




1 什么是优先队列?
优先队列是一种抽象数据类型,它支持在一组元素中插入元素,并且能够高效地删除具有最高优先级的元素。优先队列通常用于调度算法、事件驱动的模拟和图算法中。
2 优先队列 ADT
优先队列的抽象数据类型(ADT)定义了以下操作:
-
insert:插入一个元素到优先队列中。
-
deleteMax:删除并返回具有最高优先级的元素。
-
isEmpty:检查优先队列是否为空。
-
size:返回优先队列中的元素数量。
3 优先队列的应用
优先队列在许多领域都有应用,包括:
-
操作系统调度:用于管理进程的调度。
-
网络流量管理:用于优先处理高优先级的数据包。
-
图算法:如 Dijkstra 最短路径算法和 Prim 最小生成树算法。
4 优先队列的实现
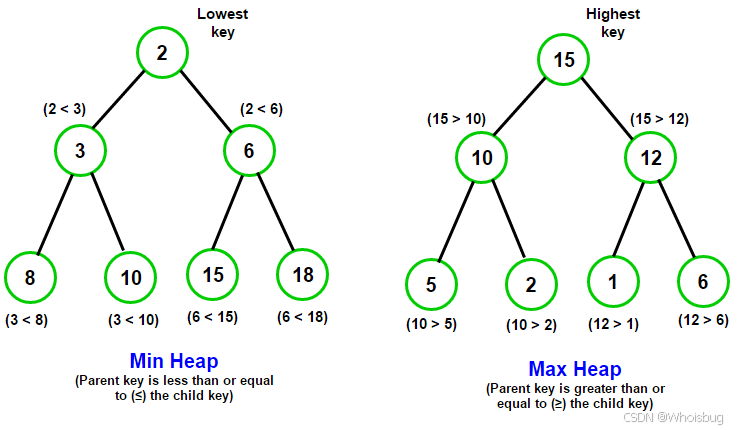
优先队列可以通过多种数据结构实现,最常见的是使用堆。堆是一种特殊的完全二叉树,其中每个节点的值都大于或等于其子节点的值(最大堆)或小于或等于其子节点的值(最小堆)。
代码示例
typedef struct HeapNode {
int data;
} HeapNode;
typedef struct PriorityQueue {
HeapNode *array;
int capacity;
int size;
} PriorityQueue;
// 创建优先队列
PriorityQueue* createPriorityQueue(int capacity) {
PriorityQueue *pq = (PriorityQueue*)malloc(sizeof(PriorityQueue));
pq->array = (HeapNode*)malloc(capacity * sizeof(HeapNode));
pq->capacity = capacity;
pq->size = 0;
return pq;
}
// 插入元素
void insert(PriorityQueue *pq, int data) {
if (pq->size == pq->capacity) {
return; // 队列已满
}
int index = pq->size;
pq->array[index].data = data;
while (index != 0 && pq->array[(index - 1) / 2].data < pq->array[index].data) {
// 与父节点交换
HeapNode temp = pq->array[(index - 1) / 2];
pq->array[(index - 1) / 2] = pq->array[index];
pq->array[index] = temp;
index = (index - 1) / 2;
}
pq->size++;
}
// 删除最大元素
int deleteMax(PriorityQueue *pq) {
if (pq->size == 0) {
return -1; // 队列为空
}
int max = pq->array[0].data;
pq->size--;
pq->array[0] = pq->array[pq->size];
int index = 0;
while (index * 2 + 1 < pq->size) {
int largest = index;
if (pq->array[index * 2 + 1].data > pq->array[largest].data) {
largest = index * 2 + 1;
}
if (index * 2 + 2 < pq->size && pq->array[index * 2 + 2].data > pq->array[largest].data) {
largest = index * 2 + 2;
}
if (largest == index) {
break;
}
// 与最大子节点交换
HeapNode temp = pq->array[index];
pq->array[index] = pq->array[largest];
pq->array[largest] = temp;
index = largest;
}
return max;
}
// 检查优先队列是否为空
int isEmpty(PriorityQueue *pq) {
return pq->size == 0;
}
// 获取优先队列的大小
int size(PriorityQueue *pq) {
return pq->size;
}
// 释放优先队列
void freePriorityQueue(PriorityQueue *pq) {
free(pq->array);
free(pq);
}
5 堆和二叉堆
堆是一种特殊的完全二叉树,其中每个节点的值都大于或等于其子节点的值(最大堆)或小于或等于其子节点的值(最小堆)。二叉堆是堆的一种实现,通常使用数组来存储。
代码示例
// 堆化操作
void heapify(int arr[], int n, int i) {
int largest = i; // 初始化最大值为根节点
int l = 2 * i + 1; // 左子节点
int r = 2 * i + 2; // 右子节点
// 如果左子节点大于根节点
if (l < n && arr[l] > arr[largest]) {
largest = l;
}
// 如果右子节点大于当前最大值
if (r < n && arr[r] > arr[largest]) {
largest = r;
}
// 如果最大值不是根节点,交换并继续堆化
if (largest != i) {
int temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
heapify(arr, n, largest);
}
}
// 构建最大堆
void buildMaxHeap(int arr[], int n) {
// 从最后一个非叶子节点开始堆化
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
}
// 堆排序
void heapSort(int arr[], int n) {
buildMaxHeap(arr, n);
for (int i = n - 1; i > 0; i--) {
// 交换根节点和最后一个节点
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// 堆化剩余的堆
heapify(arr, i, 0);
}
}
6 堆排序
堆排序是一种高效的排序算法,它利用堆的性质来排序数组。堆排序的时间复杂度为 O(nlogn)
代码示例
// 堆排序
void heapSort(int arr[], int n) {
buildMaxHeap(arr, n);
for (int i = n - 1; i > 0; i--) {
// 交换根节点和最后一个节点
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// 堆化剩余的堆
heapify(arr, i, 0);
}
}
7 优先队列的问题与解决方案
问题 1:计算图的强连通分量
解决方案:使用深度优先搜索(DFS)来计算图的强连通分量。具体步骤如下:
-
对图进行深度优先搜索,记录每个节点的访问顺序。
-
反转图的边方向。
-
按照访问顺序的逆序对反转后的图进行深度优先搜索,每次搜索到的节点集合即为一个强连通分量。
代码示例
// 图的邻接矩阵表示
int adjMatrix[256][256];
int table[256];
int dfsnum[256], num = 0, low[256];
int postOrder[256];
int postOrderIndex = 0;
// 深度优先搜索
void dfs(int u) {
low[u] = dfsnum[u] = num++;
table[u] = 1;
for (int v = 0; v < 256; v++) {
if (adjMatrix[u][v] && table[v] == -1) {
if (dfsnum[v] == -1) {
dfs(v);
}
low[u] = fmin(low[u], low[v]);
}
}
postOrder[postOrderIndex++] = u;
}
// 计算强连通分量
void stronglyConnectedComponents(int n) {
memset(table, -1, sizeof(table));
memset(dfsnum, -1, sizeof(dfsnum));
memset(low, -1, sizeof(low));
for (int i = 0; i < n; i++) {
if (table[i] == -1) {
dfs(i);
}
}
// 反转图
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
adjMatrix[i][j] = !adjMatrix[i][j];
}
}
memset(table, -1, sizeof(table));
for (int i = postOrderIndex - 1; i >= 0; i--) {
if (table[postOrder[i]] == -1) {
dfs(postOrder[i]);
// 输出强连通分量
for (int j = 0; j < n; j++) {
if (table[j] == 1) {
printf("%d ", j);
}
}
printf("\n");
}
}
}
问题 2:计算图的割点
解决方案:使用深度优先搜索(DFS)来计算图的割点。具体步骤如下:
-
对图进行深度优先搜索,记录每个节点的访问顺序和低链接值。
-
如果一个节点的低链接值大于其子节点的访问顺序,则该节点为割点。
代码示例
// 图的邻接矩阵表示
int adjMatrix[256][256];
int dfsnum[256], num = 0, low[256];
int parent[256];
int isArticulation[256];
// 深度优先搜索
void dfs(int u, int p) {
dfsnum[u] = low[u] = num++;
parent[u] = p;
int children = 0;
for (int v = 0; v < 256; v++) {
if (adjMatrix[u][v] && v != p) {
if (dfsnum[v] == -1) {
dfs(v, u);
low[u] = fmin(low[u], low[v]);
if (low[v] >= dfsnum[u] && p != -1) {
isArticulation[u] = 1;
}
children++;
} else {
low[u] = fmin(low[u], dfsnum[v]);
}
}
}
if (p == -1 && children > 1) {
isArticulation[u] = 1;
}
}
// 计算割点
void findArticulationPoints(int n) {
memset(dfsnum, -1, sizeof(dfsnum));
memset(low, -1, sizeof(low));
memset(parent, -1, sizeof(parent));
memset(isArticulation, 0, sizeof(isArticulation));
num = 0;
for (int i = 0; i < n; i++) {
if (dfsnum[i] == -1) {
dfs(i, -1);
}
}
for (int i = 0; i < n; i++) {
if (isArticulation[i]) {
printf("%d ", i);
}
}
printf("\n");
}
问题 3:计算图的桥
解决方案:使用深度优先搜索(DFS)来计算图的桥。具体步骤如下:
-
对图进行深度优先搜索,记录每个节点的访问顺序和低链接值。
-
如果一个节点的低链接值大于其子节点的访问顺序,则该边为桥。
代码示例
// 图的邻接矩阵表示
int adjMatrix[256][256];
int dfsnum[256], num = 0, low[256];
int parent[256];
int isBridge[256][256];
// 深度优先搜索
void dfs(int u, int p) {
dfsnum[u] = low[u] = num++;
parent[u] = p;
for (int v = 0; v < 256; v++) {
if (adjMatrix[u][v] && v != p) {
if (dfsnum[v] == -1) {
dfs(v, u);
low[u] = fmin(low[u], low[v]);
if (low[v] > dfsnum[u]) {
isBridge[u][v] = 1;
isBridge[v][u] = 1;
}
} else {
low[u] = fmin(low[u], dfsnum[v]);
}
}
}
}
// 计算桥
void findBridges(int n) {
memset(dfsnum, -1, sizeof(dfsnum));
memset(low, -1, sizeof(low));
memset(parent, -1, sizeof(parent));
memset(isBridge, 0, sizeof(isBridge));
num = 0;
for (int i = 0; i < n; i++) {
if (dfsnum[i] == -1) {
dfs(i, -1);
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (isBridge[i][j]) {
printf("(%d, %d) ", i, j);
}
}
}
printf("\n");
}
问题 4:计算图的双连通分量
解决方案:使用深度优先搜索(DFS)来计算图的双连通分量。具体步骤如下:
-
对图进行深度优先搜索,记录每个节点的访问顺序和低链接值。
-
如果一个节点的低链接值大于其子节点的访问顺序,则该节点为割点。
-
使用栈来记录路径,每次遇到割点时,从栈中弹出路径,直到遇到割点为止,弹出的路径即为一个双连通分量。
代码示例
// 图的邻接矩阵表示
int adjMatrix[256][256];
int dfsnum[256], num = 0, low[256];
int parent[256];
int isArticulation[256];
int stack[256], top = 0;
// 深度优先搜索
void dfs(int u, int p) {
dfsnum[u] = low[u] = num++;
parent[u] = p;
int children = 0;
for (int v = 0; v < 256; v++) {
if (adjMatrix[u][v] && v != p) {
if (dfsnum[v] == -1) {
stack[top++] = v;
dfs(v, u);
low[u] = fmin(low[u], low[v]);
if (low[v] >= dfsnum[u] && p != -1) {
isArticulation[u] = 1;
}
children++;
} else {
low[u] = fmin(low[u], dfsnum[v]);
}
}
}
if (p == -1 && children > 1) {
isArticulation[u] = 1;
}
if (isArticulation[u] || (p != -1 && low[u] == dfsnum[u])) {
printf("Biconnected component:\n");
while (stack[top - 1] != u) {
printf("%d ", stack[--top]);
}
printf("%d\n", u);
}
}
// 计算双连通分量
void findBiconnectedComponents(int n) {
memset(dfsnum, -1, sizeof(dfsnum));
memset(low, -1, sizeof(low));
memset(parent, -1, sizeof(parent));
memset(isArticulation, 0, sizeof(isArticulation));
num = 0;
top = 0;
for (int i = 0; i < n; i++) {
if (dfsnum[i] == -1) {
dfs(i, -1);
}
}
}
通过以上对优先队列和堆的深入探讨,我们可以看到这些数据结构在计算机科学的各个领域都有着广泛的应用。无论是在算法设计、数据存储还是网络通信中,优先队列和堆都扮演着不可或缺的角色。希望这篇文章能帮助你更好地理解和应用这些强大的数据结构。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









