






图系统的评测是验证系统功能与能力很重要的一环。一般而言有三大评测途径:自评、偏学术(公益、标准化)类型组织的评测和工业界的内部评测。
自评是每一个图系统构建者一定需要反复进行的工作,只有经过全面的自评才能查漏补缺、知己知彼,不过因为缺乏第三方的检验,很多自评结果容易受到质疑,如准确性、公平性、全面性等;学术类型组织的评测在海外有LDBC(Linked-Data Benchmark Council)、加州大学伯克利分校的GAP Benchmark等机构,在国内有大数据信通院等机构;工业界的内部图系统评测,一般称之为POC测试。
以上3类评测的方法论、具体步骤和关注点各不相同。本节旨在向读者介绍它们之间的共性,以及各自的特性。
一套完整的图系统评测体系至少包含4方面的测试:功能性测试、压力测试、接口测试和二次开发测试。其中,接口测试与二次开发测试也可看作是功能性测试的子集,把它们单列是因为兼顾到不同维度的侧重点。功能性测试又可细分为如下子项:
·数据导入测试。
·元数据操作测试(增、删、改、查),包括批量测试和单条测试。
·图查询操作测试,包括路径查询、K邻查询、模板查询、变量计算及其他复杂查询。
·图算法测试,包括通用图算法和复杂图算法。
·API/SDK测试。
·工具测试,包括可视化工具和数据处理工具。
·压力测试。覆盖以上所有细分功能在不同负载(并发规模、任务复杂度)情况下的系统表现(资源消耗情况、稳定性、一致性等)。
本篇内容,老夫将详细介绍在评测过程中比较重要的3个部分:评测环境、评测内容和正确性验证。
测评环境:
评测环境可以简单地分为硬件环境和软件环境两个部分。
前者覆盖的范畴包括服务器资源、网络资源、网络存储环境、虚拟化环境等,如下表所示:
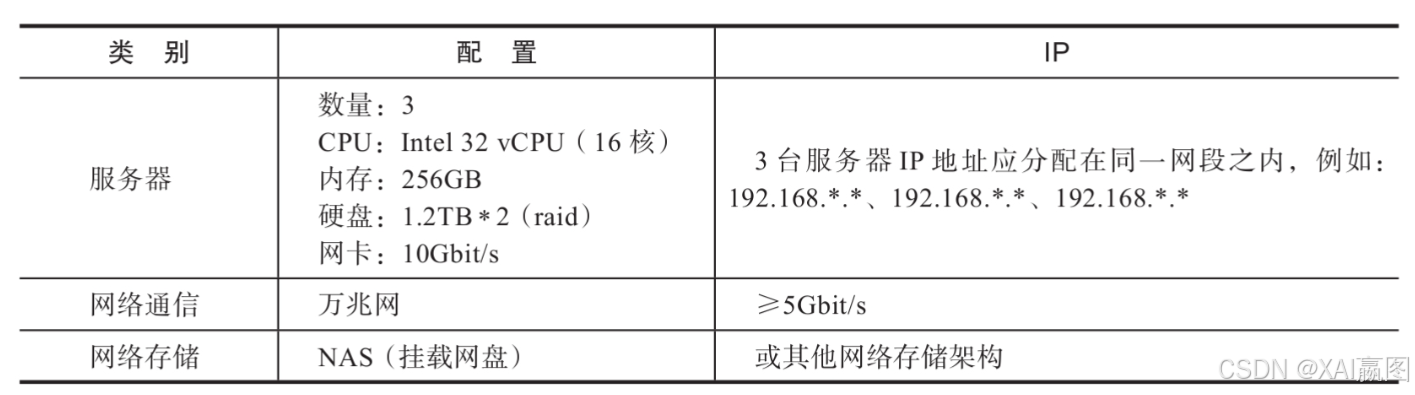
在上表中采用的是典型的基于X86的硬件环境,某些图系统可能会采用基于RISC指令集架构的,例如ARM处理器,或者是同样基于RISC的源自IBM的PowerISA架构,甚至是图形处理器GPU的定制化基于矩阵运算的图系统。
需要指出的是,依托这3种架构实现的图系统颇为少见,它们的通用性与能力还有待时间与市场检验,也因此并不在本书的覆盖范畴内。
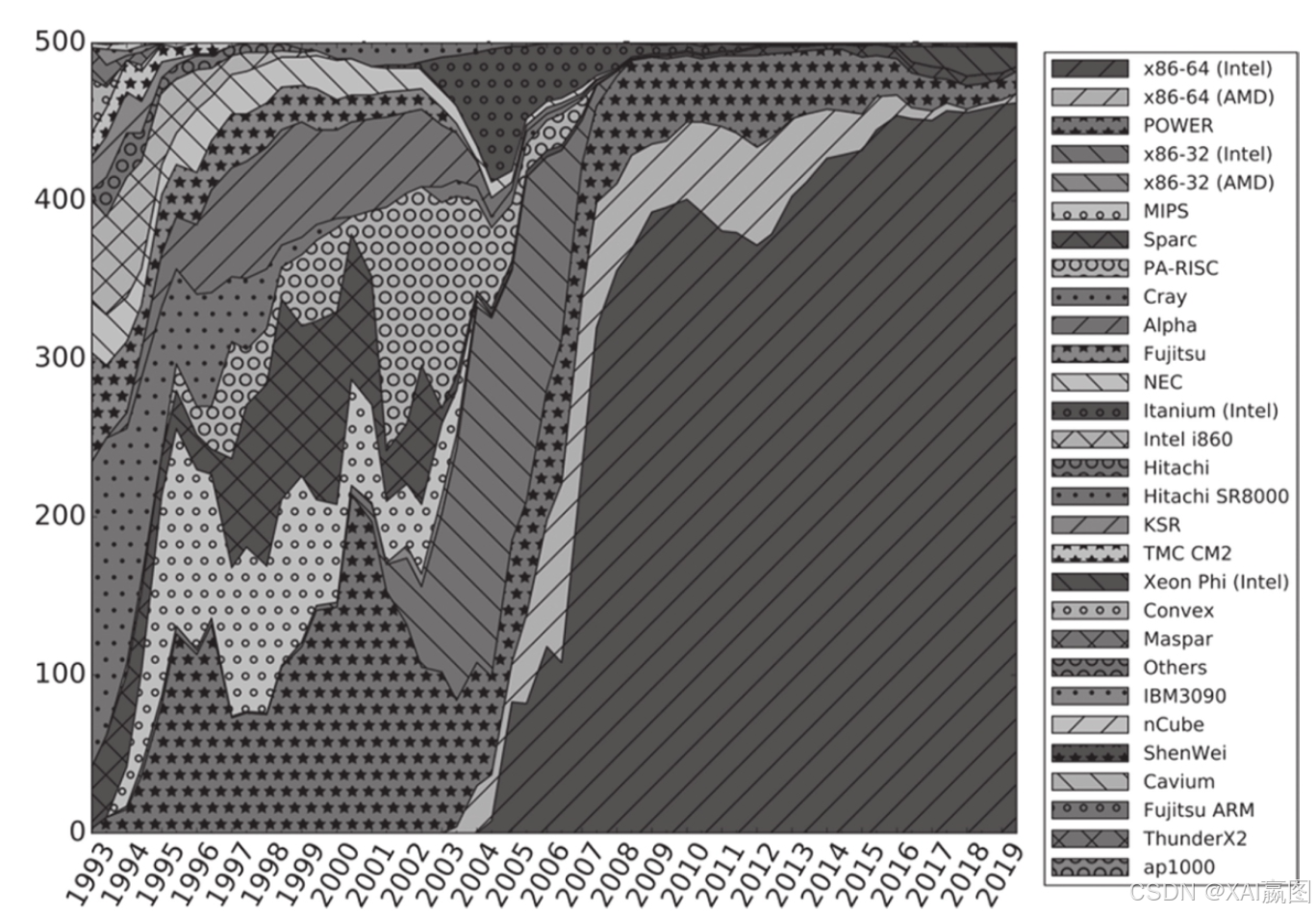
值得指出的是,如下图1所示,在超级计算机的前500位系统中,96%以上(481套系统)采用的是X86体系架构,然而在2021年11月公布的最新榜单中,排名第一的是一套日本公司基于ARM架构搭建的系统,排名第二、第三的则是两所美国实验室基于Power架构搭建的系统,排名第四的是中国的神威·太湖之光系统,根据公开资料显示,其采用的是一种类似于Power的RISC架构,排名第六位的则是nVidia公司的系统,它采用了X86+GPU的异构混合模式,通过GPU的高并发能力来对X86进行加速。当然,榜单后面几乎所有的系统都采用的是X86的架构,即基于Intel或AMD的64位CPU的系统实现。
软件系统因为构建在硬件环境之上,通常会由图系统根据其所需的运行环境、开发环境和测试环境来自行搭建。各家软件的依赖栈、调用方式、版本命名、配置参数和对系统资源的消耗方式各不相同,因此软件环境中通常更多地关注一些基础类别的软件,如下表2所示。

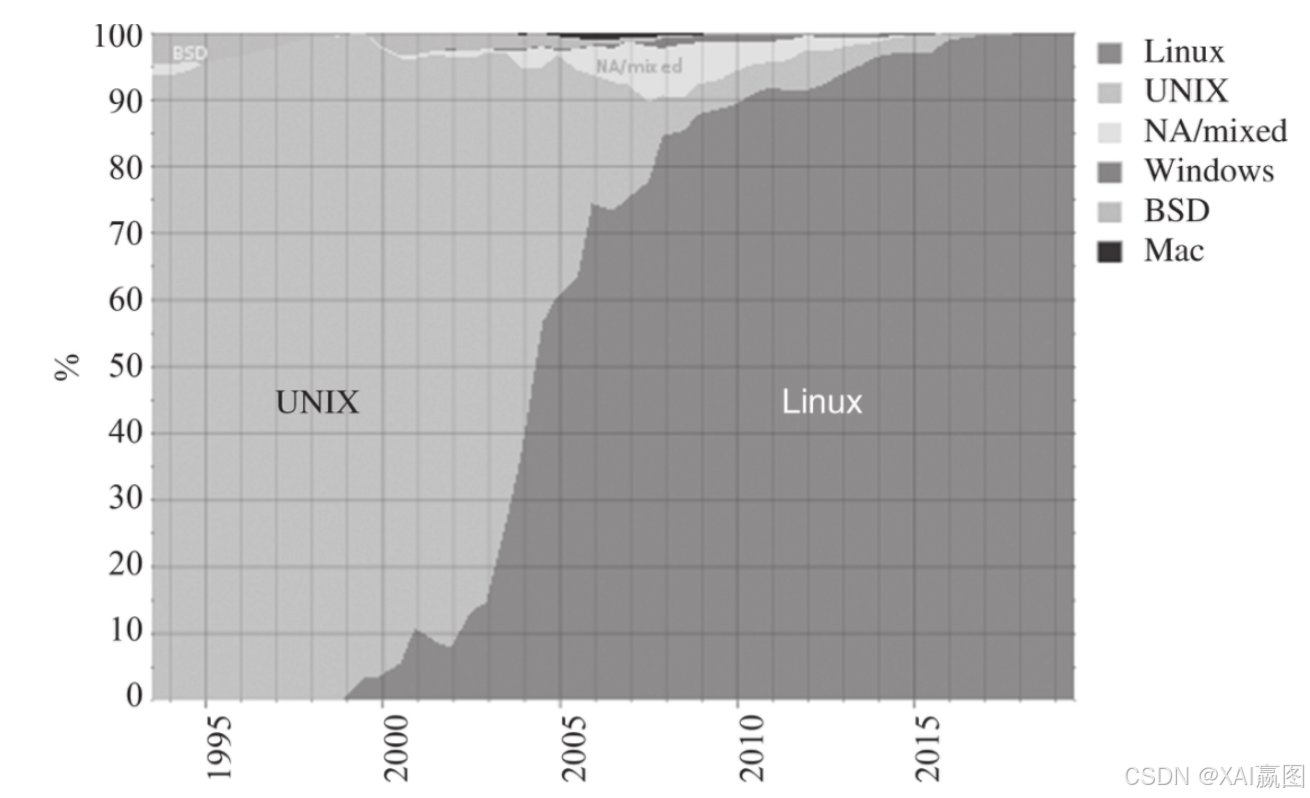
以超级计算机的系统为例,如图2所示,自2017年底至今全部的上榜系统都是基于Linux内核实现的,由此可见,图系统的评测基本上会基于Linux操作系统。当然,随着虚拟化、容器化等技术的普及,即便是在其他类型的操作系统环境上,也可以比较便捷地嵌入图系统。
在测试的过程中,也有可能需要提供完整的第三方软件使用列表,并视安全合规的需要提供安全漏洞扫描报告。相关内容已超出本篇需要覆盖的范畴,在此不予展开。
在多数的评测中,测试环境的软件和硬件配置在很大程度上取决于待测试数据集,特别是一些硬件指标和数据集直接相关,例如小数据集只需要低配的服务器甚至纯虚拟机环境即可,而大数据集则通常对于硬件的配置要求更高。
测试数据集一般分为两种风格:
·学术风格:含社交SNS图集、Web网络数据集、路网信息数据集、人工合成数据集等;
·工业风格:知识图谱类、金融图谱类、交易网络类、信贷反欺诈类、自然语言处理NLP数据集、通用图谱类等。
学术风格的数据集一般属于简单图、同构、点边无属性的范畴。这类数据集都是从20世纪的图论、运筹学、路径规划、社会心理学、SNS社交网络、NLP研究出发演变而来的。
工业界的数据集则出现要晚得多,多半都是最近10年才开始崭露头角,一般都是多边图、异构、点边自带属性。金融行业的交易网络、知识图谱都是常见的工业级图数据集。
两类图数据集的对比如表3所示。
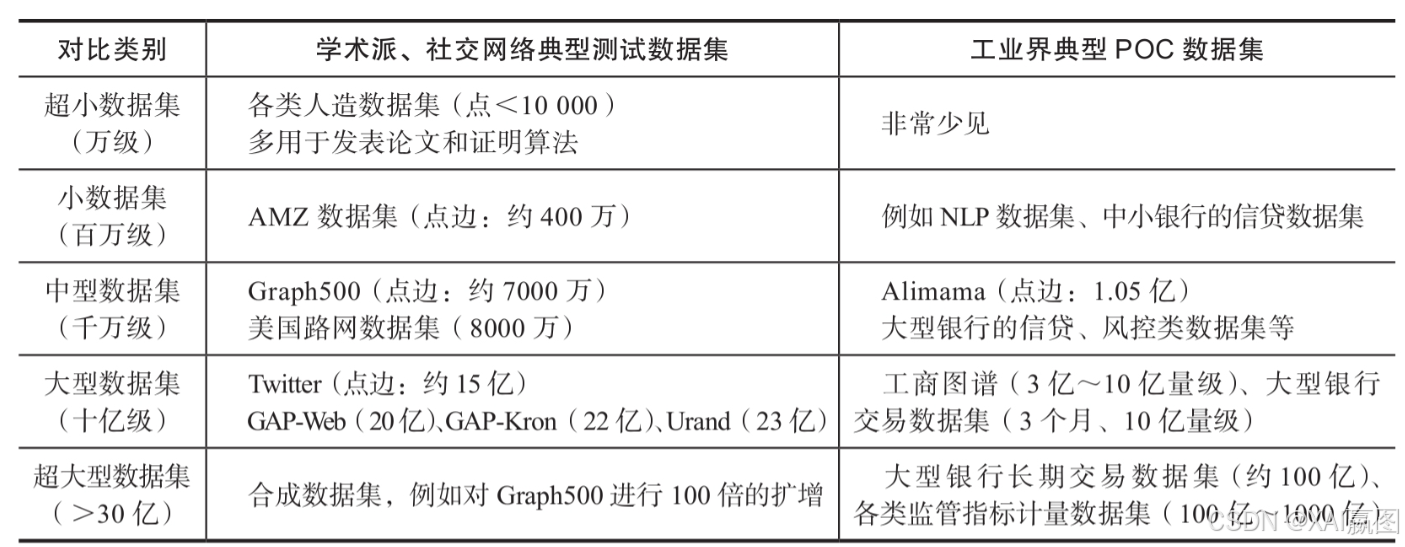
注:LDBC测试数据集介于上表中两类数据集之间,目前为止的测试内容偏重SNB类型测试数据和场景,即社交网络评测(social network benchmarks)。随着近年来以金融行业为代表的工业界的图数据测试需求快速增长,LDBC董事会也在筹划推出金融服务行业评测标准(financial services benchmarks),2022年会有更详细的内容发布。
虽然在表3采用数据集的大小来划分测试的分级,但是图数据的测试复杂度并不与全量数据的大小成正比。这也是图系统区别于传统数据库系统最核心的地方。在前面的内容中对此有过解释,在这里再次重申,图系统中的每个操作的(平均)复杂度取决于:
·图数据集的拓扑结构,例如点边比(通常用E/N来表示,其中E为全部边的数量,N为顶点的数量),是否存在自环、环路等复杂的拓扑结构,联通分量的多少等;
·具体的被查询的数据的出入度情况,例如它的出边与入边数量、1度邻居、2度邻居、3度邻居……依此类推;
·只有那些对全图的数据做某种聚合统计类操作的复杂度才与全局数据量成正比,而这类操作在图系统中属于元数据操作类型——可以说,如果仅仅是这类操作,传统数据库也可以解决。
图的拓扑结构是决定算法复杂度的最核心要素,它和全量数据大小无关,而是取决于图数据的联通性特质。有的图看似数量级很大,但是非常“稀疏”(点边比),计算复杂度低;有的图点边数量很小,但是密度很高,计算复杂度很高;还有的图的联通分量很多,每个联通分量都是一张独立的子图,网络化的查询的复杂度则直接取决于当前联通分量的拓扑结构。
有鉴于此,我们在制订评测计划的时候,并不需要盲目地或仅限于使用大数据集来测试某一款图系统的性能。下面举两个例子:
·很多时候,只要用中小型数据集就足以快速地实现评估。例如在AMZ数据集中(约40万顶点、340万边),随机访问任一顶点,查找其深度为1步的全部去重邻居数据集(统计数量,并返回全部结果集),并逐级加大搜索深度到2步、3步、5步、8步、10步、15步,直至没有返回结果为0(空数据集,表示在当前出发顶点所在的联通分量中,已经遍历完全部顶点,或已找到从当前出发顶点遍历的最大深度)或无法在限定时间内返回结果,即可测试出任何一款图系统的深度遍历、穿透与下钻的能力。
·在一些全量全国工商图谱上,规模到了10亿量级,从任何一家公司或董监高(上市公司的董事、监事和高级管理人员)节点出发查找它们的关联、控股路径,如果是完全无过滤的暴力计算,它们可能会在10层后关联数以千万计的其他实体,然而对于智能化的图系统而言,带过滤的查询才更能体现系统的能力——例如通过过滤点、边的属性和设定一些阈值来精准地查询某公司对外的投资网络、持股路径或其最终受益人。过滤的过程在图系统中就是进行动态剪枝的过程,虽然表面上看有数以千万级的关联实体,但是真正有效的“目标实体”可能只有1个、10个、1000个,而如何高效地找到这些实体及其关联路径的能力,才是我们评测一款图系统的正确打开方式。而不是像某些AI训练系统一样,通过无休止的计算来获得看似正确,却无法解释的结果。
·大体量的数据集适合验证图系统在面向全量数据时的处理能力,但是并不能检验其深度查询的能力,例如:
·图算法时耗、回写能力,与数据量成正比;
·增量数据的处理能力(插入、删除等),可以检测随着数据量增大,这些操作的时耗变化范围(恒定为最优,亚线性增长其次,线性增长则堪忧,依此类推);
·路径查询、K邻查询等操作则与数据量不完全相关(dataset size agnostic)。
今天就此收笔,下篇内容老夫接着聊如何内容评测!
· END ·
(文/Ricky - HPC高性能计算与存储专家、大数据专家、数据库专家及学者)


















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









