




老夫之前就讲过,大数据一般被分为四大阵营,流数据管理就是其中之一。
感兴趣的朋友,可以点击以下文章进行温故知新:
阵营一: 揭秘大数据 | 15、OLTP 的那些事儿-优快云博客
阵营二: 揭秘大数据 | 16、OLAP 那些事儿-优快云博客
阵营三: 揭秘大数据 | 17、MPP 那些事儿-优快云博客

数据流管理来自这样一个概念:数据的价值随着时间的流逝而降低,所以在事件发生后需要尽快对其进行处理,最好是在事件发生时就进行处理(即实时处理),对事件进行一个接一个的处理,而不是缓存起来进行批处理(如Hadoop)。
在数据流管理中,需要处理的输入数据并不被存储在可随机访问的磁盘或逻辑缓存中,它们以数据流的方式源源不断地到达。
数据流通常具有如下特点:
①实时性:数据流中的数据实时到达,需要实时处理。
②无边界:数据流是源源不断的,大小不定。
③复杂性:系统无法控制将要处理的新到达数据元素的顺序,无论这些数据元素是在同一个数据流中还是跨多个数据流。
流数据处理阵营有两类解决方案:
①流数据处理:Spark Streaming、Storm、Apache Flume、Flink等。
②复杂事件处理与事件流处理:Esper、SAP ESP、微软公司的StreamInsight等。
在介绍这两类解决方案前,我们先温习一下大数据处理的两种通用方法:MPP与MapReduce。这两种方法的共同点就是采用分而治之的思想,把具体计算迁移到各个子节点,主节点只承担任务协调、资源管理、通信管理等工作。
通过这种方式,集群的处理能力往往和节点数量线性相关,面对海量数据,自然也游刃有余。针对海量数据,这两种方式都强调计算要发生在本地,也就是说,在分配任务的时候,尽可能让任务从本地磁盘读取输入。
不过,在流处理的应用场景下,这两种处理方式都遇到了不可克服的困难:
一方面,当数据源源不断地流入系统时,不同时间段数据产生的频率和分布都有可能发生很大的变化,但是系统对数据的这种变化的理解有限,很难有效地进行预测,难以发展出有效的分治算法。其次,常用的方式是批处理,也就是说,系统创建特定任务来处理给定的数据,处理完毕以后,任务就结束了。用这种批处理的方式来处理流数据,显然不合适。
另一方面,流处理系统的适用场景往往对系统反应时间有苛刻的要求,比如,高频交易系统需要在极短的时间内完成计算并做出正确的决定,MPP与MapReduce面对这个挑战都难以胜任。
人们也试图在这两种方式的基础上开发出适合流数据的系统。比如Facebook在开发Puma的时候,一个没有被最终采用的设计方案就是把源源不断产生的数据都保存到HDFS中去,然后每隔特定的时间(比如1min)创建一个新的MapReduce任务来处理新的数据,从而得到结果。种种权衡之后,这个方案没有被采用,一个可能的原因是这个方案还是不能保证系统的低时延(不能在指定时间内返回相应的结果)。
为此,工业界开发了不少分布式流计算平台,在2011—2012年期间影响力比较大的有推特公司的Storm、EsperTech公司的Esper以及雅虎公司的S4。不过后来随着Apache Spark的崛起,一批新的流数据处理架构涌现出来了,如Spark Streaming(Spark Streaming 是 Apache Spark 核心 Spark Core API 的一种扩展,它可以实现对实时数据流的高效处理和分析。它允许从各种数据源(如 Kafka、Flume 等)接收实时数据,并将其分成小的批次(batch)进行处理,就像对静态数据集进行批处理一样。这样可以利用 Spark 的强大并行计算能力来处理实时数据,进行实时的数据分析、机器学习等任务)、Apache Flume(Apache Flume 是一个分布式数据收集系统,主要用于从各种数据源收集大量数据,并将其传输到集中的数据存储系统中,如 HDFS)、Apache Flink(Apache Flink 是一个开源的流处理和批处理框架。它可以对有界和无界数据流进行高效的处理和分析。Flink 具有高吞吐、低延迟、支持精确一次的状态一致性等特点。被广泛应用于实时数据分析、事件驱动应用、数据管道等场景)等。
值得一提的是,CEP(Complex Event Processing,复杂事件处理))类型的方案大多为商业解决方案(Esper提供开源版本,不过EsperTech公司的主要是商业版Esper Enterprise),而基于流数据处理架构的解决方案以开源为主。下面我们分别介绍Storm和Esper。
(1)Storm
关注大数据的人对Storm应该不会陌生,Storm由一家叫BackType的公司的创始人南森·马茨(Nathan Marz)开发,后来BackType被推特公司收购。Storm于2011年9月17日被开源,并于2013年9月进入Apache软件基金会孵化,2014年9月17日正式成为基金会一级项目。Storm核心代码是由Clojure这种极具潜力的函数式编程语言开发的(Clojure可以被看作Lisp语言的变种,支持JVM/CLR[插图]/JavaScript三大引擎,由于它无缝连接了Lisp与Java,业界认为Clojure兼具美学和实用特性,从而一经面世便流行开来),这也使得Storm格外引人注目。
Storm体系架构中主要有两个抽象化概念,需要读者先行了解:
①拓扑:可以比作Hadoop上的MapReduce jobs,主要区别在于MapReduce jobs早晚会结束,而拓扑永无休止(流数据的无边界特征),每个拓扑由一系列的Spout(数据源)和Bolt(数据流处理组件)构成[见图1(a)]。
②数据流:数据流由连续的元组构成;在构成拓扑的Spout与Bolt之间流动。Spout负责产生数据(如事件);Bolt可以级联,负责处理接收到的数据[见图1(b)]。
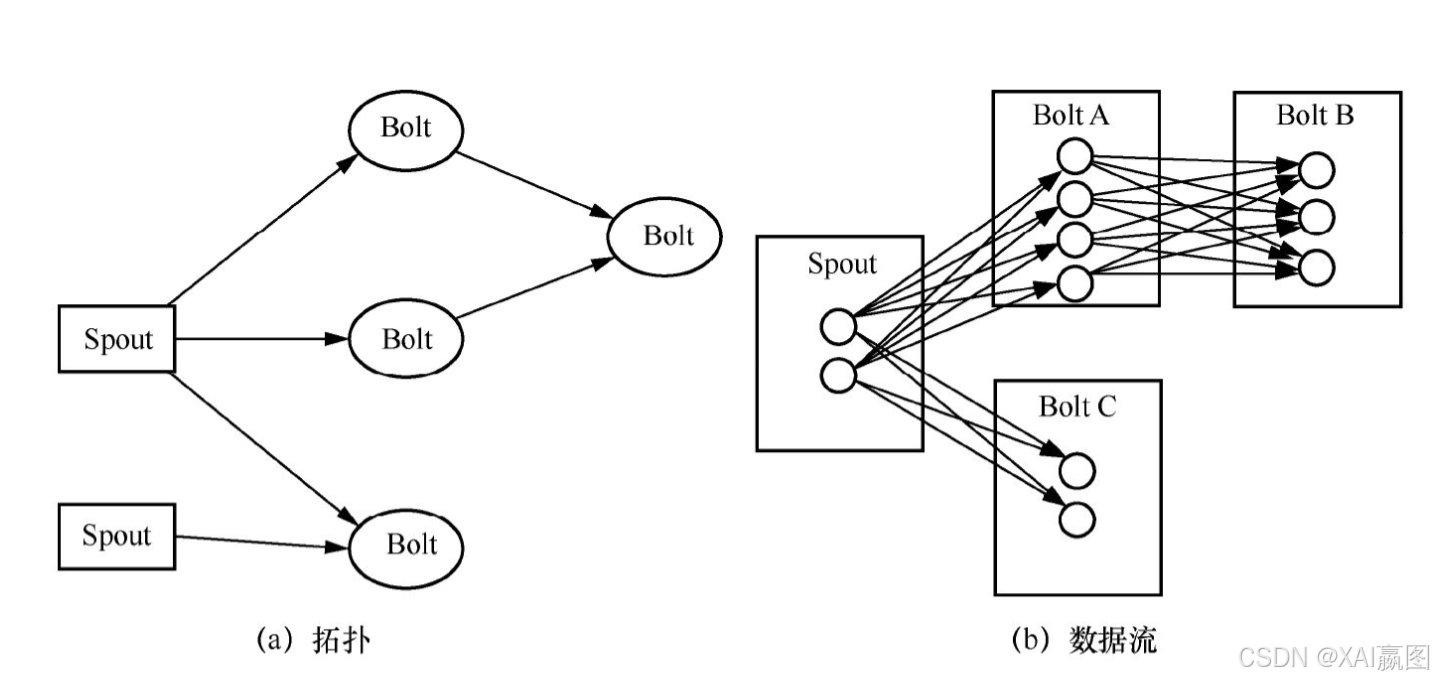
在定义一个Storm拓扑过程中,需要给Bolt指定接收哪些数据流的数据。一个数据流分组定义了如何在Bolt的任务中对数据流进行分区。Storm提供了8种原生的数据流分组:Shuffles、Fields、Partial Keys、Global、None、Direct、Local以及All grouping,其中Shuffles保证事件在Bolt实例间随机分布,每个实例收到相同数量的事件。
Storm集群与Hadoop颇为类似(想必是受到了Hadoop的启发,毕竟大规模分布式大数据处理系统开源之鼻祖是Hadoop,而且它的HDFS与MapReduce的设计相当值得借鉴),由Master节点与Worker节点构成,Master上运行着Nimbus守护进程,类似于Hadoop的JobTracker,负责在集群中分发代码、分配任务、监控集群等。Storm集群组件如图2所示。
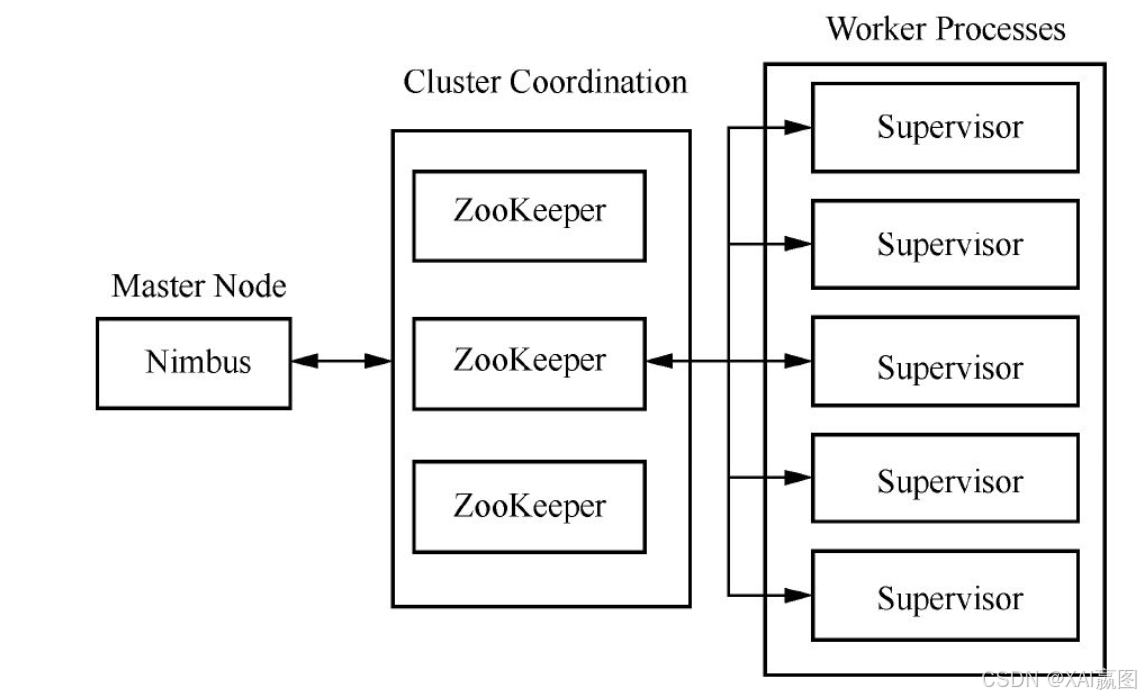
Worker节点上运行的守护进程叫Supervisor,负责接收被分配的任务,启动或停止Worker进程等。每个Worker进程处理一个拓扑的子集,一个拓扑可以包含可能跨多台机器的多个Worker进程。Nimbus与Supervisor之间的协作通过ZooKeeper(Apache ZooKeeper是一套分布式的应用协调服务,提供包括配置、维护、域名、同步、分组等服务)集群来实现。Nimbus与Supervisor守护进程都是无状态且故障自保险的,它们的状态都保持在ZooKeeper或本地磁盘上,就算是终止了Nimbus或Supervisor进程,重启后还会继续正常工作。这样的设计保证了Storm集群的高度稳定性。
(2)Esper
让我们先来看一下CEP方案的设计理念。绝大多数CEP方案可以分为两类。
①面向汇聚的CEP方案:主要对流经的事务数据执行在线算法,例如对数据流进行均值、中间值等计算。
②面向监测的CEP方案:主要对数据流中的数据是否会形成某种趋势或模式进行探测。而我们要关注的Esper则对以上两种方案兼而有之,它是EsperTech公司的CEP产品,其整体架构有三大组件,如图3所示。
①Esper引擎:有Java和.Net(C#)两个版本,.Net版本前面有个N,叫作NEsper。这两种引擎都是开源的。
②Esper核心容器:熟悉Java的读者一眼就可以看出,这是闭源企业版。
③EsperHA:提供高度可用性,也意味着快速故障或死机恢复。EsperHA还支持高性能的写操作。
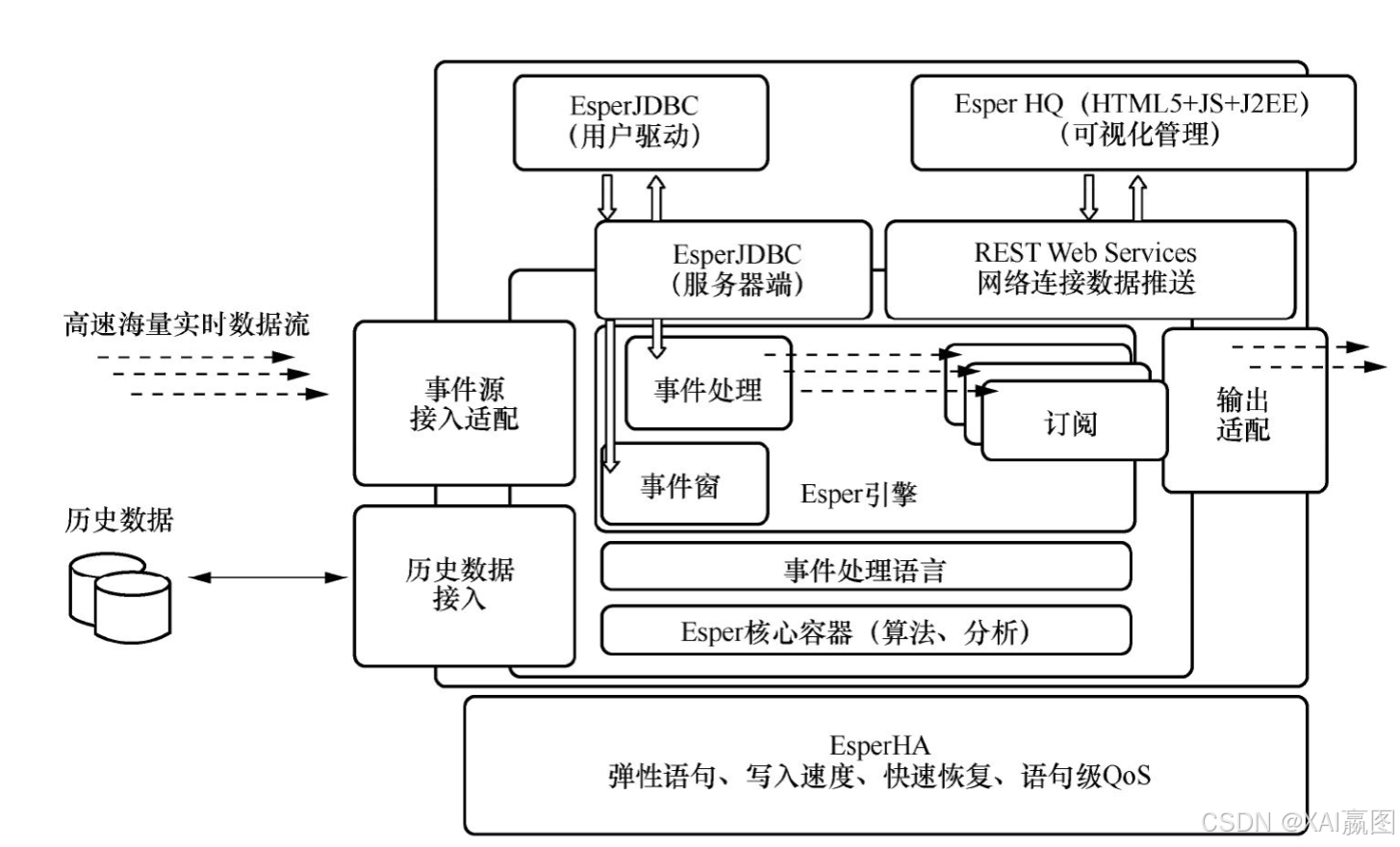
Esper扩展了SQL-92标准,开发了一种私有化语言——事件处理语言(Event Processing Language,EPL),非常适合对时间序列数据进行分析、处理以及监测事件发生,提供聚集、模式匹配、事件窗口、联表等功能。对于熟悉SQL语言的人而言,EPL非常容易上手,例如在Esper中当发现3min内有超过(含)5个事件发生的条件得到满足时要立刻报告,只需要如下简单的操作:
select count (*) from OrderEvent.win:time (3 min) having count (*) >= 5接下来,我们从数据分析的可靠性、运维、成本、实时性、数据规模等维度对NoSQL、Hadoop、RDBMS与流数据处理架构进行比较,如图4所示。
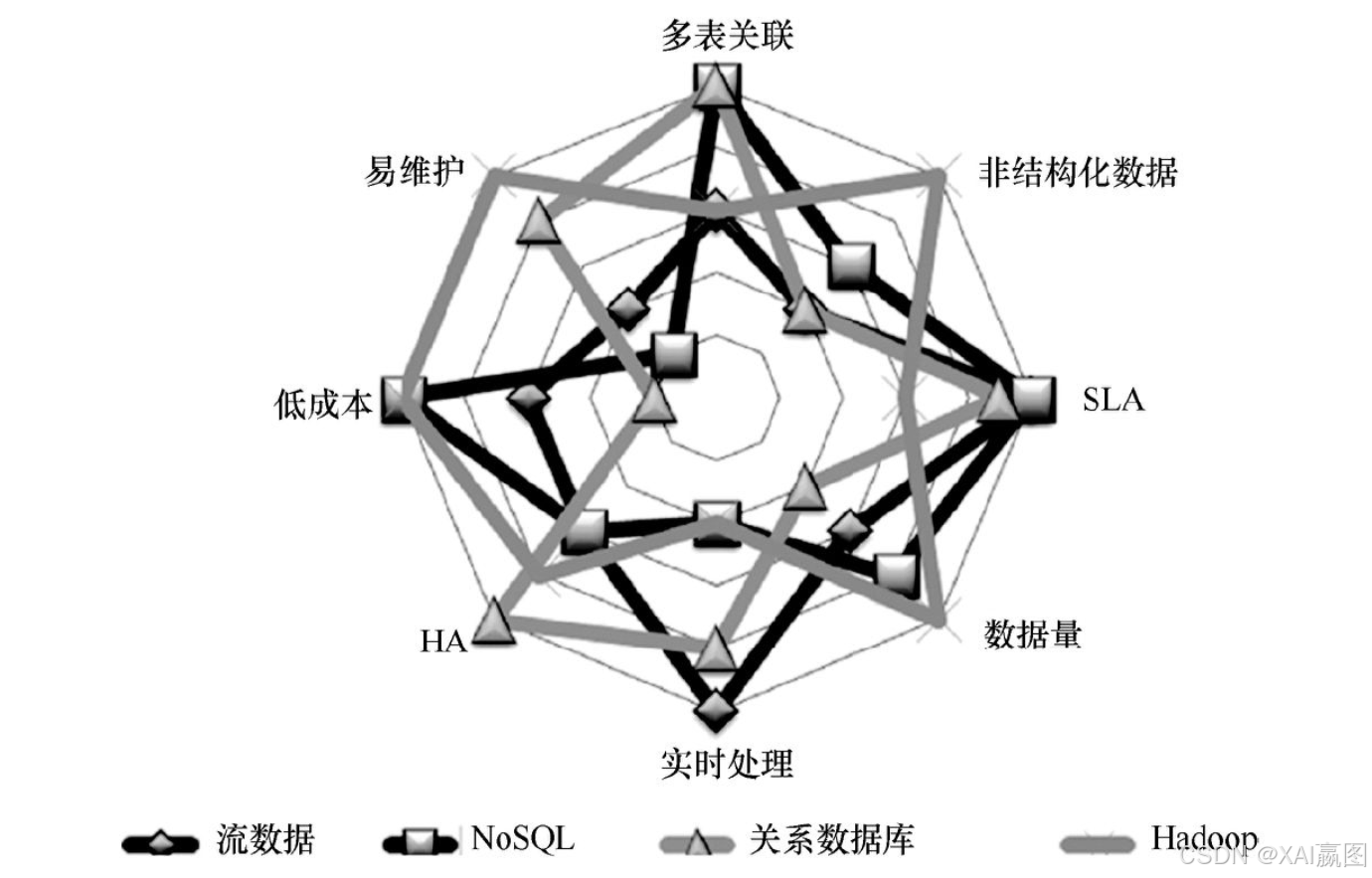
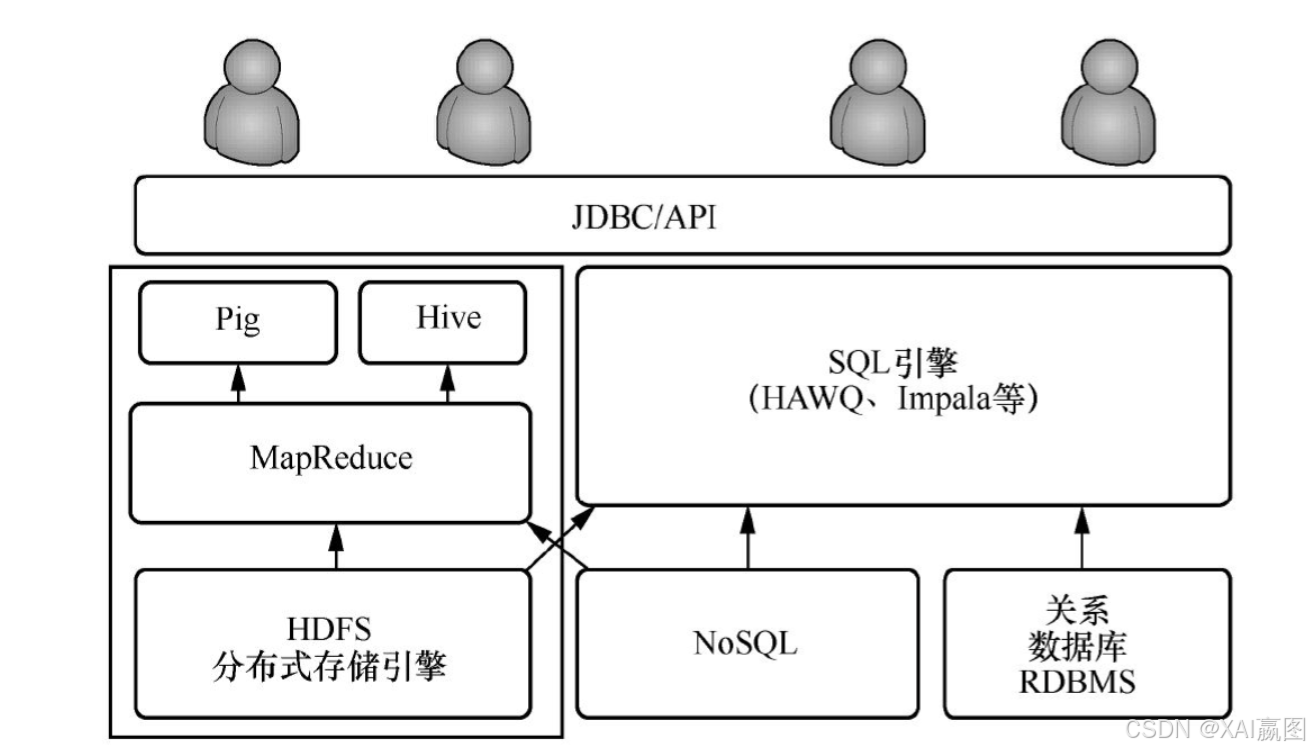
很显然,没有任何一款单一的大数据架构是完美的。数据规模大的架构很难保证系统响应实时性;可以实现复杂的强一致性的系统,其成本必然不会很低,运维起来恐怕也十分复杂。在实践中我们通常会根据业务具体需求与预期,把两种或多种大数据解决方案组合在一起,例如Hadoop的HDFS可以被解耦出来作为一个通用的数据存储层,NoSQL用来提供可交互查询后台,关系数据库依然可以被用来做关系型数据的实时查询……图5展示了一种多方案融合而成的大数据平台架构方案。
OK,到今天这篇为止,关于大数据四大阵营的这个小系列就宣告结束了,希望能给朋友们带来启发,也欢迎大家留言探讨。88!
(文/Ricky - HPC高性能计算与存储专家、大数据专家、数据库专家及学者)
· END ·


















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









