




初识
直观
PCA,pricipal components analysis,主成分分析
主成分(pricipal components)是一系列互相正交(orthogonality)的单位向量(unit vectors),组成了正交基(orthonormal basis)。
PCA就是改变数据的正交基。

这些单位向量的方向通常是使得数据到该直线的的距离最小(minimize b),或者数据到该原点的投影距离最大(maximize a),即
m
i
n
S
S
=
a
1
2
+
a
2
2
+
.
.
.
+
a
n
2
min SS = a_1^2+a_2^2+...+a_n^2
minSS=a12+a22+...+an2。

确定好拟合直线,对该向量进行单位化,得到第一个主成分单位向量。然后根据该直线找到其正交的另一条直线,即可得到第二个主成分单位向量。

将这个正交基旋转合适的角度,重新画图,得到PCA后的数据。
专业术语 Terminology
- 数据在主成分
- S S = E i g e n v a l u e SS = Eigenvalue SS=Eigenvalue
- E i g e n v a l u e = S i n g u l a r \sqrt{Eigenvalue} = Singular Eigenvalue=Singular
- unit vector = singular vector = eigenvector
- 单位向量的分量,如0.6、0.8,叫做 loading scores
- S S ( n − 1 ) = V a r i a t i o n , n 为 维 数 \frac{SS}{(n-1)} = Variation,n为维数 (n−1)SS=Variation,n为维数
- 展示Variation的图,叫做 scree plot


扩展到三维数据,拟合得到红色的线,根据红色的线得到正交的蓝色、黑色,最终得到正交基。最终的结果是,两两相交得到一个正交基,在此基础上可以画图。
PCA的应用(Applications)
- Dimensionality reduction 降维
- Surface normal estimation 表面法向量估计
- Canonical orientation 规范方向
- Keypoint detection 关键点检测
- Feature description 特征描述
理解
Vector Dot Product 内积:

基变换:数据与基做内积运算,结果作为新的坐标分量。
Matrix-Vector Multiplication : Linear combination
(
a
11
a
12
a
13
a
21
a
22
a
23
)
(
x
1
x
2
x
3
y
1
y
2
y
3
z
1
z
2
z
3
)
=
(
v
11
v
12
v
21
v
22
)
\begin{gathered} \begin{pmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \end{pmatrix} \quad \begin{pmatrix} x_1 & x_2 & x_3 \\ y_1 & y_2 & y_3 \\ z_1 & z_2 & z_3 \end{pmatrix} \quad \ = \begin{pmatrix} v_{11} & v_{12} \\ v_{21} & v_{22} \end{pmatrix} \quad \end{gathered}
(a11a21a12a22a13a23)⎝⎛x1y1z1x2y2z2x3y3z3⎠⎞ =(v11v21v12v22)
其中
a
i
j
a_{ij}
aij表示第
i
i
i个主成分;
x
i
y
i
z
i
x_i y_i z_i
xiyizi表示第
i
i
i个原数据;
v
i
j
v_{ij}
vij表示第
j
j
j个原数据投影到第
i
i
i个主成分下的值
得到值的过程
v
i
j
=
a
i
1
∗
x
j
+
a
i
2
∗
y
j
+
a
i
3
∗
z
j
v_{ij} = a_{i1}*x_j + a_{i2}*y_j + a_{i3}*z_j
vij=ai1∗xj+ai2∗yj+ai3∗zj是内积运算,即得到的值就是原始数据到主成分向量的投影
为什么选择距离最近<->投影距离最远
( the variance of the projected data points on that direction is maximal)
为了尽可能多的保存数据的原始信息,即使得数据变换后尽可能分散,如果数据过于集中,那么得到的数据单一而缺少意义
为社么后续主成分直接由垂直得到
在得到转变后的第一组和第二组数据之间,我们希望他们是线性不相关的(linearly uncorrelated)
如果二者有线性关系,数据过于相似,则是无效的
衡量两个数据之间的相关性是用的协方差,即为了使得协方差为0,尽可能保证原始数据的信息,减少信息丢失,主成分选择与前一个主成分正交的向量
公式
预备
covariance Cov 协方差:

Multivariate random variable 协方差矩阵:

Singular Value Decompositionm SVD 奇异值分解:
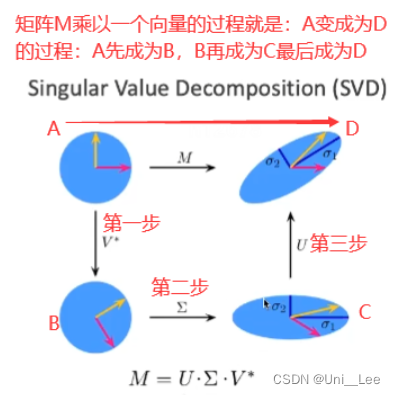
从SVD的角度去理解物理意义:比如说上图中的矩阵
M
M
M,他可以被分解成
U
∑
V
∗
U \sum V^*
U∑V∗其中
U
U
U和
V
V
V都是一个正交矩阵(类似于旋转矩阵的东西),
∑
\sum
∑就是一个对角阵,他的对角线上储存了
M
M
M的特征值,如果我把
M
M
M乘以一个向量,第一步其实就是应用
V
V
V在高维空间对这个向量做一个旋转,第一步这个圆被旋转了一下;第二步
∑
\sum
∑就是对这个旋转后的向量在每一个维度上做一个缩放,所以这个圆就变成了一个椭圆;第三步:再应用
U
U
U,也是高维空间上的旋转矩阵,所以我就把这个椭圆给旋转了一下。所以最后
M
M
M乘以一个向量就是把这个圆变成了椭圆。
eigenvalue decomposition EVD 特征值分解:

U
U
U的每一列都是相互正交的特征向量,且是单位向量,满足
U
T
U
=
I
U^TU=I
UTU=I ,
Λ
\Lambda
Λ对角线上的元素是从大到小排列的特征值,非对角线上的元素均为0。
旋转矩阵一定是对称的正交矩阵,单位正交矩阵,且行列式为1,即是旋转矩阵。
Rayleigh Quotients 瑞利熵:

所以瑞利熵说的就是我这个
A
A
A最终能够拉长或者缩短我这个向量
x
x
x多少倍,就是
λ
m
i
n
\lambda _{min}
λmin和
λ
m
a
x
\lambda _{max}
λmax是A的最小和最大特征值。
证明:

推导

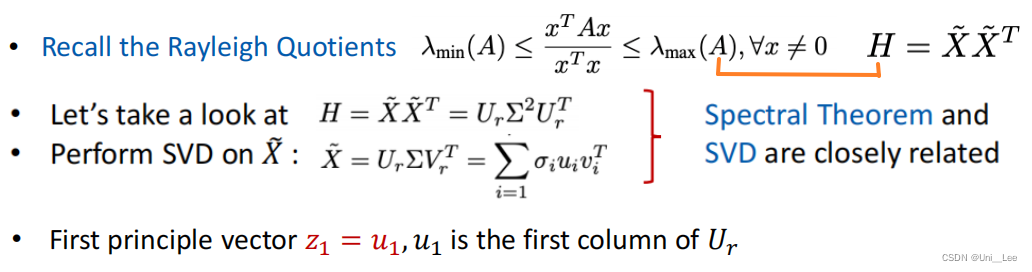


U是正交矩阵,所以u2正交与u1,即上述所说的确定好第一个主成分后,后面的主成分选择和他正交的

Kernel PCA
上述普通的PCA其实是一个线性的PCA,因为所谓的矩阵乘法也是一个线性操作而已,因为矩阵乘以向量其实是对矩阵列的线性组合。当遇到的数据不是线性时,可以选择先升到高维(high dimension),再PCA。将原来二维空间的数据,升到三维空间,再做以划分。这个升维操作就叫做Kernel PCA。
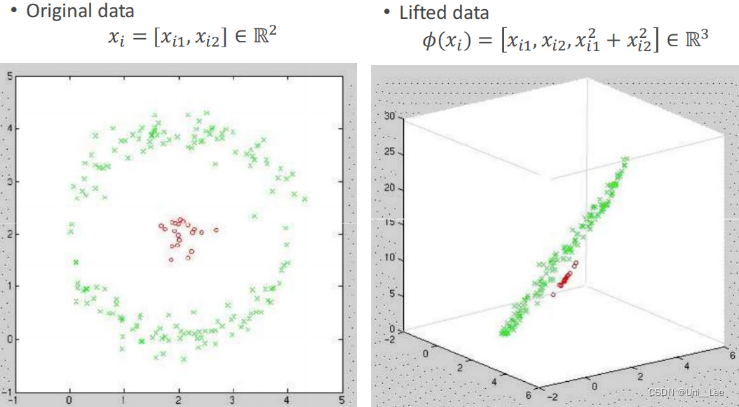
具体定义:





参考链接
- StatQuest: Principal Component Analysis (PCA), Step-by-Step:https://www.youtube.com/watch?v=FgakZw6K1QQ
- https://blog.youkuaiyun.com/m0_37957160/article/details/115350430
- https://zhuanlan.zhihu.com/p/37609917
- http://www.ams.org/publicoutreach/feature-column/fcarc-svd
- https://blog.youkuaiyun.com/qq_40824311/article/details/102607966
- https://zhuanlan.zhihu.com/p/59775730

















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









