




本地部署 Stable Diffusion:零基础搭建 AI 文生图系统
Stable Diffusion 是一款强大的开源文生图(Text-to-Image)AI 模型,可以本地运行,无需联网或付费就能生成高质量图像。相比 Midjourney、DALL·E 等云服务,Stable Diffusion 更自由、更可控。
这篇文章将手把手教你如何使用 Stable Diffusion WebUI(AUTOMATIC1111) 在本地搭建一个高效、可定制的 AI 画图系统,适合 AI 爱好者、程序员和设计师。
✅ 目录
- 为什么选择 Stable Diffusion?
- 环境准备:硬件 & 软件
- 安装与部署 WebUI
- 下载模型与生成图片
- 插件扩展推荐
- 常见问题与优化建议
- 总结与资源推荐
1️⃣ 为什么选择 Stable Diffusion?
- 🆓 免费开源,可本地运行,无版权限制
- 🖼️ 支持高质量图像生成,多种风格切换
- 🔁 支持 LoRA、ControlNet、DreamBooth 等进阶功能
- 🌍 社区活跃,模型与插件丰富
2️⃣ 环境准备
硬件要求
| 项目 | 推荐配置 |
|---|---|
| 操作系统 | Windows / macOS / Linux |
| 显卡 | NVIDIA 显卡(≥6GB 显存) |
| 内存 | ≥16GB 推荐 |
| 硬盘 | ≥10GB 可用空间(模型文件较大) |
💡 AMD 显卡也可运行,但需额外配置,如 ROCm 支持。
软件环境
- Python 3.10(强烈建议)
- Git
- 推荐使用 Anaconda 或 virtualenv 创建独立环境
3️⃣ 安装 Stable Diffusion WebUI(AUTOMATIC1111)
第一步:克隆项目
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
第二步:准备模型(权重)
下载模型权重(.ckpt 或 .safetensors 格式)并放入以下目录:
stable-diffusion-webui/models/Stable-diffusion/
常用模型:
v1.5 官方基础模型:https://huggingface.co/runwayml/stable-diffusion-v1-5
自定义模型网站:https://civitai.com
第三步:启动 WebUI
推荐参数(减少显存占用)
python launch.py --xformers --medvram --precision full
默认本地地址:http://127.0.0.1:7860
🌐 若需外部设备访问,添加 --listen 参数。
4️⃣ 生成图片:初次体验
访问 WebUI 后,直接输入提示词即可:
A fantasy landscape, mountain, lake, sunrise, ultra-detailed, 8k
点击“Generate”后,几秒内即可看到生成图像!

总结 & 推荐资源
Stable Diffusion 是目前最强大的本地 AI 画图工具之一。通过 WebUI,你可以非常容易地尝试各种图像创作风格,还能扩展训练自己的人物风格。还有一些其他模型没有配置,等回头配置完再更新。
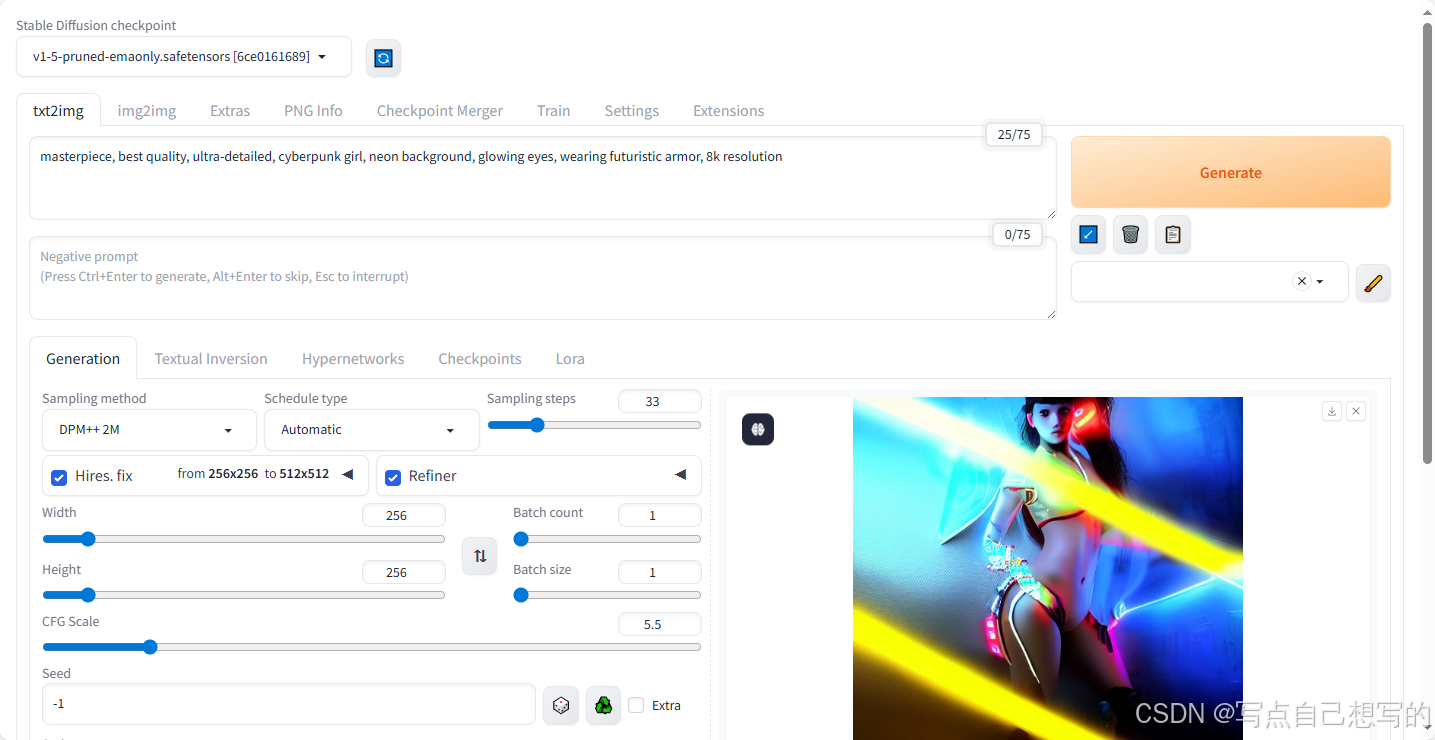
🧾 示例生成图(Prompt)
Prompt:
masterpiece, best quality, ultra-detailed, cyberpunk girl, neon background, glowing eyes, wearing futuristic armor, 8k resolution

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









