




引言
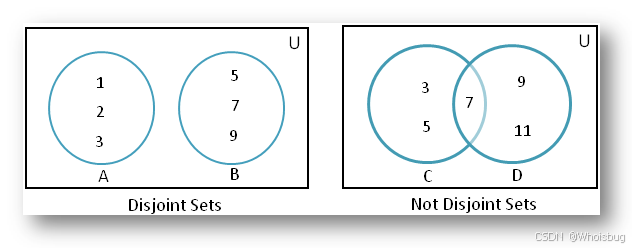
不相交集合(Disjoint Sets)是一种数据结构,用于处理一些不相交的集合,并支持两种主要操作:查找(Find)和合并(Union)。这种数据结构在图算法、网络流问题和并查集问题中非常有用。
等价关系和等价类
在数学中,等价关系是一种二元关系,满足自反性、对称性和传递性。等价类是集合中所有相互等价的元素的集合。不相交集合 ADT 可以用来高效地管理和操作这些等价类。
不相交集合 ADT
不相交集合 ADT 定义了以下操作:
-
MakeSet:创建一个新的集合,包含一个元素。
-
Find:查找元素所属的集合。
-
Union:合并两个集合。
应用
不相交集合 ADT 在许多领域都有应用,包括:
-
图算法:如 Kruskal 最小生成树算法。
-
网络流问题:用于管理网络中的流量。
-
并查集问题:用于处理集合的合并和查找操作。
实现不相交集合 ADT 的权衡
不相交集合 ADT 有多种实现方式,每种实现方式都有其优缺点。常见的实现方式包括:
-
快速合并(Fast UNION):通过路径压缩优化查找操作。
-
快速查找(Quick FIND):通过按秩合并优化合并操作。
快速合并实现(慢查找)
快速合并实现通过路径压缩优化查找操作,使得每次查找操作的时间复杂度接近O(logn)
代码示例
typedef struct DisjointSet {
int *parent;
int *rank;
int size;
} DisjointSet;
// 创建不相交集合
DisjointSet* createDisjointSet(int size) {
DisjointSet *ds = (DisjointSet*)malloc(sizeof(DisjointSet));
ds->parent = (int*)malloc(size * sizeof(int));
ds->rank = (int*)malloc(size * sizeof(int));
ds->size = size;
for (int i = 0; i < size; i++) {
ds->parent[i] = i;
ds->rank[i] = 0;
}
return ds;
}
// 查找元素所属的集合
int find(DisjointSet *ds, int x) {
if (ds->parent[x] != x) {
ds->parent[x] = find(ds, ds->parent[x]); // 路径压缩
}
return ds->parent[x];
}
// 合并两个集合
void unionSets(DisjointSet *ds, int x, int y) {
int xRoot = find(ds, x);
int yRoot = find(ds, y);
if (xRoot != yRoot) {
if (ds->rank[xRoot] < ds->rank[yRoot]) {
ds->parent[xR 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









