




大数据一般分为四大阵营。
那么,它们分别是什么呢?

今天,老夫主要聊聊OLTP阵营,它可以分为:
· 传统的关系数据库
· NoSQL数据库
· NewSQL数据库
这3类解决方案。在这里,我们主要针对NoSQL数据库与NewSQL数据库进行讨论。
1.NoSQL数据库
NoSQL数据库普遍存在以下共同特征。
(1)不需要预定义数据模式或表结构:数据中的不同记录可能有不同的属性和格式。当插入数据时,并不需要预先定义它们的模式(如MongoDB,后文中将会介绍)。NoSQL和传统的关系数据库的对比如图1所示。可以看出,NoSQL数据库无数据清洗,无数据转换,无数据加载,并且在数据存储处进行分析。
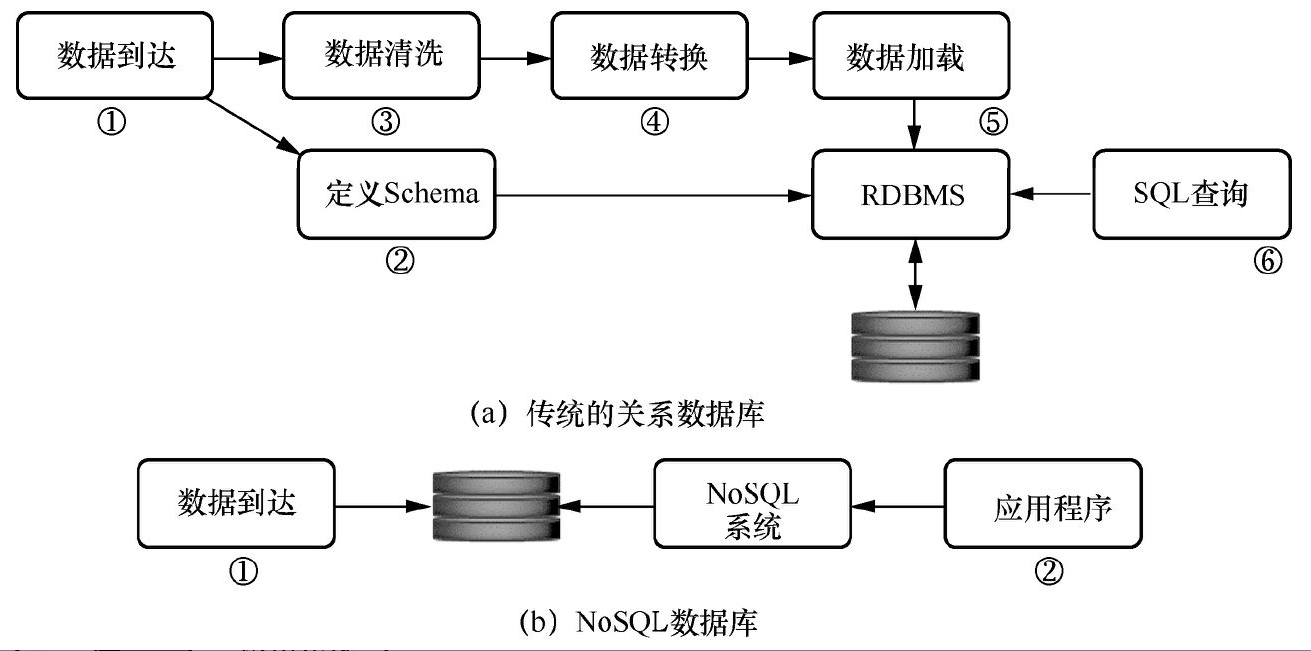
(2)无共享架构:NoSQL数据库通常把数据划分后存储在各个本地服务器上,这是因为从本地磁盘读取数据的性能往往好于通过网络传输(如NAS/SAN)读取数据的性能,从而使系统的性能得到提高。
(3)分区:NoSQL数据库需要对数据集进行分区,将记录分散在多个节点上,并在分区的同时进行复制。这样既提高了并行性能,又能保证没有单点失效的问题。
(4)弹性可扩展:可以在系统运行的时候,动态添加或者删除节点。不需要停机维护,数据便可以自动迁移。
(5)异步复制:和RAID存储系统不同的是,NoSQL数据库中的复制往往是基于日志的异步复制。这样,数据就可以尽快地写入一个节点,不会因网络传输而引起时延。缺点是并不总能保证一致性,这样的方式在出现故障的时候,可能会丢失少量的数据。
(6)符合BASE模型:BASE提供的是最终一致性和柔性事务(相对于保证事务一致性的ACID模型,后文中的NewSQL数据库在NoSQL数据库基础上实现了对ACID模型的支持)。
在前文中,老夫已经对NoSQL数据库做了初始的分类介绍,这里对颇具代表性的MongoDB(文档数据库)、Cassandra(宽表数据库)、Redis(键值数据库)和两款图数据库(Neo4j与嬴图数据库)解决方案进行介绍。
(1)MongoDB
作为文档数据库的代表,MongoDB采用了一种与RDBMS(关系型数据库管理系统,Relational Database Management System)截然相反的设计理念,不需要预先定义数据结构,使用了与JSON(JavaScript Object Notation,JS对象标记)兼容的BSON(Binary JSON)轻量级数据传输与存储结构,相对于笨重、复杂的XML而言(XML一直以其解析复杂而被广大Web开发人员所诟病),不需要对存储的数据结构进行正则化处理(其目的是减少重复数据)。
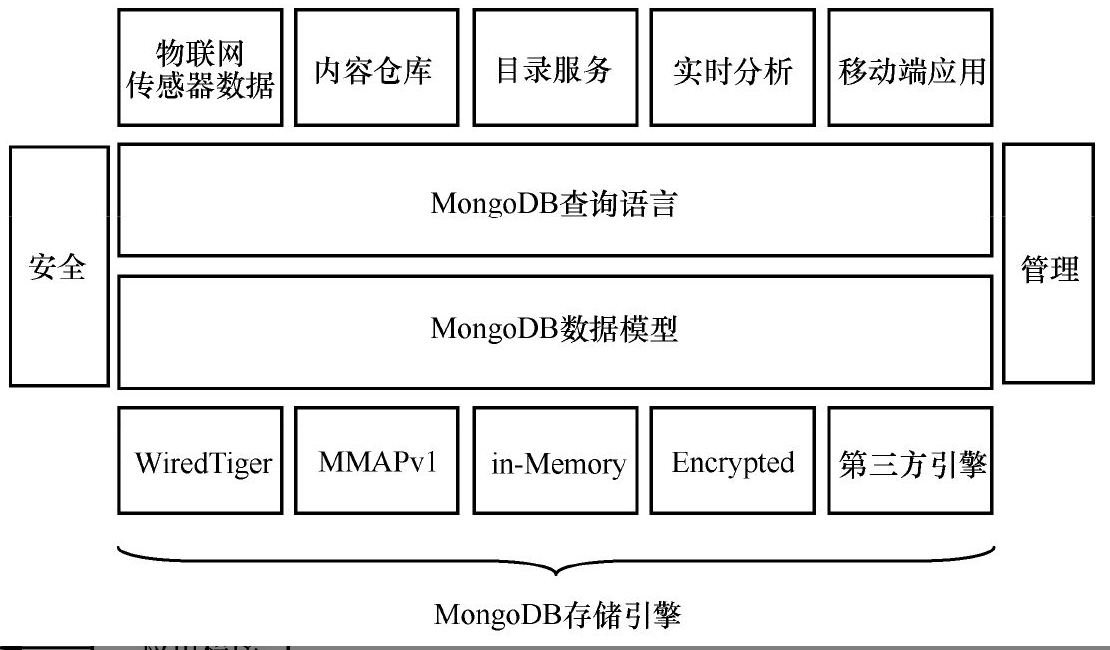
例如构建一个数字图书馆,如果用传统的RDBMS,则至少需要对书名、作者等相关信息使用多个正则化的表结构进行存储,在进行数据检索与分析时则需要频繁且昂贵的表join操作。而MongoDB中只需要通过对JSON(MongoDB中称其为BSON)描述的文档型数据结构进行一次读操作即可完成。对于提高性能以及在商用硬件上的扩展而言,MongoDB的优势不言而喻,同时MongoDB也兼顾了关系数据库操作习惯,例如它保留了left-outer join操作。MongoDB架构如图2所示。在体系架构设计上,MongoDB支持WiredTiger(默认引擎)、MMAPv1(内存−硬盘映射引擎)、in-Memory(内存引擎)、Encrypted(加密存储引擎)以及第三方引擎,并在其上提供了基于BSON的文档型数据结构模型及检索模型。
(2)Cassandra
Cassandra是目前最流行的宽表数据库,最早由Facebook公司开发并开源。Cassandra是Facebook公司受到谷歌公司的高性能存储系统BigTable(基于GFS等技术,服务于MapReduce等任务)的启发而来的。它的特点是:
①无特殊节点(如主、备服务器),因此无单点故障;
②服务器集群可跨多个物理数据中心,不需要主服务器的异步同步功能支持。Cassandra集群读写同步如图3所示:
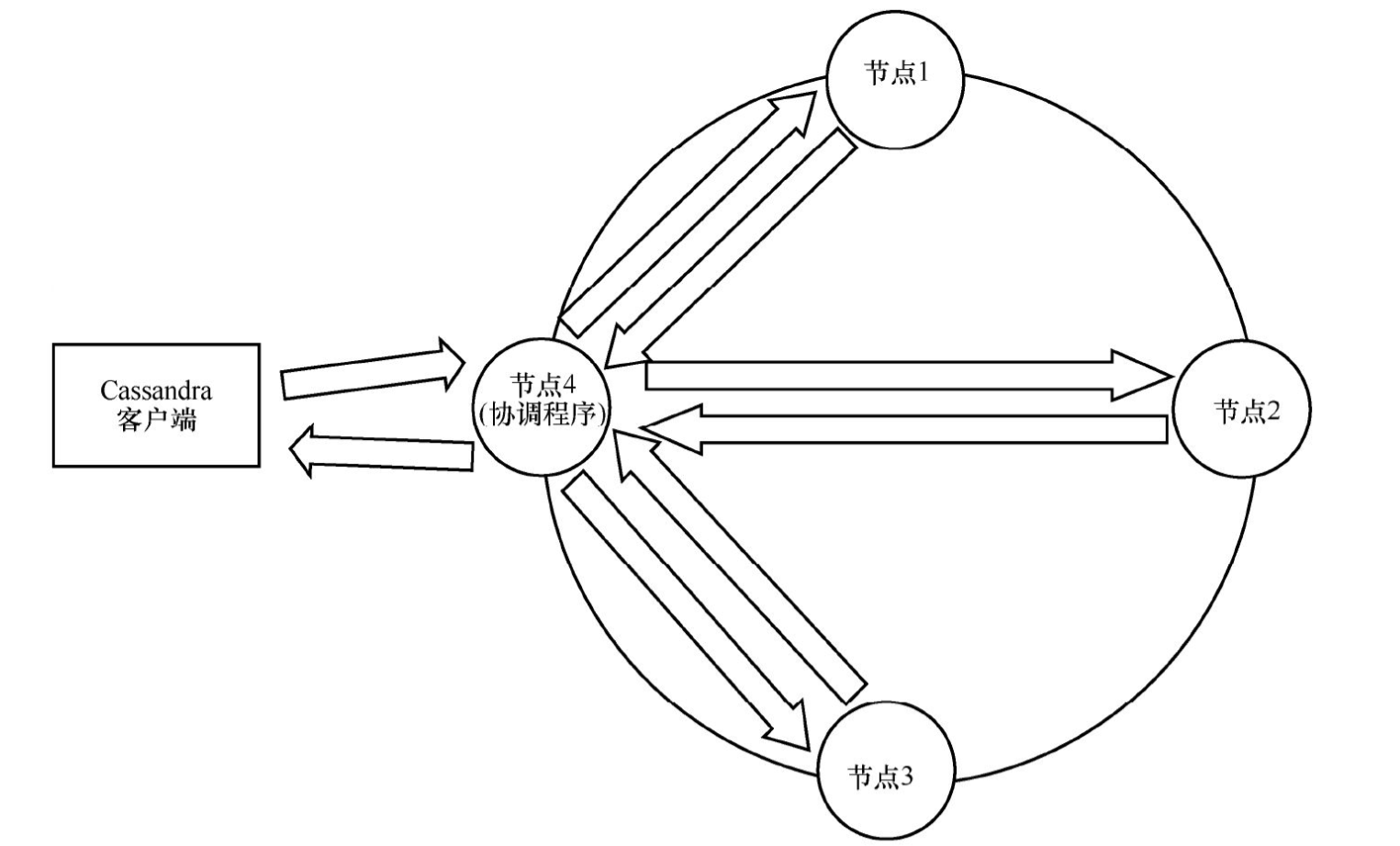
Cassandra系统中有几个关键概念:
①数据分区与一致性哈希运算:鉴于Cassandra的核心设计理念是一个逻辑数据库中的数据由所有集群中的节点分散保存,也就是所谓的分区。
数据的分布式保存会带来两个潜在问题:一个是如何判断指定的数据被存储在哪个节点之上;另一个是在增加或删除节点时如何尽量减少数据的跨节点移动。这两个问题的解决方案就是通过持续的一致性哈希运算(即实现对Cassandra分区的索引)。
②数据复制:无共享架构、避免单点故障都是通过对数据进行多份复制(类似于拷贝)来实现的。
③一致性级别:在Cassandra系统中可以定制一致性级别,也就是说需要多少个节点返回读写操作的确认。在图3中,如果一致性级别为3,那么节点1~节点3全部回复确认后,节点4(协调程序)才会回复Cassandra客户端。
业界对于Cassandra的使用相当广泛,大部分用它提供数据分析服务,甚至进行实时数据分析及流数据处理。还有些公司(例如推特公司)试图用Cassandra全面取代MySQL,不过这一尝试并未获得成功。而Facebook公司本来最早用Cassandra来做邮箱搜索,后来因为最终一致性的问题换成了HBase,不过这丝毫不影响业界对Cassandra趋之若鹜。Cassandra一直宣称是NoSQL数据库中线性可扩展功能做得最好的,目前已知全球最大的部署商用Cassandra的公司是苹果公司,有超过10万个节点和10PB量级的数据对其地图、iTunes、iCloud+服务进行管理与分析。
(3)Redis
Redis是由早期的键值数据库发展而来的,因此即使目前它已经支持更为丰富的数据结构类型(如列表、集合、哈希表、比特数组、字符串等),也依然被大家看作一种基于内存(高速)的键值数据库。
Redis区别于RDBMS的关键在于不需要数据库索引,而是通过主键检索实现数据结构与算法,因此Redis适用于快速查询、检索类操作(特别是以读操作为主的应用)。和其他NoSQL数据库一样,Redis也具有横向扩展性。
图4展示了Redis跨数据中心架构,每个数据中心可以就近满足客户应用的SLA访问时间需求(如响应时间小于或等于200ms),这样的设计特别适合于以读操作为主的应用。
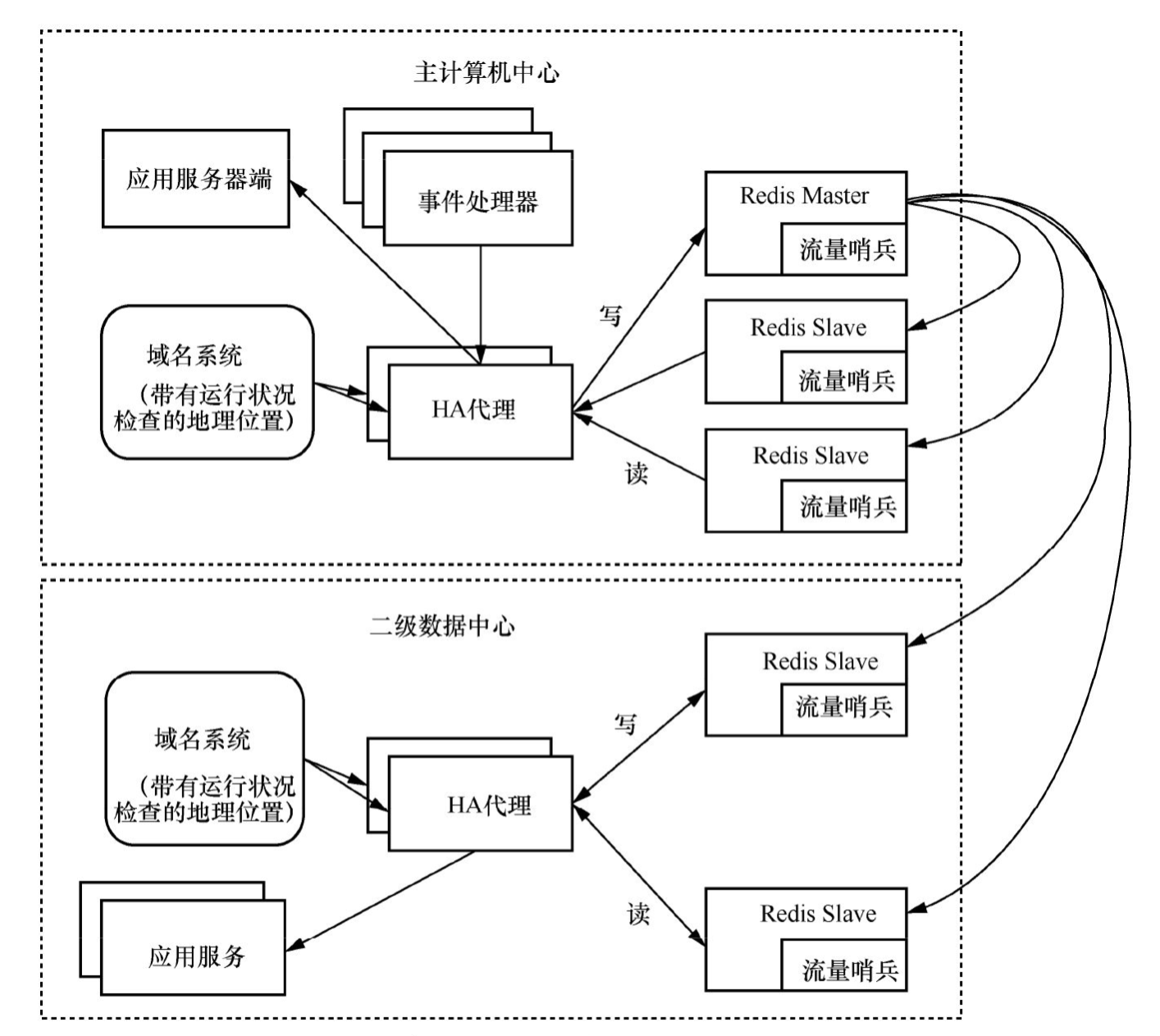
以车票与机票查询为例,通过地点、时间这些键值可以快速查询到车次、航班以及它们的剩余座位,键值数据库可以实现比RDBMS高出数倍甚至上千倍的检索效率。以中国铁路12306网站为例,它们用一款叫作Gemfire XD的商用键值数据库取代了之前的IBM DB2关系数据库,在PC服务器集群上实现了高出小型主机查询效率数百倍的提升。
Redis的应用场景主要有3类:
①缓存:由于Redis支持过期数据,可以让过期数据被新数据替换。对于不需要永久在内存保存数据的应用来说,这样可以节省大量的内存空间。Redis的性能好,可以和Memcached结合用作缓存。
②简单消息队列:Redis支持简单的Pub/Sub模型,以及基于列表的队列模型,所以可以用于构建轻量级的消息队列。
③高性能数据访问:通常一个Redis实体可以满足每秒50万次的访问需求。由于Redis是单线程实现,因此一台主机上可以启动多个Redis实体,以增加高性能并发访问的服务能力。
(4)Neo4j和嬴图
图数据库这一概念对于行外人士而言具有比较大的误导性,很多人乍听之下以为是图像处理数据库,甚至有一些垂直媒体在做数据库划分时会写成“图形数据库”。
我们以为有必要在这里做一个明确的说明。图(Graph)一词源自图论(Graph Theory),而图形来自Graphics,两者虽然词根相同,但涵义不同——Graph指的是事物的集合及其拓扑结构与关联关系,而Graphics是平面设计或可视化图像,因此,“图形数据库”这种叫法并不准确,这也是一种典型的Lost-in-Translation(翻译缺失)。也许当时命名这一类的数据库时用Topo Graph(可翻译为拓扑数据库)会更准确一些。
图数据库的出现在NoSQL阵营中是较晚的。20世纪90年代初,互联网之父蒂姆·B.李(Tim B. Lee)在提出语义化网络的时候,对整个互联网数据层面的规划就是一张大的节点间相互关联的图。而之后的万维网(World Wide Web,W3C)联盟推出的资源描述框架(Resource Description Framework,RDF)标准是对万维网数据资源间关系的一种描述,但是图数据库真正开始在工业界被应用是2011年后Neo4j的推出,它是一种标签属性图(Labeled Property Graph,LPG)数据库,而RDF标准的数据库因更多被学术界采纳而侧重于解决学术界的问题(例如本体论、知识图谱等问题)。
Neo4j可以算作第一个商用化图数据库,尽管今天我们评价它的时候会批评其架构老化、性能不佳、缺少海量数据或深度下钻的分析能力,但是它提出的不少理念,诸如无索引邻接、图查询语言等,以及这些理念的产品化实现是非常有价值的。无索引邻接,顾名思义是指图数据库中的数据可以使用近邻存储以及无索引访问方式,这对于传统的关系数据库而言,是完全的颠覆!也就是说,如果数据库可以做到无索引邻接,那么它的数据存储和查询效率至少在部分场景中实现了远低于O(N)或O(lgN),甚至达到了O(1)的时间复杂度,因此在图中的搜索、查询、计算的效率可以做到很高,下钻的深度也可以变得更深。
Cypher是Neo4j提出的一种为图数据查询与分析而设计的查询语言。图数据库中的查询与传统SQL类数据库有极大的不同,例如查找图中一个顶点(节点)的朋友的朋友的朋友,这个对于关系数据库而言意味着多次的表连接,这个操作因笛卡儿积的问题而导致SQL查询运行得非常缓慢(如果数据集恰好也较大)且成本很高,但是在图数据库中这个操作用Cypher表达比SQL要直观,而且搜索运算的效率也要远高于关系数据库(注:这类操作在关系数据库的效率比在图数据库的效率普遍慢,后者是前者的1000倍甚至更多倍)。
例如,Cypher语句:
('NodeA')-[:FRIEND]-> ()-[:FRIEND]->()-[:FRIEND]->()表达的是一条以点Node A为起点的3步好友路径。
Cypher并不是图数据库领域唯一的查询语言,还有SPARQL、Gremini、GSQL、UQL等。Gremini受到了Apache Tinkerpop3阵营的拥护,SPARQL顾名思义是从Spark阵营中演变而来的,Cypher因Neo4j的推广被Apache软件基金会接纳演变为OpenCypher。事实上,这些图数据库查询语言都可以被看作图查询语言(Graph Query Language,GQL)的“方言”。
GQL的第一版国际标准已在2024年的4月面市(GQL 国际图语言发布https://zhuanlan.zhihu.com/p/694255765)——这也是全球数据库领域在SQL标准之外唯一的一种语言标准,由此可见图数据库被寄予了很大的期望。
前文我们介绍了Neo4j的特点和出现背景,下面再看一下其工程实现的效果。Neo4j的核心引擎是用Java实现的,也就是说在运行时它是跑在Java虚拟机(JavaVirtual Machine,JVM)之上的,整个内存、堆的管理等一系列效率问题由此而生。我们无意挑起关于Java性能的论战,但是有很多业界的场景值得探讨。
①高性能:在大图中如何做到实时计算或查询。一个基于批处理理念而生的系统如何能提供高性能(实时)的服务呢?Neo4j虽然宣称无索引邻接,但是依然在很多地方需要通过构建索引来实现加速,这些都是架构层面存在性能瓶颈的表现。
②深度查询:在关联度较高的图当中如何实现实时的深度查询(大于或等于5级的查询)。所谓关联度较高,指的是顶点的平均度数值较高,有超级顶点(热点)存在。而热点穿透或遍历会使Neo4j或任何Java类系统的效率大幅降低、运行时耗升高。
③高并发与并行化执行:高并发在图数据库领域中是一个很特别的挑战,这是因为图数据库支持高维查询计算与分析,每个查询的计算复杂度非常高。高并发也包括如何对单一查询通过并行化执行来实现加速,而Neo4j的并行化程度是较低的。大多数查询与计算是通过单线程串行的方式执行,最大并发规模只能做到4线程并行。事实上,在商业化环境部署中,Neo4j系统经常出现上千个查询排队等待处理的问题,这个问题与系统整体性能和架构设计及代码实现的并发规模不够直接相关。
④系统稳定性:当在高负载、高复杂度查询、较高并发条件下,系统保持稳定运行的能力。
⑤系统资源消耗或性价比问题:JVM垃圾集等问题导致系统对内存的需求非常大,回收不及时,并且难以控制。此外,系统在运算每一个查询时所需的时间、空间复杂度的问题也是存在的,因为图查询经常是高维的、递归的、单一的复杂查询请求(例如查询某个顶点的全部多步邻居集合,或两个顶点间的全部最短路径数量),如果每一步的复杂度都较高,那么整体的查询复杂度就会呈指数级升高,直至系统失控(内存溢出、死机或无法返回)。
Neo4j在解决以上几个问题时遇到了很大挑战。当然,一部分原因是因为它有社区版本(注意并不是开源版本,Neo4j的底层代码从来没有开源过,其社区版中只是服务层的代码可以被访问。拿社区版进行商业化使用的行为实际上是一种侵权行为)和企业级版本之分,而前者毫无疑问并没有(或者是有意而为)去解决以上问题。这也是开源社区都要面对和思考的,一款优异的产品特别是新产品,如果有明确的商业化道路可以遵循,那么还有什么理由去打造一个开源的版本,使其性能、功能与商业版本没有差异呢?开源版本的稳定性不仅滞后于商业版本,而且需要持续的时间不断迭代才可能获得。MySQL在今天能如此之稳定,是因为其走过了20年的发展历程。反观后起之秀MongoDB,虽然它的用户数量在过去几年间快速增长,用户群体亦相当庞大,但它依然存在很多“陷阱”。尤其对于很多在成长中与其绑定的开发团队而言,他们面临着极大的挑战。这个时候反而是商业化的版本更能应对团队当下甚至未来相当长一段时间内的挑战。
当越来越多的企业与开发者在使用Neo4j类的基于批处理理念而构建的图数据库在遇到问题的时候,他们就会转而寻找性能更优异的实时图数据库产品或解决方案,嬴图数据库即在这样的背景下应运而生。
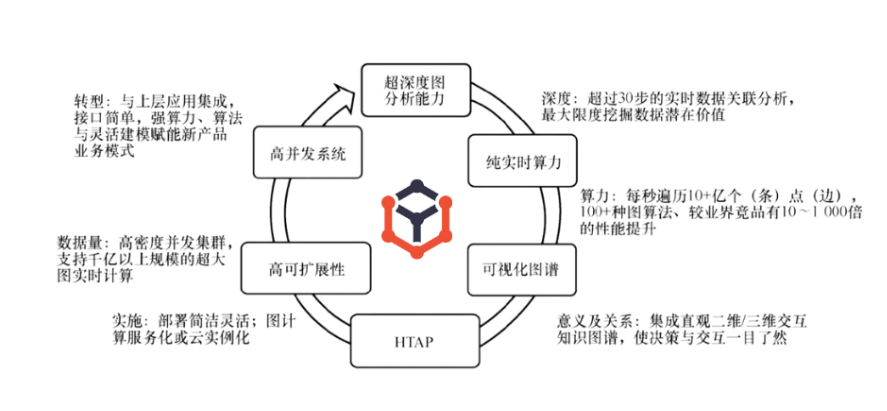
①纯实时算力:在大图当中依然可以做到微秒级的纯实时计算。
②超深度图分析能力:在复杂的大图当中支持超过30步的深度搜索、查询与计算,以及对超级节点的实时穿透能力。
③高并发系统:支持高密度并发计算,能满足互联网级产品支持海量并发用户请求的需求。换句话说,就是能把很多之前的复杂或批处理类型的请求转换为高并发请求以实时或近实时(秒级以内)完成。
④高可扩展性:采用线性可扩展的体系架构。
它有两个维度,一个是数据存储量的线性扩展,另一个是随着硬件资源的叠加而迸发出来的并发处理效率的线性增加(处理时间线性缩减)。
此外,嬴图数据库内置图计算、图存储、图查询语言、全文搜索及索引等引擎,避免了庞大的大数据、数据仓库/数据湖集群动辄几十台甚至上百台机器的部署规模,完全避免了效率低下、运维复杂的尴尬境地。
⑤HTAP:在同一个部署集群内融合了OLTP+OLAP场景。
简单而言,在一个集群内即能够处理纯实时的OLTP类型的面向元数据的增删改查操作,也通过分布式共识算法实现了集群内的数据一致性,进而让部分集群实例可以同时处理更为复杂的OLAP类请求(并可以把大量OLAP类请求优化加速为实时或近实时处理)。
⑥可视化图谱:集成二维/三维交互图谱,通过低代码、表单化,以所见即所得的方式实现上层业务到底层技术的全贯通。
同时,原生高性能图数据库对建设知识图谱的意义在于它颠覆了传统基于SQL或NoSQL(例如文档数据库)构建图谱时的低算力、低时效性等缺陷,具备计算高效实时、数据建模灵活、查询(计算)过程、结果可解释性(白盒化)等优势。
在NoSQL数据库的阵营中,图数据库解决的最重要的问题是深度数据间关联性挖掘,例如以下这些行业场景。
①风控:发现欺诈团体间的关联关系(环或链路),发现已知黑户与新户间的潜在关联。
②反洗钱:发现多个账户间的(深度)关联关系、资金流的流向等。
③扫黑除恶和刑事侦查:发现社区、多个(海量)账户间的潜在网络关系。
④知识图谱:发现图谱中节点变动的影响范围,或定量查询任意节点间的关联。
⑤智能化网络管理:发现任何节点故障的网络化影响,智能定位故障节点。
⑥供应链管理与分析:发现任意故障、时延对网络的整体影响或定向、定量影响。
⑦智慧经营:预算、定价、考核、流动性分析、资产负债管理、司库管理。
前3个场景的一个共同特点是利用图数据库发现长链路或环,英文中其表述为Crime Ring(犯罪环路或犯罪链条,可译为欺诈链条,在银行业务中常演变为像担保链、担保环的场景)。这在风控的领域中是普遍的诉求,而用传统的关系数据库或其他类型的NoSQL数据库或基于机器学习、深度学习或Spark类的大数据架构并不能有效解决这些问题,而图数据库几乎就是为此而生的。
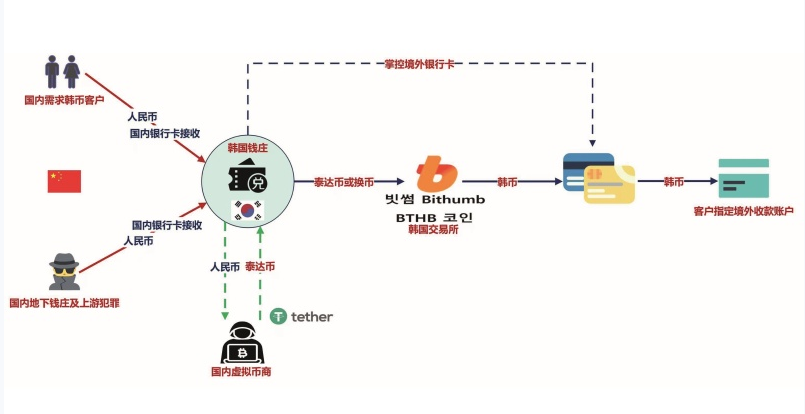
后面4个场景的共同特点是通过对大量的数据、风险因子、维度进行聚合、关联、穿透计算,发现蝴蝶效应、涟漪效应,在网络中计算任意节点间的关联关系或者是某个节点或多个节点的影响力范畴、波及范围,这在风险管理、审计、风控、经营、资产负债管理等多个领域中是颇为常见的,但关系数据库、数据仓库、数据湖却无法满足此类业务诉求。

下图中的5层反欺诈模型是著名咨询公司Gartner提出的,它同样适用于所有的数据分析、商业智能等依托大数据分析的场景。目前,数据分析(及商业智能)在业界经历了5个层次的发展。
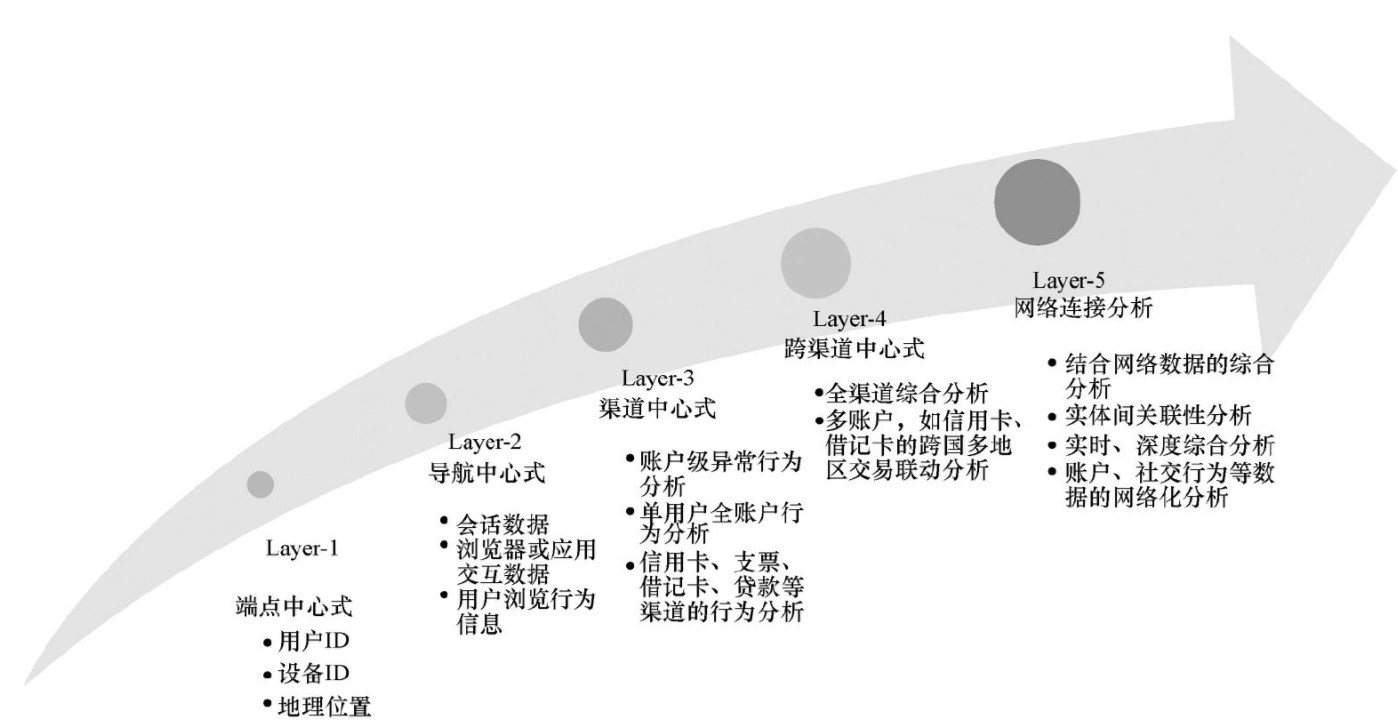
①端点中心式:最初的数据分析是以端点为中心的。例如,仅关注当前用户的一次的用户行为分析,它并不关注前后行为的关联。
②导航中心式:也称会话分析模式,把一次用户会话的行为整合分析。
③渠道中心式:更全面的分析,例如一个信用卡(渠道)用户长期在渠道内的行为分析。这个是目前业界的“最佳”实践所处的位置。
④跨渠道中心式:这是业界的“金标准”。例如分析一家银行的用户的跨渠道行为,从信用卡到借记卡到外汇业务、贷款业务等综合型多渠道数据的整合分析。
⑤网络连接分析:网络化分析也称作社交网络化分析,它在跨渠道的基础上关注用户的社交行为数据的关联分析,例如电话、短信、社交网络数据等综合数据。
⑤网络连接分析:网络化分析也称作社交网络化分析,它在跨渠道的基础上关注用户的社交行为数据的关联分析,例如电话、短信、社交网络数据等综合数据。
2.NewSQL数据库
下面聊一聊颠覆了CAP理论的NewSQL数据库(兼具可扩展性、数据可用性与一致性)。确切地说NewSQL数据库可以兼顾OLTP和OLAP,但在一般分类上,我们还是主要突出它在交易、事务处理方面对ACID的支持,因此将其归到OLTP阵营。
最早的NewSQL数据库管理系统是H-Store,由美国东海岸的4所大学(布朗大学、卡内基梅隆大学、麻省理工学院和耶鲁大学)在美国国家科学基金会、加拿大自然科学与工程研究委员会及英特尔大数据科技中心的资助下联合开发,于2007年面世。H-Store的开发够早,要知道NewSQL这个词汇是2011年才出现的(451group分析师Matthew Aslett于2011年在一篇文章中首次提及)。
H-Store显然是一个学院派的NewSQL数据库管理系统,离商用还有相当长的距离,于是基于H-Store的商业版NewSQL数据库——VoltDB应运而生。VoltDB的开发者都是业界赫赫有名的大家,比如迈克尔·斯通布雷克(Michael Stonebreaker),他在加利福尼亚大学伯克利分校任教期间开发了Ingres、Postgres等关系数据库系统;后来到麻省理工学院任教,又开发了C-Store、H-Store等系统。他的学生也多是赫赫有名之辈,比如VMware公司前人力资源专家戴安娜·格林(Diane Greene)、Cloudera的创始人迈克·奥尔森(Mike Olson)、Sybase的创始人罗伯·爱博斯坦(Robert Epstein)等。要提一点,迈克尔·斯通布雷克老先生是1943年生人,反观国内的研发人员不到30岁就纷纷转型做经理,或35岁就被迫面临职场压力甚至被迫淘汰……实在是令人唏嘘。没有持续多年的第一手技术累积所搭建出来的系统是很难经得起时间的检验的,我们写下这段文字,与读者共勉!
业界最早的商用NewSQL数据库是谷歌公司经过5年内部开发后于2012年面世的Spanner,它具有以下4个特性:
①具有ACID强一致性(用于交易处理)。
②支持SQL语言(向后兼容)。
③支持模式化表。
④半关系数据模型(意味着支持数据多样性)。
Spanner是第一个在全球范围内可以做到交易一致性的半关系数据库,也就是说在各个大洲数据中心之间的数据可以通过Spanner实现读写同步。Spanner主要用于服务谷歌公司最赚钱的广告系统,而之前该系统是构建在一套相当复杂的分片化MySQL集群之上的。谷歌公司的Spanner显然是在NoSQL数据库——BigTable之上的一次飞跃。
Spanner立足于高抽象层次,使用Paxos协议横跨多个数据集,把数据分散到世界上不同数据中心的状态机中。当出现故障时,它能够在全球范围内响应客户副本之间的自动切换。当数据总量或服务器的数量发生改变时,为了平衡负载和处理故障,Spanner会自动完成数据的重切片和跨机器甚至跨数据中心的数据迁移。
区别于以往的已知NoSQL数据库或分布式数据库,Spanner在技术架构上具备如下特点。
①应用可以细粒度地进行动态控制数据的副本配置。应用可以详细规定:哪个数据中心包含哪些数据,数据距离用户有多远(控制用户读取数据的时延),不同数据副本之间距离有多远(控制写操作的时延),以及需要维护多少个副本(控制可用性和读操作性能)。数据可以动态、透明地在数据中心之间移动,从而平衡不同数据中心内资源的使用。
②读写操作的外部一致性,时间戳控制下的、跨越数据库的、全球一致性的读操作。
Spanner这两个重要的特性使得Spanner可以支持一致性的备份、一致性的MapReduce执行和原子性的模式更新,所有这些都是在全球范围内实现的,即使存在正在处理中的事务。
Spanner的全球时间同步机制是由一个具有全球定位系统(Global Positioning System,GPS)和原子钟的TrueTime API提供的。TrueTime API能够将不同数据中心的时间偏差控制在10ms内,可以提供一个精确的时间,同时给出误差范围。TrueTime API直观地揭示了非全球原子时钟的不可靠性,它运行/提供的边界更决定了时间标记。如果不确定性很大,Spanner会降低速度来等待不确定因素的消失。
TrueTime技术被认为是Spanner可以实现跨大洋数据中心的交易强一致性的使能技术,通过它可以实现无锁编程的只读交易、两阶段锁定写交易。图9展示的是分别位于美国、巴西与俄罗斯的3个数据中心间实现并发读写交易一致性的时序图。
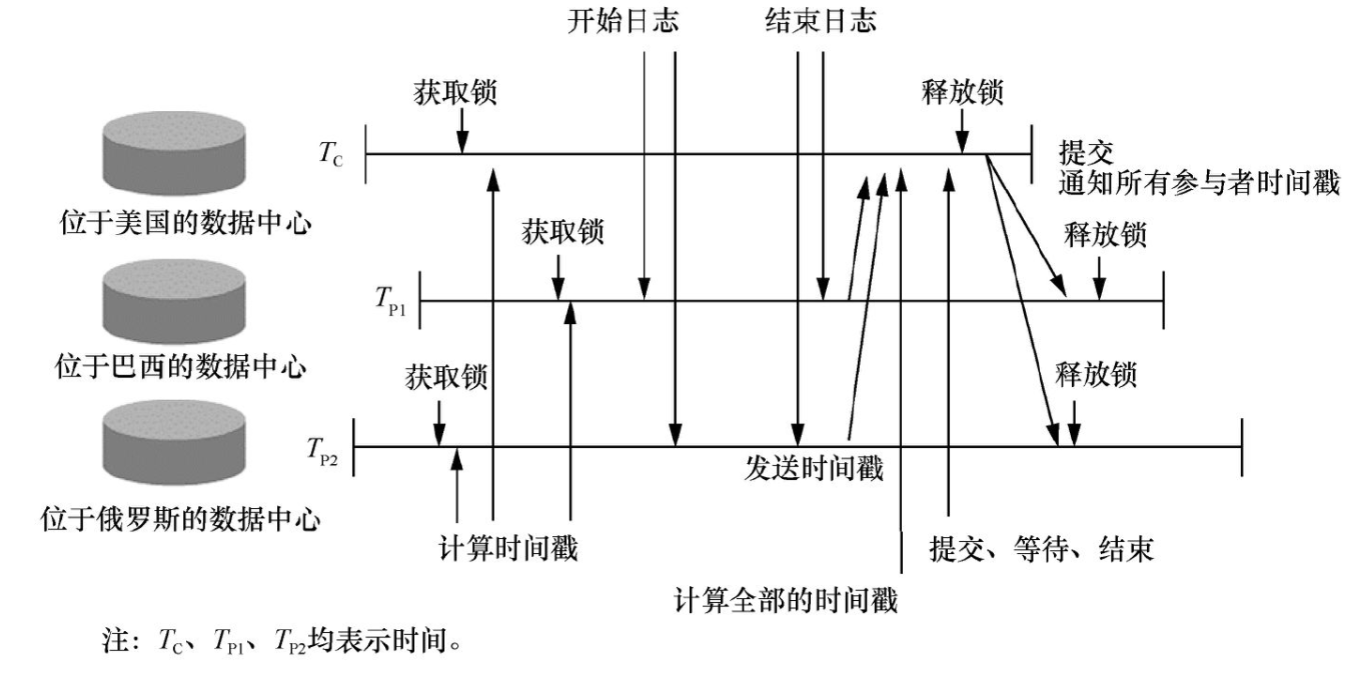
Spanner中还有一些引领业界潮流的架构设计,具体如下:
①一个Spanner部署实例称为一个Universe。而谷歌公司在全球范围内只用了3个实例:一个开发实例、一个测试实例、一个线上实例。因为一个Universe就能覆盖全球,所以谷歌公司认为他们不需要更多实例了。
②每个Zone相当于一个数据中心,一个数据中心可能有多个Zone,而一个Zone在物理上必须在一起。Zone可以在运行时被添加或移除。一个Zone可以理解为一个BigTable部署实例。
其他业界知名的NewSQL数据库还有如下几个:
①Clustrix Sierra:一家旧金山的创业公司的产品。Percona团队曾对其做过测试,发现其一个拥有3个节点的集群比一个同等处理能力的单节点MySQL服务器的性能高73%,并且Clustrix Sierra的性能随节点数的增加呈线性增长。
②Gemfire XD:是一款Pivotal公司基于内存的IMDG产品,和基于内存的数据库的主要区别是其强大的可扩展性(通常可以扩展到几千个节点),尽管它也能提供部分SQL访问接口,但更多的是为了实现高性能计算和实时交易处理。经典应用场景如中国铁路12306网站车票预订系统的后台就是由10对(20台)X86服务器搭建而成的Gemfire XD IMDG——每天14亿次页面浏览量,每秒超过4万次访问量,服务超过5700个火车站。
③SAP HANA:恐怕是业界最为知名的商用NewSQL数据库了。这是一款完全基于内存的关系列数据库,支持实时的OLAP与OLTP。SAP公司为了推出HANA,前后购买了多家公司的核心技术,其中至少有3个技术值得一提:基于内存TREX列搜索引擎、基于内存的P*Time OLTP数据库,以及基于内存的liveCache引擎。SAP HANA的战略重要性如此之高,SAP公司似乎把全部“赌注”压在其上了。整个业界对实时性、低时延越来越高的期待似乎与SAP公司的“赌注”颇为吻合。
目前,SAP HANA的客户量每年以翻倍的速度增长,而整个SAP公司的云计算+大数据分析战略似乎都围绕着SAP HANA在构建。
像这样的NewSQL数据库还有很多,我们在此不再赘述,有兴趣深究的读者可以自行展开研究。
OK,就此打住,已经是万字长文了,希望在被短视频投喂或热衷于碎片化知识的时代,还有人热爱深度阅读!下一篇我们接着叙ALAP! 88!
(文/Ricky - HPC高性能计算与存储专家、大数据专家、数据库专家及学者)
· END ·


















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









