




序列到序列(Sequence-to-Sequence,简称Seq2Seq)是一种用于处理输入序列到输出序列映射的神经网络架构,由Google团队在2014年提出(论文《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》)。
核心思想:将可变长度的输入序列转换为固定长度的"上下文向量",再基于该向量生成可变长度的输出序列,适用于机器翻译、文本摘要、对话系统等场景。
Seq2Seq(序列到序列)架构是自然语言处理(NLP)领域中处理不等长序列映射任务的核心基础架构,奠定了现代序列生成类任务的技术框架,在 NLP 发展历程中起到承上启下的关键作用 —— 它既突破了传统模型的局限,又成为后续顶尖预训练模型的架构雏形。
一、经典架构:编码器-解码器(Encoder-Decoder)
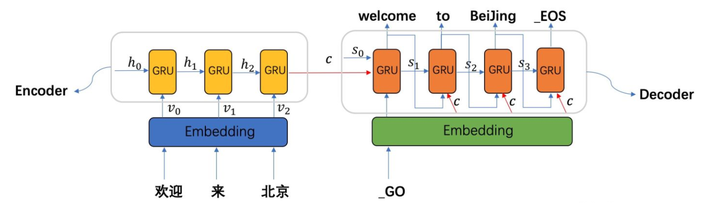
1. 编码器(Encoder)
**功能:**将输入序列(如"我爱机器学习")编码为一个固定长度的上下文向量(Context Vector),捕捉输入序列的全局信息。
**结构:**通常采用循环神经网络(RNN)及其变体(LSTM、GRU),处理步骤如下:
输入序列按时间步依次输入编码器(如"我"→"爱"→"机器学习");
每个时间步的隐藏状态基于当前输入和上一时间步隐藏状态更新;
最终输出编码器的最后一个时间步隐藏状态作为上下文向量(代表对输入序列的"理解")。


2. 解码器(Decoder)
功能: 以编码器生成的上下文向量为初始输入,逐步生成输出序列(如"I love machine learning")。
结构: 同样基于RNN/LSTM/GRU,生成步骤如下:
初始隐藏状态设为编码器输出的上下文向量;
第一个输入通常为特殊符号(如),生成第一个输出词;
将上一时间步的输出作为当前时间步的输入,结合隐藏状态更新,直到生成结束符号(如)。

3. 关键组件:循环神经网络变体
经典Seq2Seq中,编码器和解码器多采用LSTM(长短期记忆网络)或GRU(门控循环单元),解决传统RNN的"梯度消失/爆炸"问题,更好捕捉长序列依赖。

二、Seq2Seq的训练目标
Seq2Seq模型的训练核心就是学习编码器和解码器中的权重参数。
-
训练目标
Seq2Seq模型的训练目标是最大化给定输入序列 ( X ) 下输出序列 ( Y ) 的条件概率 ( P(Y|X) )。通常使用交叉熵损失函数,通过最小化预测序列与真实序列之间的差异来优化模型参数。 -
可训练参数范围
Seq2Seq模型的可训练参数主要包括两部分:
(1)编码器的权重参数
- 对于RNN/LSTM/GRU编码器:
- 输入到隐藏层的权重矩阵(如 ( W_{xh} )、( W_{xf} )、( W_{xi} ) 等)
- 隐藏层到隐藏层的权重矩阵(如 ( W_{hh} )、( W_{hf} )、( W_{hi} ) 等)
- 偏置项(如 ( b_h )、( b_f )、( b_i ) 等)
(2)解码器的权重参数
- 对于RNN/LSTM/GRU解码器:
- 输入到隐藏层的权重矩阵(如 ( W_{ys} )、( W_{cs} ) 等)
- 隐藏层到输出层的权重矩阵(如 ( W_{sy} ))
- 偏置项(如 ( b_s )、( b_y ) 等)
(3)如果使用注意力机制
- 注意力评分函数中的权重矩阵(如 ( W_a )、( U_a )、( v_a ))
关键细节
- 共享权重:在某些模型(如Transformer)中,编码器和解码器的部分层可能共享权重,但Seq2Seq经典架构中通常不共享。
- Teacher Forcing:训练时解码器的输入通常使用真实标签(而非上一步的预测),以稳定训练。
- 推理阶段:模型使用学习到的参数独立生成输出序列,无需真实标签。



















 6231
6231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











