迟为(3.76 ns)(见表4)。此外,MCML全加器在FF角下消耗的功耗(7.22 μW)也≅3×低于混合CMOS加法器在标称工艺角下消耗的功耗(20.98 μW)。所有这些结果证明了我们设计具有优越性的主张。
6.2 版图设计和寄生参数提取
所提出的全加器单元的所有组件(负载控制器、和与进位函数发生器)的版图均采用180纳米逻辑设计规则生成,如图14所示。此外,表6列出了所提出的MCML全加器单元所有节点提取出的寄生电容。这些寄生电容在估算所提出设计的设计指标时被使用。
6.3 MCML全加器单元的噪声性能
除了更高的速度外,MCML全加器由于采用恒定偏置电流工作,与其混合CMOS counterpart(夏皮罗 A 和弗里德曼 2014)相比,产生的同时开关(SS)噪声极小。此外,所产生的SS噪声与开关状态(即空闲和过渡或活动状态)无关。这导致整体片上噪声的降低(唐和弗里德曼 2002)。为了验证这一事实,采用了如图 15 所示的仿真设置,并估算了全加器电路因其开关活动在电源网络上引起的噪声影响。电源网络集总模型的电阻、电感和电容分量基于ITRS指南(ITRS 2013,访问于2016年3月3日)确定。结果列于表 7 中。
如所观察,与混合CMOS全加器相比,所提出的MCML全加器产生的噪声降低了 ≅14× 。换句话说,我们的设计提供了有利于混合信号电路设计的低噪声环境。因此,该设计适用于高灵敏度模拟电路与数字和存储电路集成的应用场景。
7 结论
本文提出了一种基于单级运算放大器的负载控制器,用于偏置所提出的基于MCML的全加器电路。
本研究成功地从多个设计指标角度对基于CMOS和MCML的全加器电路进行了分析。在16纳米工艺节点下,基于MCML的全加器表现出更低的传播延迟、平均功耗、PDP和EDP。此外,其在温度变化条件下展现出较小的平均功耗波动,证明了其较强的鲁棒性。
通过采用台积电工业标准的0.18‐μm工艺模型参数,并结合寄生参数提取,对结果进行了验证。同时,比较了两种加法器单元的噪声性能,结果表明,与混合CMOS全加器相比,MCML全加器具有更优的噪声性能。因此,所提出的MCML全加器结合负载控制器,是高速亚阈值和超阈值操作的理想选择。
| 设计指标 | CMOS全加器 | MCML全加器 |
|---|---|---|
| tP (ns) | 0.2893 (3.77) | 0.0767 |
| PWR (微瓦) | 2.6713 (10.43) | 0.2562 |
| PDP (飞焦) | 0.7729 (39.43) | 0.0196 |
| EDP (飞焦‐纳秒) | 0.2236 (149.07) | 0.0015 |
表1 超阈值区CMOS与MCML全加器电路的设计指标比较
| 设计指标 | CMOS全加器 | MCML全加器 |
|---|---|---|
| tP(ns) | 1.0257 (2.38) | 0.4314 |
| PWR (微瓦) | 0.2026 (3.45) | 0.0587 |
| PDP (飞焦) | 0.2078 (8.21) | 0.0253 |
| EDP (飞焦‐纳秒) | 0.2131 (19.55) | 0.0109 |
表2 亚阈值区CMOS与MCML全加器电路设计指标比较
| 温度(°C) | CMOS全加器功耗 (µW) | MCML全加器功耗 (µW) |
|---|---|---|
| −55 | 7.2442 | 0.4949 |
| −45 | 6.8876 | 0.4654 |
| −35 | 6.4292 | 0.4535 |
| −25 | 5.6945 | 0.4258 |
| −15 | 5.0911 | 0.4106 |
| −05 | 4.7304 | 0.4008 |
| 00 | 4.5896 | 0.3970 |
| 05 | 4.4743 | 0.3938 |
| 15 | 4.3087 | 0.3888 |
| 25 | 4.1734 | 0.3852 |
| 35 | 4.0948 | 0.3824 |
| 45 | 3.9942 | 0.3801 |
| 55 | 3.9392 | 0.3786 |
| 65 | 3.8923 | 0.3775 |
| 75 | 3.8587 | 0.3767 |
| 85 | 3.8481 | 0.3760 |
| 95 | 3.8358 | 0.3757 |
| 105 | 3.8324 | 0.3756 |
| 115 | 3.8396 | 0.3757 |
| 125 | 3.8511 | 0.3759 |
| 135 | 3.8659 | 0.3763 |
| 145 | 3.8924 | 0.3768 |
| 155 | 3.9154 | 0.3774 |
表3 CMOS与MCML全加器电路在温度变化下的功耗比较
| 设计指标 | 混合CMOS 全加器 | MCML加法器单元 |
|---|---|---|
| tp(ns) | 3.76 | 2.24 |
| PWR (微瓦) | 20.98 | 1.92 |
| PDP (飞焦) | 78.88 | 4.30 |
| EDP (飞焦‐纳秒) | 296.60 | 9.63 |
表4 在标称工艺角下,使用台积电0.18‐μm工业标准工艺模型参数并提取寄生参数后,MCML全加器与其混合CMOS对应电路的设计指标比较
| 设计指标 (MCML) | NN | SS | FF | FS | SF |
|---|---|---|---|---|---|
| tP (ns) | 2.24 | 3.74 | 1.28 | 1.52 | 3.38 |
| PWR (微瓦) | 1.92 | 1.41 | 7.22 | 6.68 | 1.16 |
| PDP (飞焦) | 4.30 | 5.27 | 9.24 | 10.15 | 3.92 |
| EDP (飞焦‐纳秒) | 9.63 | 19.72 | 11.82 | 15.43 | 13.25 |
表5 采用台积电工业标准0.18‐μm工艺模型参数的MCML全加器电路在提取寄生参数后的工艺角分析仿真结果
| Node | 电容(飞法) | Node | 电容(飞法) |
|---|---|---|---|
| A | 0.6760 | p | 1.461 |
| Abar | 0.6848 | q | 1.461 |
| B | 0.6763 | r | 1.461 |
| Bbar | 0.6514 | s | 1.522 |
| C | 0.3378 | t | 1.417 |
| Cbar | 0.3904 | u | 1.524 |
| n1 | 1003.0 | VDD | 7.648 |
| n3 | 1.546 | VGG | 110 |
| n4 | 1.017 | VOUT | 3.101 |
| COUT | 3.725 | VREF | 0.3479 |
| COUT_bar1 | 3.690 | X | 1.536 |
| Sum | 4.148 | Y | 1.998 |
| Sum_bar | 4.191 | – | – |
表6 MCML全加器电路中各节点的寄生电容
| 电阻(欧姆) | 电感(纳亨) | 电容 (飞法) | MCML加法器 噪声(毫伏) | 混合CMOS加法器 噪声(毫伏) | 比率(CMOS/MCML) |
|---|---|---|---|---|---|
| 2 | 1 | 50 | 24.578 | 357.431 | 14.54 |
| 4 | 1 | 50 | 24.716 | 357.953 | 14.48 |
| 8 | 1 | 50 | 24.960 | 358.113 | 14.34 |
| 2 | 2 | 50 | 24.612 | 357.671 | 14.53 |
| 2 | 4 | 50 | 24.793 | 357.885 | 14.43 |
| 2 | 8 | 50 | 24.917 | 358.231 | 14.37 |
| 2 | 1 | 100 | 24.672 | 357.683 | 14.49 |
| 2 | 1 | 200 | 24.819 | 357.932 | 14.42 |
| 2 | 1 | 400 | 25.013 | 358.419 | 14.32 |
表7 基于台积电行业标准 0.18‐μm技术参数的 MCML与混合CMOS全加器 电路在电源网络上引起的噪声比较

















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









