




文章目录
Transformer模型自2017年提出以来,彻底改变了自然语言处理领域。与传统的RNN和LSTM不同,Transformer完全基于注意力机制,能够并行处理整个序列。然而,这也带来了一个关键问题:如何让模型理解序列中元素的位置信息?
在RNN中,位置信息是天然存在的——每个时间步的处理都依赖于前一个时间步。但在Transformer中,所有位置是并行处理的,因此需要显式地注入位置信息。这就是位置编码(Positional Encoding)的作用。
为什么需要位置编码?
核心问题:Transformer的自注意力机制是置换不变的(permutation-invariant),即输入序列的顺序改变不会影响输出。这意味着模型无法区分"我喜欢你"和"你喜欢我"这两个句子。
位置编码通过为每个位置添加唯一的位置信息,使得模型能够理解:
- 序列中每个元素的位置
- 元素之间的相对距离
- 序列的顺序关系
绝对位置编码
-
提到位置编码,第一个可能想到的方法是为每个时间步添加一个[0-1]范围内的数字,其中0表示第一个单词,1表示最后一个单词。但这样会存在一个问题:无法计算出特定范围内有多少个单词。换句话说,时间步长在不同句子中的含义不一致。如下图:

-
另一个可能的想法是为每个时间步按一定步长线性分配一个数字。也就是说,第一个单词是“1”,第二个单词是“2”第三个单词是“3”,依此类推。这种方法的问题在于,随着句子变长,这些值可能会变得特别大,并且我们的模型在实际应用中可能会遇到比训练时更长的句子,此外,我们的模型可能会忽略某些长度的样本(比如Bert模型支持最长序列长度为512),这会损害模型的泛化。
以上两种方法,其实就是所谓的绝对位置编码。但是其实理想情况下,位置编码需要满足以下几个要求:
- 必须是确定性的;
- 每个时间步都有唯一的编码;
- 在不同长度的句子中,两个时间步之间的距离应该一致;
- 模型不受句子长短的影响,并且编码范围是有界的。(不会随着句子加长数字就无限增大)。
Transformer的位置编码原理


1. 正余弦函数为什么能用来表示位置信息呢?
以下内容来自:https://zhuanlan.zhihu.com/p/1900502346804466158
此时,你可能好奇:正余弦组合怎么能代表一个位置信息呢?其实很简单,假设你想用二进制格式表示一个数字。可以看到不同位置上的数字交替变化。
- 最后一位数字每次都会0、1交替;
- 倒数第二位置上00,11相互交替一次;
- 倒数第三个位置上0000,1111相互交替;
- 以此类推。

但对于浮点数来说,使用二进制值是对空间的浪费,所以可以用正弦函数代替。事实上,正弦余弦函数也能表示出二进制那样的交替。此外随着正弦函数频率的降低,也可以达到上图红色位到橙色位交替频率的变化。
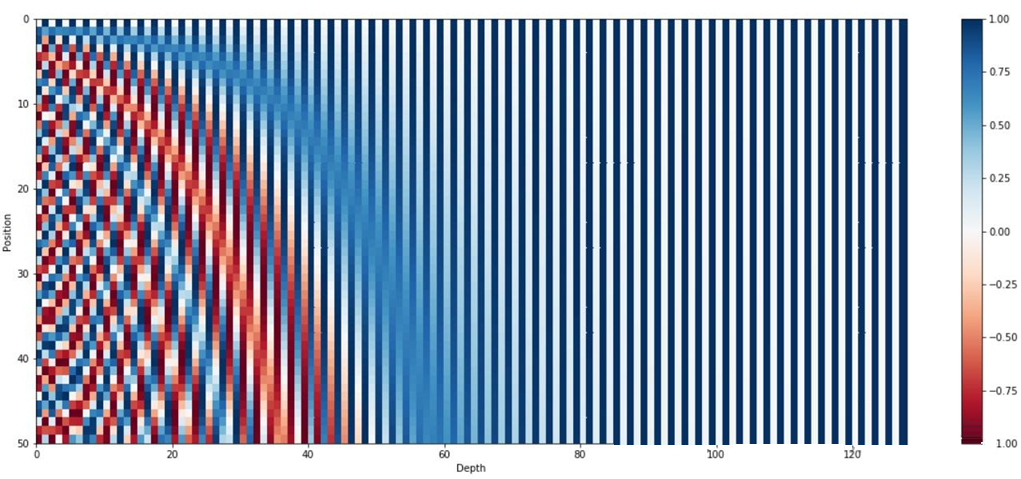
下图使用正弦函数编码,句子长度为50(纵坐标),编码向量维数128(横坐标),可以看到交替频率从左到右逐渐减慢。
2. 工作原理
(1)与词嵌入的结合
位置编码通过元素相加的方式与词嵌入结合:

这种相加操作允许模型同时学习词汇语义和位置信息,两者在同一个向量空间中表示。
(2)相对位置的线性关系

3. 特点分析
一个理想的位置编码方案应该满足四个关键要求。让我们逐一分析Transformer的正弦位置编码在这些方面的表现:
(1)每个时间步都有唯一的编码
分析:正弦位置编码通过位置索引pos直接计算编码值。由于每个位置pos都是唯一的整数(0, 1, 2, …),而编码函数是确定性的,因此每个位置都会得到唯一的编码向量。

在实现中,我们可以通过计算不同位置编码向量的余弦相似度来验证。实验表明,不同位置的编码向量相似度通常很低(接近0),证明了编码的唯一性。
(2)在不同长度的句子中,两个时间步之间的距离应该一致
分析:这是正弦位置编码的一个核心优势。编码值只依赖于位置索引pos,而不依赖于序列的总长度。因此,无论序列长度如何,位置i和位置j之间的编码差异只取决于它们的相对距离|i-j|。

实际意义:这意味着模型在不同长度的序列中学习到的相对位置关系是一致的。例如,模型在短序列中学到的"相邻词"的概念,可以直接应用到长序列中。

(3)模型不受句子长短的影响,并且编码范围是有界的
分析:正弦位置编码完美满足这个要求。由于使用了三角函数sin和cos,编码值被严格限制在[-1,1]范围内,无论序列长度如何。

优势:
数值稳定性:有界的编码值避免了梯度爆炸或数值溢出问题
外推能力:模型可以处理比训练时更长的序列,因为编码值始终在合理范围内
归一化友好:编码值在[-1,1]范围内,与词嵌入相加后不会导致数值过大

位置编码是Transformer架构中的关键组件,它解决了自注意力机制无法感知序列顺序的问题。正弦位置编码通过巧妙的数学设计,不仅提供了位置信息,还使得模型能够学习相对位置关系。虽然现在有各种变体,但理解原始的正弦位置编码仍然是掌握Transformer的重要基础。



















 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











