




之前连讲了 OLTP 和 OLAP , 今儿继续聊MPP类数据库。
MPP:
MPP 通常是指大规模并行处理(Massively Parallel Processing)。它是一种使用多个处理器或计算节点同时处理一个问题的计算架构,以实现高性能的计算和数据处理。例如在大数据分析和处理中,MPP 数据库可以将数据分布在多个节点上进行并行处理,从而提高处理速度和效率。
和MapReduce类似,两者都采用大规模并行处理架构对海量数据进行以大数据分析为主的工作,不同之处在于MPP通常原生支持并行的关系型查询与应用(不过这一点,Hadoop阵营也在逐渐通过在HDFS之上提供SQL查询接口来支持查询,甚至包括关系型查询)。
MPP 数据库通常具有如下特点:
(1) 无共享架构:每台服务器有独立的存储、内存及CPU,可以动态增删节点。
(2) 分区:数据分区可以跨多个节点,通过分布式查询优化提高系统吞吐量。
(3) 在OLAP基础上通常支持OLTP类应用。
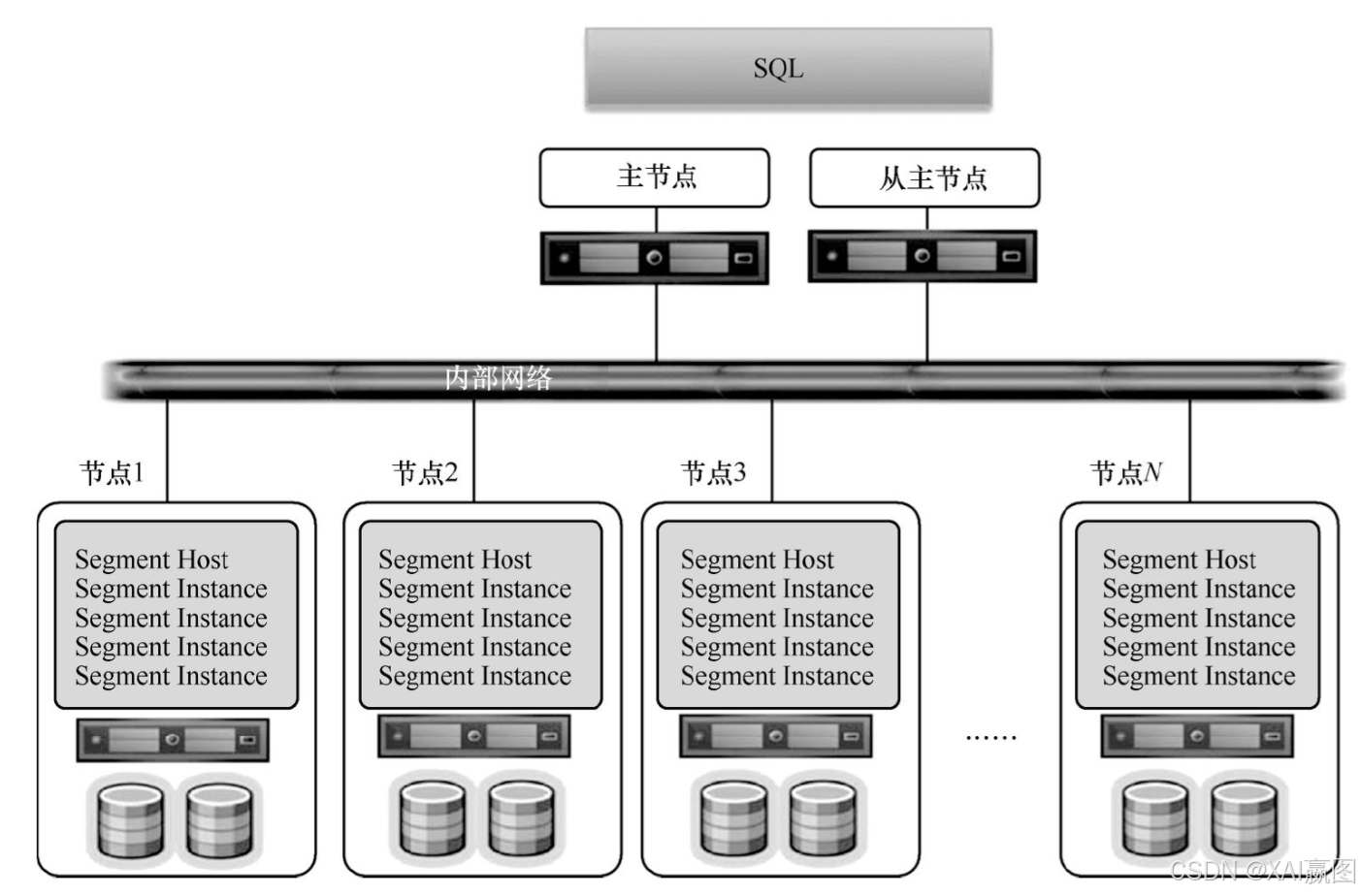
MPP阵营的产品不少,例如Amazon Redshift、Pivotal公司的Greenplum、Teradata的Aster和IBM公司的Netezza。不过除了Greenplum,其他产品全是闭源商业产品。我们以Greenplum为例,介绍MPP数据库的架构设计。Greenplum数据库源自PostgreSQL数据库,由主实例与多个区段实例联网构成,每个实例可以看作一套独立的PostgreSQL DBMS。Greenplum是业界第一个开源的MPP数据库,对想要实现OLTP和OLAP一体化大数据分析与管理系统的人来说,这是个天大的好消息。

Hadoop与MPP阵营存在很多异同,下表列出了它们之间的特征比较。
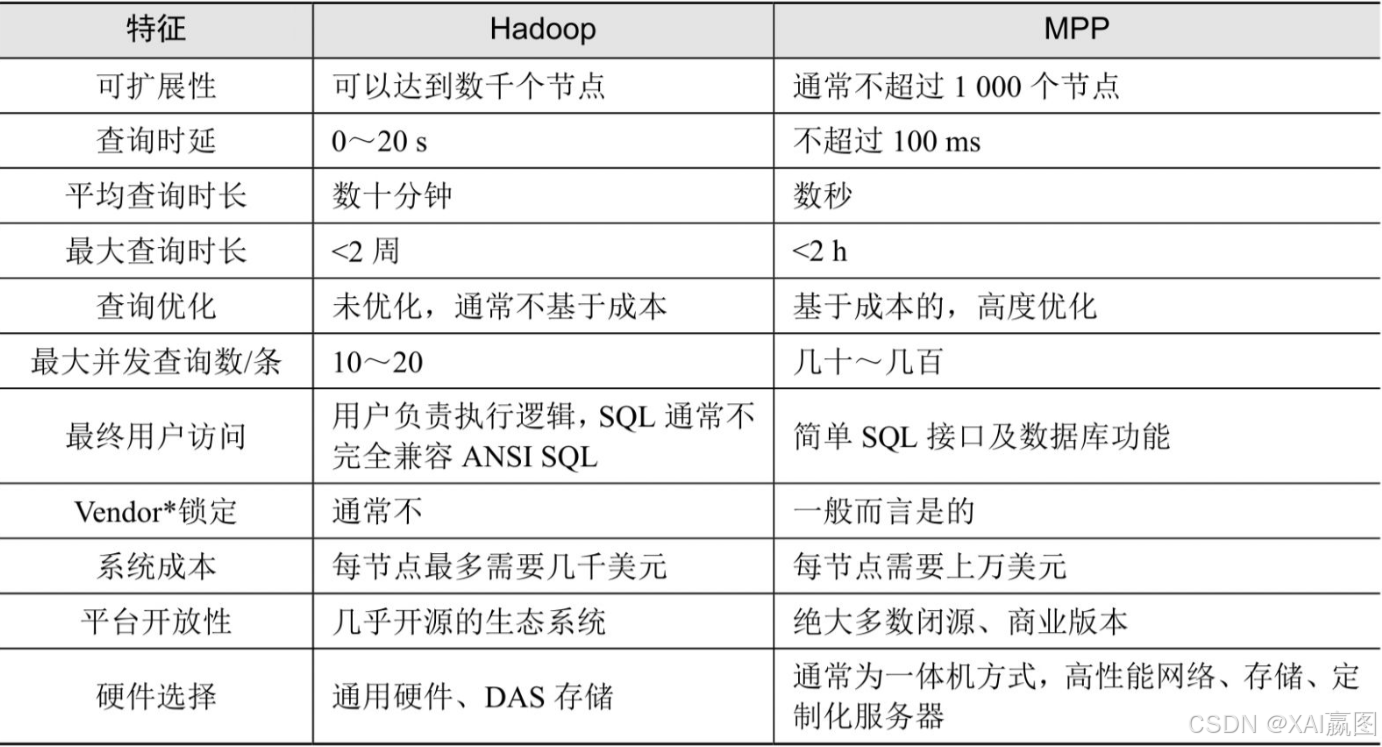
注:*Vendor的英文全称为Vendor Lock-in(供应商绑定),描述的是“因为更换供应商会导致高成本,所以客户只能选择原来的供应商”这种尴尬的局面。
(文/Ricky - HPC高性能计算与存储专家、大数据专家、数据库专家及学者)
· END ·


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









