






为什么要使用RAG?
当下领先的大语言模型(LLMs)通过大规模数据训练来掌握广泛的普遍知识,这些知识存储在其神经网络的权重中。然而,如果要求LLM生成涉及其训练数据以外的知识(如最新、专有或特定领域信息),就会出现事实上的错误(称为"幻觉")。
通过使用微调(fine-tuning)或是检索增强生成(RAG)方式都可解决这一问题。但通常使用微调通常需要耗费大量计算资源、成本高昂,且需要丰富的微调经验。此外Fine tuning需要代表性的数据集且量也有一定要求,且Fine tuning 并不适合于在模型中增加全新的知识或应对那些需要快速迭代新场景的情况。本文介绍的是另外一种方式,通过RAG的方式检索数据信息,这种方式成本低且可以快速地实现。
检索增强生成(RAG)是一个概念,它旨在为大语言模型(LLM)提供额外的、来自外部知识源的信息,提高 AI 应用回复的质量及可靠性。这样,LLM 在生成更精确、更贴合上下文的答案的同时,也能有效减少产生误导性信息的可能。RAG主要解决了 LLM 常见挑战,如提供虚假信息、过时信息和非权威信息等问题。
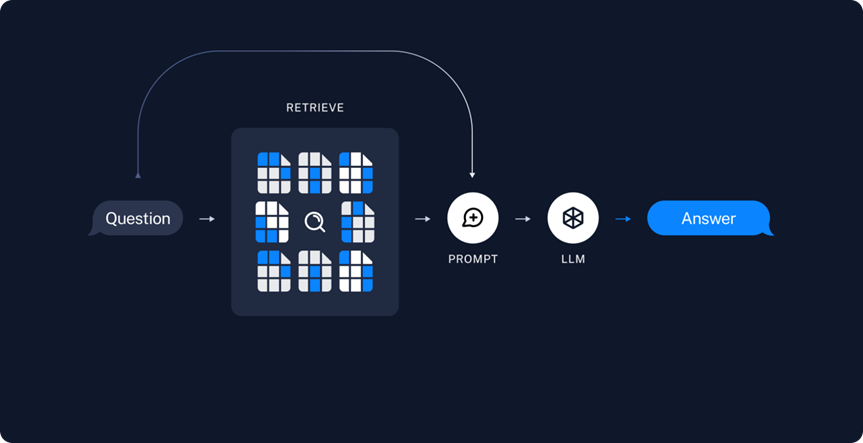
在论文《知识密集型 NLP 任务的检索增强生成》中,介绍了一种新的技术。检索增强生成(Retrieval-Augmented Generation,RAG)。这篇论文提出了一种新的模型架构,通过结合检索和生成两个阶段,解决了知识密集型NLP任务中的挑战。RAG有效利用外部知识库来增强模型性能,通过这种方式可以让LLM可以更易于查询到外部知识信息。
RAG和LLM之间存在着互补关系。RAG可以被视为一种扩展了功能的LLM,它通过引入额外的检索步骤,使得LLM能够有效利用外部知识。这两种技术结合使用,可以在许多复杂的自然语言处理任务中取得更好的效果,为开发更强大的NLP系统提供了新的可能性。
RAG的工作流程
-
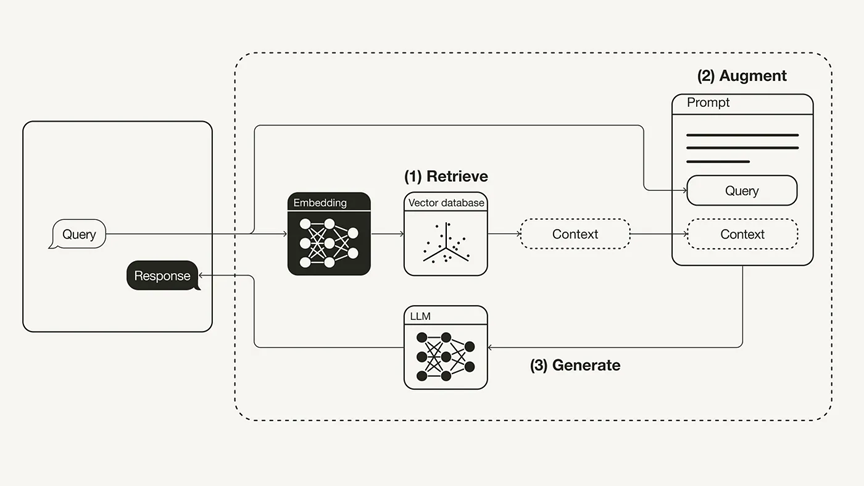
检索: 当接收到用户查询时,使用检索索引找到最相关的文档。具体来讲,对用户输入的查询信息Embedding转化为向量,再到向量数据库中检索其他匹配的上下文信息。通过这种相似性搜索,可以找到向量数据库中最匹配的相关数据。
-
增强: 将向量数据库中检索到的信息与用户查询信息放到我们自定义的提示模板中。
-
生成: 最后将上面经过检索以及增强后的提示内容输入到LLM中,LLM根据上述信息生成最终结果。
其中向量数据库里存储的是外部知识,通过嵌入模型将非结构化数据存储向量数据库中。具体流程如下图所示:
-
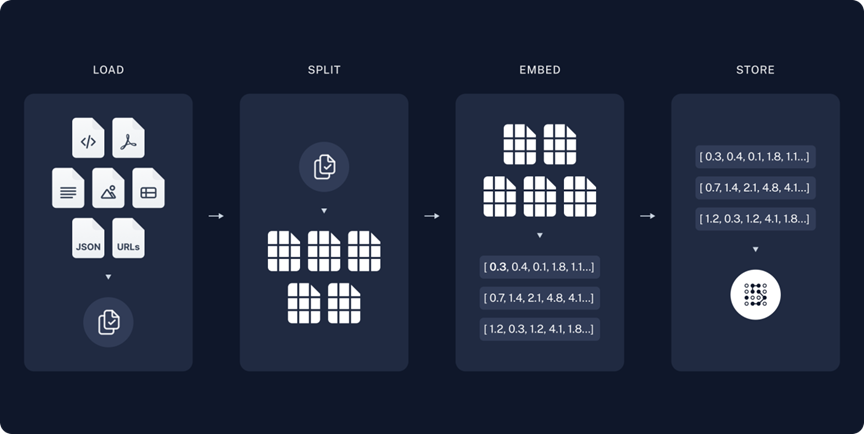
加载: 加载指定的数据,不同的文件可以通过不同的文档加载器完成。
-
拆分: 通过文本拆分器将内容拆分成小块内容。这对于索引数据和将数据传递到模型都很有用,因为大块内容更难搜索,并且不适合模型的有限上下文窗口。
-
嵌入: 利用Embedding技术可以将高维度的数据(例如文字、图片、 音频)映射到低维度空间,即把图片、音频和文字最终转化为向量来表示。其中,向量是一组数值,可以表示一个点在多维空间中的位置。
-
存储: 需要一个向量数据库用来存储和索引分割后的向量,便于日后快速的检索数据。
基于 LangChain 实现的检索增强生成方法
LangChain 是一个开源的工具包,目标是帮助开发者快速构建 AI 应用程序。它提供了一系列的功能,如模型托管、数据管理和任务自动化等。通过LangChain我们可以快速地搭建一个RAG应用。
在这一部分,我们将展示如何利用Python 结合 OpenAI 的大语言模型、Weaviate的向量数据库以及 OpenAI 的嵌入模型来实现一个检索增强生成(RAG)流程。在这个过程中,我们将使用 LangChain 来进行整体编排。
准备好向量数据库,向量数据库(Vector Database)是一种以向量为基础的数据存储和查询系统,它利用向量空间模型来表示和查询数据。通过向量数据库将我们自己指定的资料转换为向量并写入到数据库。具体步骤如下:
i. 收集数据并将其加载进系统
ii. 将文档进行分块处理
iii. 对分块内容进行嵌入,并存储这些块
- 首先, 加载指定的数据。数据类型支持文本、PDF、Word、Excel、CSV、HTML等不同的文件。下面例子中使用TextLoader来加载文本。针对不同文件类型可以使用不同的加载器,如CSVLoader加载CSV文件、WebBaseLoader通过URL方式加载网页数据,而PDF也有许多加载方式如PDFMinerLoader是其中之一。
import requests
from langchain.document_loaders import TextLoader
url ="https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
withopen("state_of_the_union.txt","w")as f:
f.write(res.text)
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
- 其次, 需要对文档进行分块。分块(chunking)是将大块文本分解成小段的过程。分块可以帮助我们优化从向量数据库被召回的内容的准确性。LangChain 也提供了许多文本分割工具,对于这个的示例,可以使用 CharacterTextSplitter来进行分割。设置片段大小 chunk_size 为 500,并且设置重叠token数量 chunk_overlap 为 50,以确保文本块之间的连贯性。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
- 最后, 通过Embedding技术将其转为向量并存储这些文本块 。为了实现让LLM理解文件中的内容,需要为分块后的数据Embedding,并将它们存储起来。有多种方式可以Embedding,在本例中使用 OpenAI 的嵌入模型;最后使用Weaviate 向量数据库将向量保存。在LangChain中通过执行 .from_documents() 操作,就可以自动将这些块向量填充进向量数据库中。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text =False
)
-
Part 2 使用向量库中的数据检索用户提出的问题
-
检索: 在前面已经将文件转为向量数据并写入到向量数据库中,接下来就可以将它设定为检索组件。这个组件能够根据用户查询与已嵌入的文本块之间的语义相似度,来检索出额外的上下文信息。
retriever = vectorstore.as_retriever()
- 增强: 准备一个提示模板,通过预设的提示信息,再加上检索后的上下文信息来增强原始的提示。
from langchain.prompts import ChatPromptTemplate
template ="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt)
- 生成: 通过RAG链,可以通过将检索器、提示模板与LLM 相结合。下面的RAG链会对用户提出的问题先进行向量检索,再将检索后的数据和提示模板结合,最终LLM根据上述信息生成答案。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain =(
{"context": retriever,"question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query ="What did the president say about Justice Breyer"
rag_chain.invoke(query)
其中rag_chain是核心部分,在这一步中构建了使用GPT-3.5大模型,并通过prompt增强问题后去向量数据库中检索答案的RAG链。
上面例子中,我们对LLM提出问题:”总统对布雷耶大法官是如何评价的“。LLM通过向量库检索后回复:
“总统对布雷耶法官的服务表示感谢,并赞扬了他对国家的贡献。”
“总统还提到,他提名了法官凯坦吉·布朗·杰克逊来接替布雷耶法官,以延续后者的卓越遗产。”
总结
在基于 LLM实现的问答系统中使用 RAG 有三方面的好处:
-
确保 LLM 可以回答最新,最准确的内容。并且用户可以访问模型内容的来源,确保可以检查其声明的准确性并最终可信。
-
通过将 LLM建立在一组外部的、可验证的事实数据之上,该模型将信息提取到其参数中的机会更少。这减少了 LLM 泄露敏感数据或“幻觉”不正确或误导性信息的机会。
-
RAG 还减少了用户根据新数据不断训练模型并随着数据的变化更新训练参数的需要。通过这种方式企业可以减低相关财务成本。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









