




注意力机制(尤其是Transformer架构中的点积注意力)的提出是自然语言处理乃至人工智能领域的里程碑式突破:
它从根本上解决了传统序列建模模型(RNN/LSTM等)的核心痛点,既打破了顺序计算的效率瓶颈,实现了序列数据的并行处理,又攻克了长距离依赖难题,让模型能精准捕捉任意位置的语义关联;
其自适应的信息加权能力,使模型摆脱了对输入序列“一视同仁”的局限,可聚焦核心信息、忽略冗余内容,大幅提升了建模精度;
更重要的是,注意力机制重构了序列建模的核心范式,催生了Transformer架构,为BERT、GPT等大规模预训练模型奠定了基础,推动AI从“模式匹配”走向“语义理解”,并从NLP领域延伸至计算机视觉、语音识别、跨模态生成等全场景,成为现代大语言模型和通用人工智能发展的核心基石,同时其可解释的注意力权重可视化特性,也让深度学习模型从“黑箱”走向部分可解释,为模型的优化和信任度提升提供了关键支撑。
一、注意力机制的核心实现:点积注意力机制
什么是点积注意力?
点积注意力(Scaled Dot-Product Attention)是Transformer架构中注意力机制的核心实现方式,由Google在2017年的《Attention Is All You Need》论文中提出。
其核心思想是: 通过计算查询向量(Query)与键向量(Key)的点积,得到注意力权重,再用该权重对值向量(Value)进行加权求和,最终得到注意力输出。
为什么需要"缩放"?
当向量维度d_k较大时,点积结果会偏大,导致Softmax函数梯度消失,因此需要除以√d_k进行缩放。
点积注意力其实就是给 “查询(Query)” 和 “每个键(Key)” 算相似度 —— 俩东西越像,算出来的数越大,对应的注意力权重就越高。但如果 Key/Query 的维度很高(比如几百维),这相似度的数会变得特别夸张(就像一堆数加起来,个数越多总和越容易飙高)。
这时候问题就来了:Softmax 函数碰到这种超大数,会变得 “极端偏心”—— 只死死盯着最大的那个数,其他数哪怕差一点,也会被当成 0 对待(相当于注意力只聚焦在一个地方,其他有用信息全忽略了)。更糟的是,这种情况下模型根本学不动(梯度消失),就像老师只看最高分,完全不管其他学生的进步,没法调整教学方法。
而 “缩放” 就是给这些超大的相似度数 “降温”,把它们压回合理范围。这样 Softmax 就能正常分辨 “哪些该多关注、哪些该少关注”,注意力分布更合理,模型也能踏踏实实学到东西了。
核心计算公式

计算步骤详解
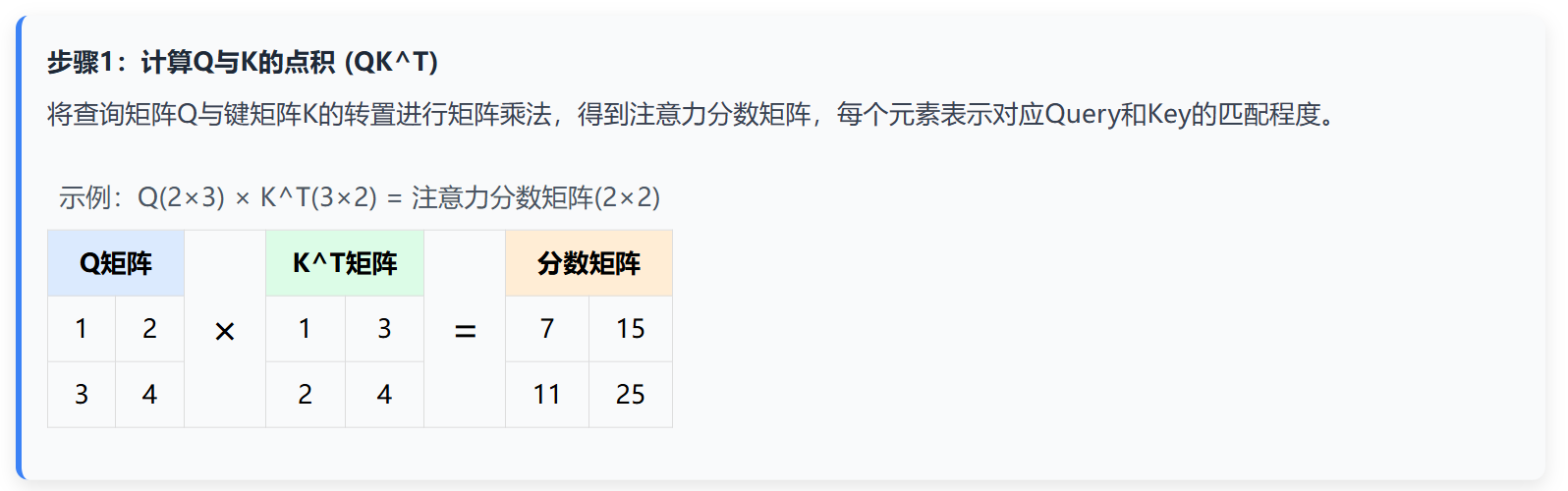
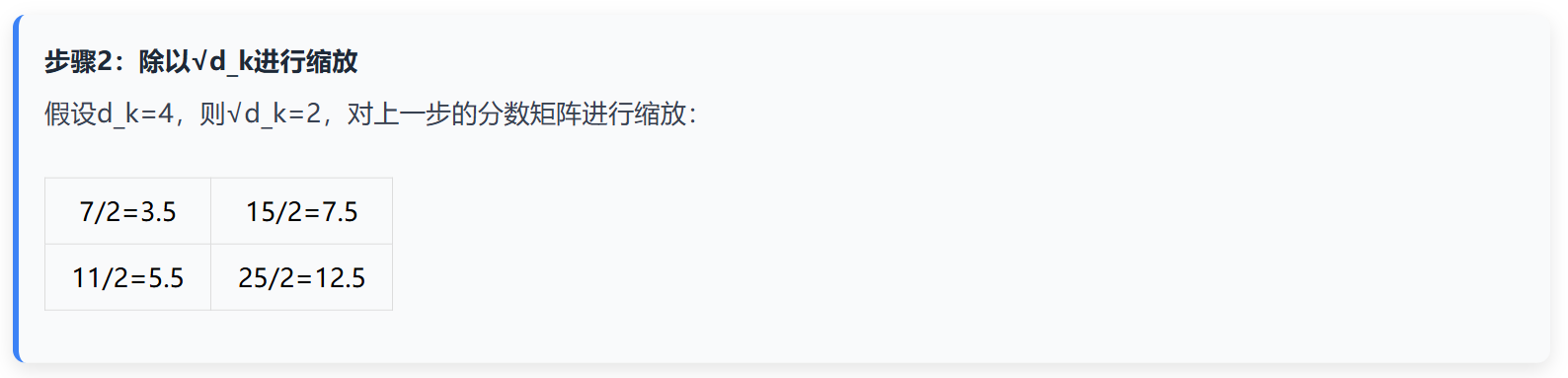
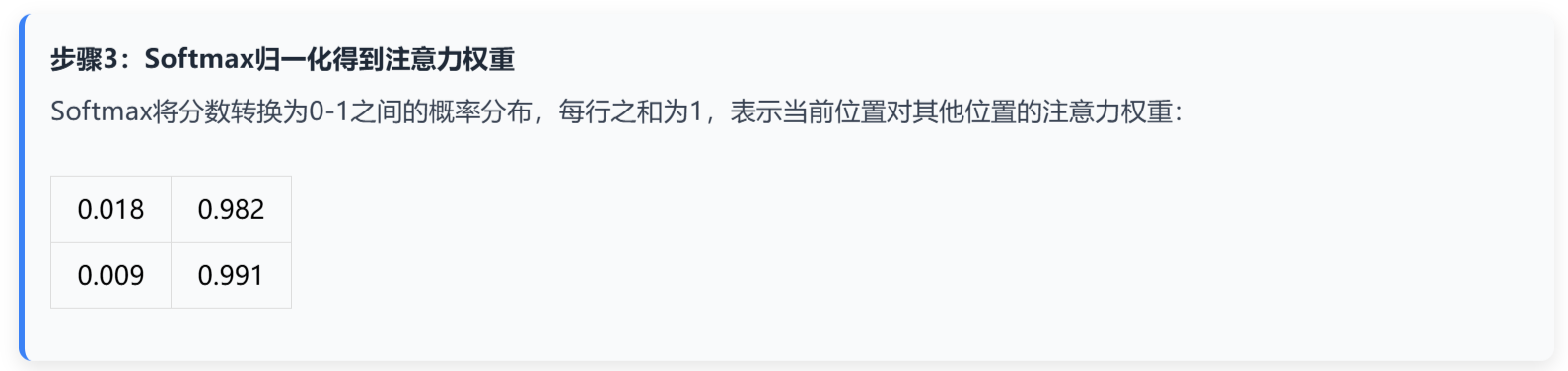
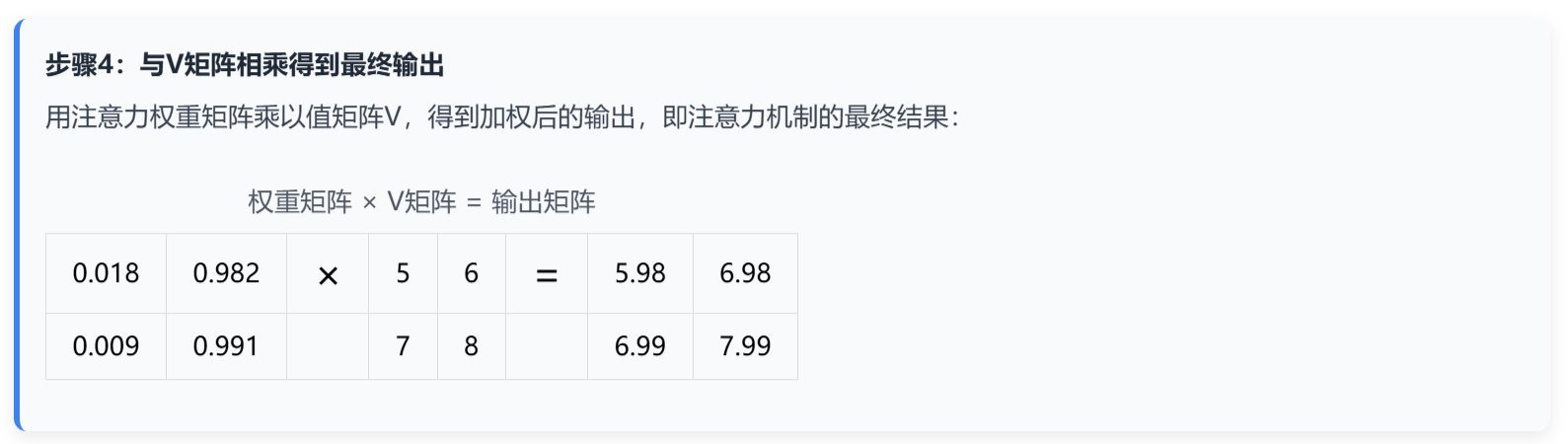
二、 Encoder-Decoder注意力与Decoder-only注意力
在 Transformer 的注意力机制体系中,不同架构设计的分支适配着各异的自然语言处理任务需求 ——Encoder-Decoder 与 Decoder-only 便是其中最具代表性的两类。前者以 “理解 + 生成” 的双重能力见长,凭借对输入信息与生成历史的双重利用,成为机器翻译、文本摘要等需要精准语义映射任务的优选;后者则聚焦自回归生成场景,依托海量数据习得的语言规律,在对话创作、文本续写等开放式生成任务中展现出强大的连贯表达能力。两类机制看似路径不同,实则都是对注意力分配逻辑的精妙设计,其差异与适配性也成为理解 Transformer 架构选型的关键切入点。
| 特性 | Encoder-Decoder注意力 | Decoder-only注意力 |
|---|---|---|
| 所属架构 | 原始Transformer、T5、BART等编解码器模型 | GPT系列、LLaMA等纯解码器大语言模型 |
| 包含组件 | 编码器双向自注意力 + 解码器掩码自注意力 + 编码器-解码器交叉注意力 | 仅包含解码器掩码自注意力 |
| 信息来源 | 同时关注输入序列(编码器输出)和已生成序列(解码器自身输出) | 仅关注已生成序列(自身历史输出) |
| 核心限制 | 解码器自注意力带掩码(不可看未来),交叉注意力无掩码(可看全部输入) | 所有自注意力都带掩码(只能看过去) |
| 典型任务 | 机器翻译、文本摘要、图文生成(理解+生成双重任务) | 文本生成、对话、创意写作(以生成为主) |
Encoder-Decoder注意力:双向理解+单向生成
这种注意力机制就像一个专业翻译:先通读全文理解意思(编码器双向自注意力),再逐字逐句输出译文(解码器掩码自注意力),同时不断回看原文确保准确(交叉注意力)。
三大核心组件
- 编码器双向自注意力:输入序列中每个词可以同时"看到"左右两边所有词,全面理解上下文。比如"河边的银行倒闭了",能同时关联"河边"和"倒闭了"判断"银行"是金融机构而非河岸。
- 解码器掩码自注意力:生成时只能看当前词及之前的词,用一个上三角掩码矩阵把未来位置设为-∞,确保不会"偷看答案"。
- 编码器-解码器交叉注意力:解码器的"眼睛",让生成每个词时都能参考编码器处理过的完整输入信息,保证输出与输入的语义一致性。
Decoder-only注意力:专注自回归生成
这种注意力机制像一个即兴演讲者:没有稿子,只能根据自己已经说过的内容继续往下讲,全程保持单向思维。
掩码自注意力
- 因果限制:每个词只能关注自己和左边的词,严格遵循"先有前因才有后果"的逻辑。
- 实现方式:同样使用上三角掩码矩阵,把所有未来位置的注意力分数设为-∞,经过Softmax后这些位置的权重就变成0。
- 自回归生成:生成过程是"预测-拼接-再预测"的循环,每一步都把新生成的词加入输入,继续预测下一个词。
三、自注意力机制
自注意力机制(Self-Attention)有何不同?
在注意力机制(Attention)里,query、key、value是三个核心概念——它们直译过来分别是“查询”“键”“值”,但光看中文释义还是很难get到本质,咱们用一个生活例子就能搞懂:小王想在优快云找深度学习的内容,他在搜索框里输入的“深度学习”就是query(查询);搜索引擎会拿着这个查询,去匹配数据库里提前存好的相关标签(比如吴恩达、神经网络这些,就是key(键));最后系统把匹配度最高的视频、专栏等内容(也就是value(值))推给小明,这就是QKV的核心逻辑。
而Self-Attention(自注意力)本质上也是一种注意力机制,它和普通Attention的区别很关键:普通Attention是“源内容”对“目标内容”的关联——比如做英译中翻译时,输入的英文句子是“源”,输出的中文句子是“目标”,两者是不同的内容;但Self-Attention是“源内容”和自身的关联,要么是源内容内部的元素互相关注,要么是目标内容内部的元素彼此作用,也可以理解成“目标内容和源内容完全相同(Target=Source)”时的特殊注意力机制。
在自注意力机制(Self-Attention)中,Q(Query,查询)、K(Key,键)、V(Value,值)权重矩阵是实现“关注序列中相关信息”的核心组件。它们通过对输入序列进行线性变换,生成三种特定的向量表示(Q、K、V),最终实现对序列中不同位置信息的动态聚合。
核心作用:将输入转换为“查询-键-值”系统
自注意力机制的目标是让序列中每个位置的输出,都能“自动关注”到序列中其他相关位置的信息(包括自身)。而Q、K、V权重矩阵的作用,就是将原始输入序列转换为支持这一目标的三种向量表示,具体分工如下:
Q权重矩阵( W Q W_Q WQ):生成“查询向量”,定义“需要什么信息”
Q权重矩阵的作用是将输入序列中的每个元素(如词向量)转换为查询向量(Query Vector)。
- 每个位置的查询向量( q i q_i qi)代表该位置“想要获取的信息类型”。例如,在句子“猫追狗”中,“追”这个词的查询向量可能会主动去寻找“动作的发出者”和“动作的接收者”相关的信息。
- 直观理解:可以把查询向量想象成“问题”——比如“我需要和谁关联?”“谁对我重要?”。
K权重矩阵( W K W_K WK):生成“键向量”,定义“提供什么信息类型”
K权重矩阵的作用是将输入序列中的每个元素转换为键向量(Key Vector)。
- 每个位置的键向量( k j k_j kj)代表该位置“能提供的信息类型”。例如,“猫”的键向量可能包含“动作发出者”的特征,“狗”的键向量可能包含“动作接收者”的特征。
- 键向量的核心作用是与查询向量匹配:通过计算 q i q_i qi与 k j k_j kj的相似度(如点积),得到“位置 i i i需要关注位置 j j j的程度”(即注意力分数)。
- 直观理解:键向量是“答案的标签”——比如“我是动作发出者”“我是动作接收者”,用于被查询向量匹配。
V权重矩阵( W V W_V WV):生成“值向量”,定义“实际提供的信息内容”
V权重矩阵的作用是将输入序列中的每个元素转换为值向量(Value Vector)。
- 每个位置的值向量( v j v_j vj)代表该位置“实际包含的具体信息”。例如,“猫”的值向量可能包含其语义特征(如“动物、哺乳动物、宠物”),“狗”的值向量包含其自身的语义特征。
- 当通过Q和K计算出注意力分数后,值向量会被这些分数加权求和,最终生成位置 i i i的输出(即“关注度高的位置,其值向量在输出中占比更大”)。
- 直观理解:值向量是“答案的具体内容”——当查询向量匹配到某个键向量后,就会提取对应的值向量中的信息。
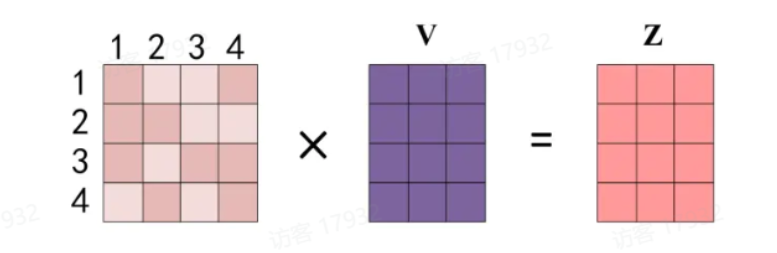
假设输入序列为 X = [ x 1 , x 2 , . . . , x n ] X = [x_1, x_2, ..., x_n] X=[x1,x2,...,xn]( x i x_i xi为第 i i i个位置的输入向量),通过Q、K、V权重矩阵生成:
- Q = [ q 1 , q 2 , . . . , q n ] = X ⋅ W Q Q = [q_1, q_2, ..., q_n] = X \cdot W_Q Q=[q1,q2,...,qn]=X⋅WQ( q i = x i ⋅ W Q q_i = x_i \cdot W_Q qi=xi⋅WQ)
- K = [ k 1 , k 2 , . . . , k n ] = X ⋅ W K K = [k_1, k_2, ..., k_n] = X \cdot W_K K=[k1,k2,...,kn]=X⋅WK( k i = x i ⋅ W K k_i = x_i \cdot W_K ki=xi⋅WK)
- V = [ v 1 , v 2 , . . . , v n ] = X ⋅ W V V = [v_1, v_2, ..., v_n] = X \cdot W_V V=[v1,v2,...,vn]=X⋅WV( v i = x i ⋅ W V v_i = x_i \cdot W_V vi=xi⋅WV)
对于位置 i i i的输出 y i y_i yi:
- 计算 q i q_i qi与所有 k j k_j kj的相似度(注意力分数): s c o r e i , j = q i ⋅ k j score_{i,j} = q_i \cdot k_j scorei,j=qi⋅kj(点积);
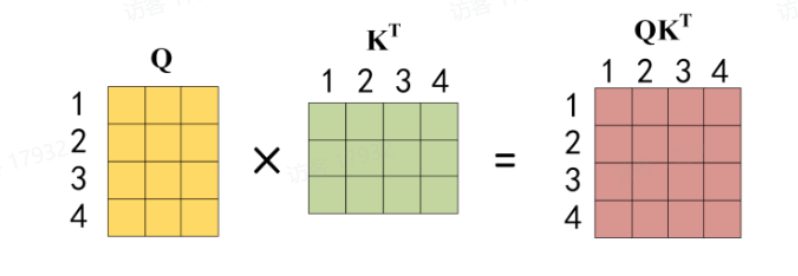
- 对分数归一化(如softmax): α i , j = softmax ( s c o r e i , j d k ) \alpha_{i,j} = \text{softmax}(\frac{score_{i,j}}{\sqrt{d_k}}) αi,j=softmax(dkscorei,j)( d k \sqrt{d_k} dk为缩放因子,避免分数过大);
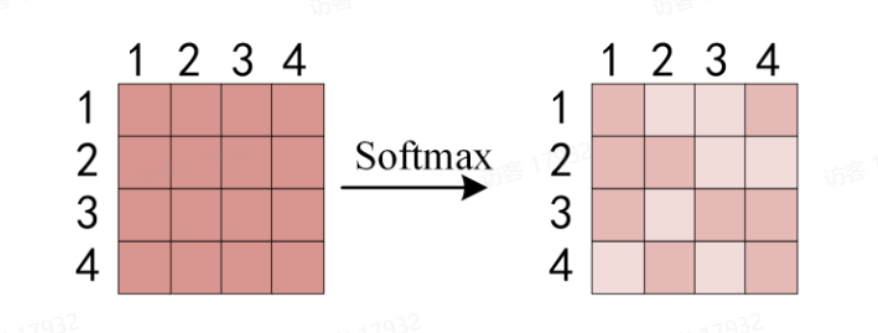
3. 用归一化分数对
V
V
V加权求和:
y
i
=
∑
j
=
1
n
α
i
,
j
⋅
v
j
y_i = \sum_{j=1}^n \alpha_{i,j} \cdot v_j
yi=∑j=1nαi,j⋅vj,即得到Z矩阵。
关键特性:可学习性
Q、K、V权重矩阵是可学习的参数(在训练过程中通过反向传播更新)。模型会根据具体任务(如翻译、文本分类)自动调整这些矩阵,使得:
- Q能更精准地定义“需要关注的信息”;
- K能更清晰地标识“自身提供的信息类型”;
- V能更有效地承载“需要传递的具体内容”。
四、多头注意力机制
多头注意力机制的提出,本质是为了突破单头注意力只能捕捉单一维度语义关联的局限——通过并行学习多个子空间的注意力分布,让模型更全面、细致地理解序列中的复杂关系,最终提升注意力机制的表达能力和建模效果。
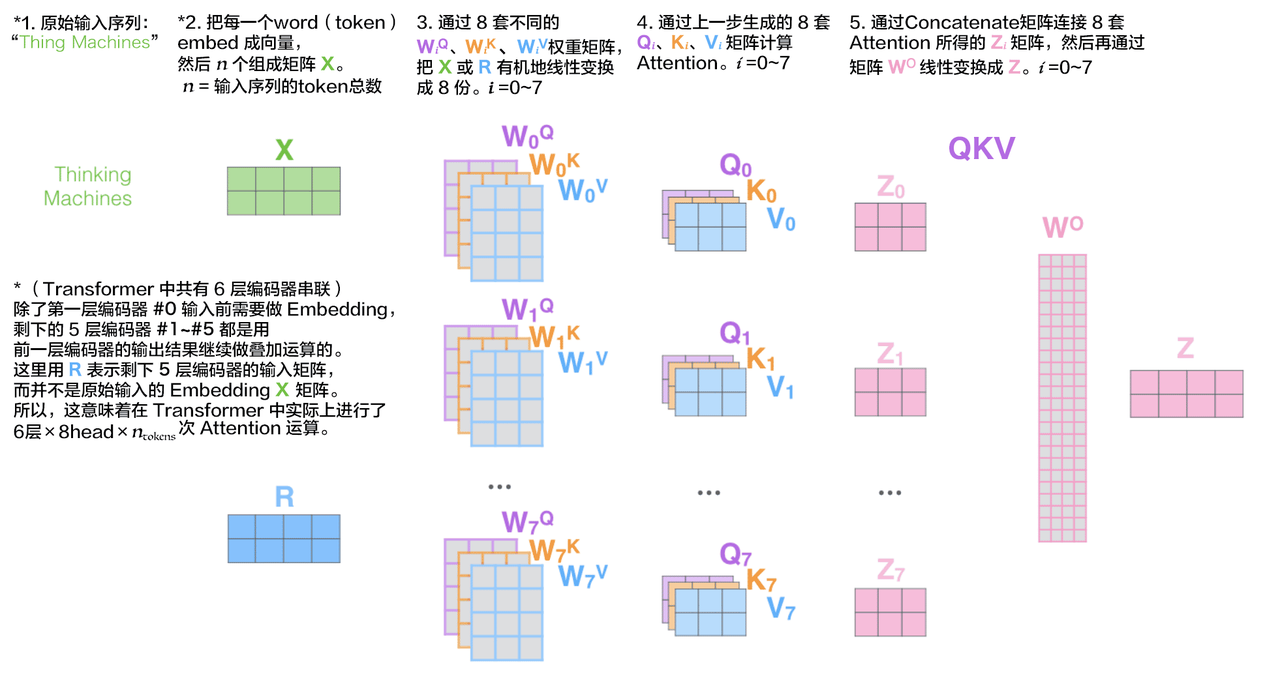
多头注意力计算过程
下图为多头注意力机制的计算过程说明,减少单头注意力Q、K、V矩阵的维度为原来的1/n,并用一个权重矩阵W0有机地将各个头学习到的特征矩阵整合为最终的特征矩阵:
多头注意力机制的提出的核心意义
-
单头注意力的先天不足:
单头注意力会将Query(查询)、Key(键)、Value(值)统一投影到同一个低维空间计算相似度,相当于只能用“单一视角”观察序列元素间的关系。比如面对句子“他在河边的银行取钱”,单头注意力可能只捕捉到“银行”与“取钱”的动作关联,却忽略“河边”与“银行”的场景关联、“他”与“银行”的主体关联;再比如机器翻译中,单头可能只关注单词的字面匹配,漏掉语法结构或指代关系。这种单一维度的建模,会让模型丢失大量关键语义信息,无法应对复杂的自然语言任务。 -
多维度、多视角的语义捕捉:
多头注意力的核心设计是:将Q、K、V通过不同的线性投影矩阵,映射到多个相互独立的子空间(每个子空间对应一个“注意力头”),每个头专注学习一种维度的语义关联,最后将所有头的结果拼接(或加权求和)整合。
- 比如上面的例句,一个头关注“动作关联”(银行→取钱),一个头关注“场景关联”(河边→银行),还有一个头关注“主体关联”(他→银行);
- 再比如在文本摘要任务中,有的头聚焦“主旨句与细节句的关联”,有的头聚焦“因果逻辑关联”,有的头聚焦“高频核心词的关联”。 通过这种多视角建模,模型能整合不同维度的注意力信息,完整还原序列的语义全貌。
- 提升模型表达能力与泛化性:
多个注意力头相当于给模型配备了“多副眼镜”,每副眼镜能看到不同层面的信息,避免了单一视角的偏差和信息遗漏。这种设计让模型能学习到更丰富的特征表示:
- 在对话任务中,有的头关注上下文的指代关系(比如“它”指代前文的“手机”),有的头关注情感倾向的延续(比如从“开心”到“兴奋”的情绪关联);
- 在代码生成任务中,有的头关注语法规则(比如函数名与参数的匹配),有的头关注逻辑流程(比如循环与条件判断的衔接)。
最终,模型的泛化能力会显著提升,能更好地适配不同类型的任务场景。
- 效率与效果的平衡:
多头注意力的设计还兼顾了计算效率:每个头的维度被设置为 d m o d e l / h d_{model}/h dmodel/h( d m o d e l d_{model} dmodel 是模型总维度, h h h 是头数),因此总计算量与单头注意力几乎相当,却能通过并行计算实现“多倍”的语义捕捉能力,是对模型性能与计算成本的最优平衡。
五、注意力掩码
注意力掩码(Attention Mask):注意力计算的“遮挡板”
注意力掩码本质是在注意力机制计算过程中,人为限制模型关注范围的工具——通过对注意力分数矩阵中“不该被关注”的位置设置极小值(如
−
∞
-\infty
−∞),让这些位置经过Softmax后权重趋近于0,相当于给模型戴上“选择性眼罩”,只允许它看到符合任务逻辑的内容,避免无效信息干扰或违背任务规则(比如“偷看未来内容”)。
核心原理:修改注意力分数矩阵
注意力计算的关键步骤是:Query与Key做点积得到注意力分数矩阵(每个元素代表“当前位置对其他位置的关注程度”),再通过Softmax将分数转化为0~1的权重。
注意力掩码的作用就是对这个分数矩阵进行“修改”:
- 构建与分数矩阵形状相同的掩码矩阵(值为0或1,1表示“可关注”,0表示“不可关注”);
- 将掩码矩阵中0的位置对应到分数矩阵中,替换为极小值( − ∞ -\infty −∞);
- 经过Softmax后, − ∞ -\infty −∞ 对应的权重会无限接近0,模型便不会关注这些位置。
简单说:掩码就是让模型“看不见”某些位置,从根源上杜绝无效关注。
两种最常见的注意力掩码
(1)因果掩码(Causal Mask / 未来掩码)
-
适用场景:Decoder的自注意力层(如GPT等Decoder-only模型、Transformer的Decoder部分)。
-
作用:保证生成任务的“自回归逻辑”——生成第 i i i 个词时,只能关注第 1 至 i 1至i 1至i 个词(已生成的内容),绝对不能看第 i + 1 i+1 i+1 个及以后的词(未来内容)。
-
例子:生成句子“我爱吃苹果”时:
- 生成“爱”(第2个词):只能看“我”(第1个词);
- 生成“吃”(第3个词):只能看“我”“爱”(第1~2个词);
- 掩码会把分数矩阵中“未来位置”(如生成“爱”时的“吃”“苹果”)设为 − ∞ -\infty −∞,Softmax后这些位置权重为0。
因果掩码的矩阵形状是下三角矩阵(下三角为0,上三角为 − ∞ -\infty −∞),直观来看就是“只能看左边,不能看右边”。
| 生成位置 → 关注位置 | 1(我) | 2(爱) | 3(吃) | 4(苹果) |
|---|---|---|---|---|
| 1(我) | 0 | -∞ | -∞ | -∞ |
| 2(爱) | 0 | 0 | -∞ | -∞ |
| 3(吃) | 0 | 0 | 0 | -∞ |
| 4(苹果) | 0 | 0 | 0 | 0 |
(2)填充掩码(Padding Mask)
- 适用场景:所有注意力层(Encoder、Decoder)处理批量不等长序列时。
- 作用:忽略序列中的填充位(如
[PAD]标记)——因为实际任务中,我们会把一批长度不同的句子补成相同长度(比如用[PAD]填充短句子),但这些填充位没有实际语义,模型关注它们会引入噪声。 - 例子:一批有两个句子:
- 句子A:“我爱吃苹果”(长度4,无填充);
- 句子B:“他爱梨”(长度3,补1个
[PAD],总长度4)。
填充掩码会把句子B中[PAD]对应的位置设为 − ∞ -\infty −∞,让模型计算注意力时完全忽略这个填充位,避免它干扰“他”“爱”“梨”之间的语义关联。



















 6094
6094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











