



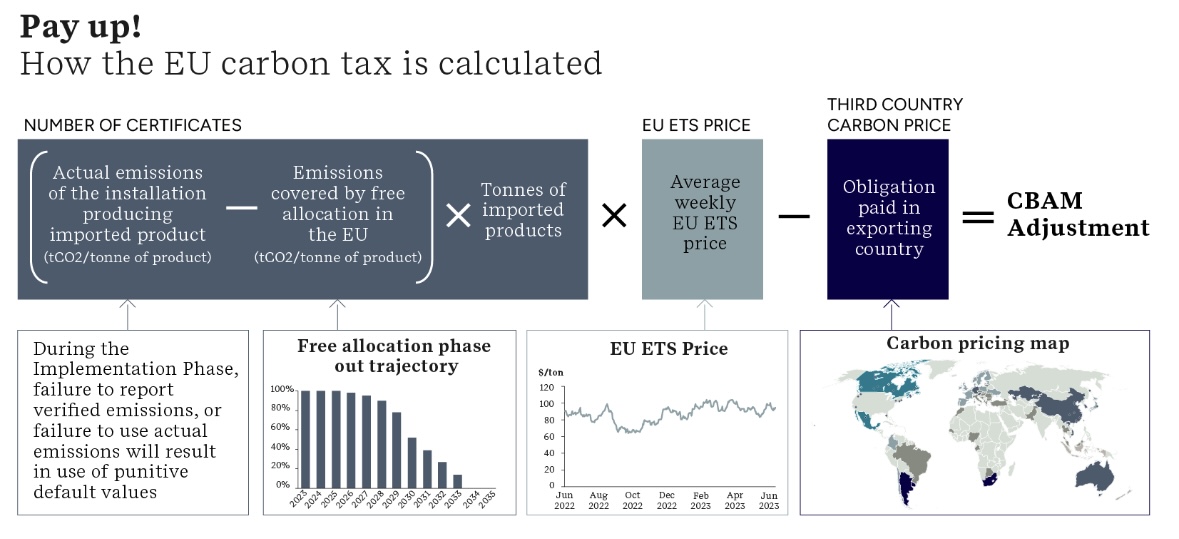
2026 年正式收费后,很多铝企业把精力放在“排放因子是多少”、“ETS成本多少”上。
但我最近与多个进口商、欧盟顾问沟通后发现:
欧盟现在最看重的,不是你排放高还是低,而是你的排放数据“是否一致(Consistency)”。
这正在成为 2026 年最被低估、但最致命的审核点。
① 什么叫“数据一致性”?为什么比排放因子更重要?
数据一致性指的是:
• 你的“原铝排放因子”是否与上游数据一致
• “再生铝比例”是否与回收链条一致
• “电力排放因子”是否与地区能源结构一致
• “工序排放”是否与材料路径一致
• “嵌入排放”是否与 MPV 填报一致
• “产品排放边界”是否与 MRV 方法一致
欧盟最常见的问题是:
数据能看,但看不通。
数据有数字,但没有逻辑。
这种情况会被直接判定为:
❌ 不可信
❌ 不符合MRV
❌ MPV无法通过
❌ ETS成本按“最高排放”计算
② 为什么“数据一致性”决定了企业的信誉度?
因为欧盟 CBAM 审核的是:
✔ 数据能不能复算
✔ 路径能不能对得上
✔ 供应链能不能解释
✔ 工序排放是否合逻辑
✔ 电力排放是否可验证
✔ 嵌入排放是否可追踪
✔ MRV + MPV 是否一致
任何一个环节不一致,就会被认为存在:
👉 数据造假
👉 排放虚报
👉 供应链不透明
👉 高风险供应商
这类企业在收费时代会被进口商直接替换。
③ 铝行业最容易出现“数据不一致”的五个环节
1)原铝 vs 再生铝 排放路径对不上
企业标“再生铝”,但无证据链,欧盟直接按原铝排放算。
2)电力排放因子的来源无法对应地区能源结构
国内常用的排放因子并不能自动适用于欧盟体系。
3)工序排放不拆分,数据结构不符合MPV
欧盟 MPV 不能接受“总排放”,必须拆为:
• 挤压排放
• 熔炼排放
• 加工排放
4)嵌入排放的计算逻辑前后不一致
明明上游排放因子高,但最终产品排放却异常低 → 审核直接拒绝。
5)供应链排放数据断层(最危险)
多个上游厂数据对不上,欧盟直接判为“不可信”。
④ 2026年后最危险的不是“数据缺失”,而是“数据冲突”
缺失 = 可以补
冲突 = 直接判高排放因子
任何冲突都有可能让企业:
❌ 失去欧盟订单
❌ ETS成本上涨 2–4 倍
❌ 无法清关
❌ 被列为高风险供应商
⑤ 最终结论:未来铝企业的壁垒是“数据逻辑”
谁能做到:
✔ 数据逻辑在线
✔ 供应链路径清晰
✔ 排放因子可追溯
✔ 工序排放可拆分
✔ MRV & MPV 全一致
谁就能成为:
👉 进口商的首选供应商
👉 低ETS成本企业
👉 长期稳定合作对象
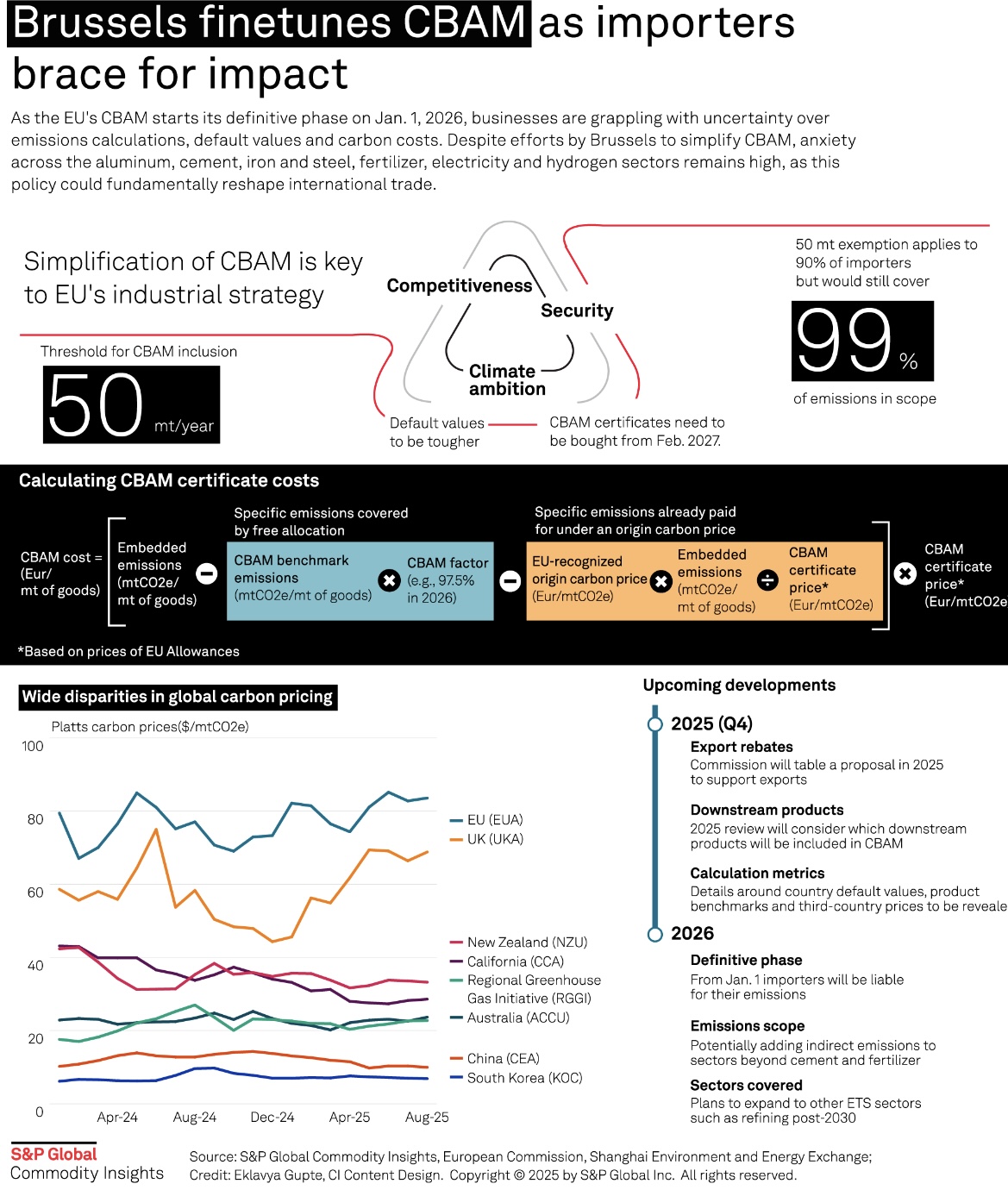
如果你不确定你的排放数据(原铝/再生铝/型材/旅制品)是否一致、能否通过欧盟审核,
留言产品,我可以帮你做一次免费的“数据一致性评估”。

















 3123
3123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









