




 本文介绍了决策树的定义、训练过程,以及信息熵和信息增益的概念。通过实例展示了如何使用Python实现决策树,包括数据准备、计算信息熵、特征选择、数据拆分和建树过程。最后,提供了预测函数的实现,并对模型的局限性和优化方向进行了简要说明。
本文介绍了决策树的定义、训练过程,以及信息熵和信息增益的概念。通过实例展示了如何使用Python实现决策树,包括数据准备、计算信息熵、特征选择、数据拆分和建树过程。最后,提供了预测函数的实现,并对模型的局限性和优化方向进行了简要说明。
本文始发于个人公众号:TechFlow,原创不易,求个关注
今天是机器学习专题的第21篇文章,我们一起来看一个新的模型——决策树。
决策树的定义
决策树是我本人非常喜欢的机器学习模型,非常直观容易理解,并且和数据结构的结合很紧密。我们学习的门槛也很低,相比于那些动辄一堆公式的模型来说,实在是简单得多。
其实我们生活当中经常在用决策树,只是我们自己没有发现。决策树的本质就是一堆if-else的组合,举个经典的例子,比如我们去小摊子上买西瓜。水果摊的小贩都是怎么做的?拿起西瓜翻滚一圈,看一眼,然后伸手一拍,就知道西瓜甜不甜。我们把这些动作相关的因素去除,把核心本质提取出来,基本上是这么三条:
- 西瓜表面的颜色,颜色鲜艳的往往比较甜
- 西瓜拍打的声音,声音清脆的往往比较甜
- 西瓜是否有瓜藤,有藤的往往比较甜
这三条显然不是平等的,因为拍打的声音是最重要的,可能其次表面颜色,最后是瓜藤。所以我们挑选的时候,肯定也是先听声音,然后看瓜藤,最后看颜色。我们把其中的逻辑抽象出来然后整理一下,变成一棵树结构,于是这就成了决策树。
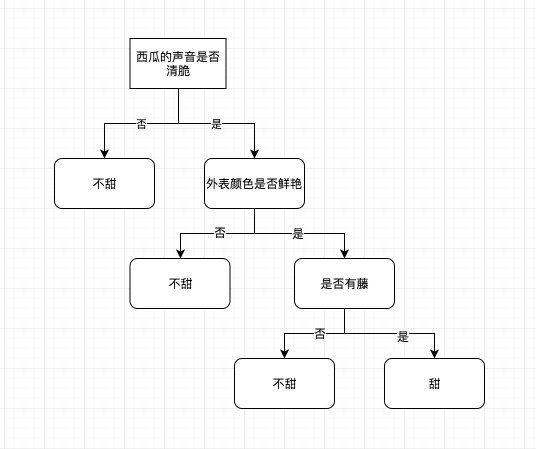
这个决策树本质上做的还是分类的工作,将西瓜分成了甜的和不甜的。也就是说决策树是一个树形的分类器,这个也是决策树的基本定义。另外从图中我们还有一个启示,在这个问题当中,决策树的特征都是离散值,而不是连续值。也就是说决策树可以接受像是类别、标识这样非数值型的特征,而逻辑回归这些模型则不太行。
如果你对这些细节还理解不深刻也没有关系,我们可以先放一放,至少我们明白了决策树的大概结构以及工作原理。
对于每一条数据来说,它分类的过程其实就是在决策树上遍历的过程。每到一个中间节点都会面临一次判断,根据判断的结果选择下一个子树。而树上的叶子节点代表一种分类,当数据到了叶子节点,这个叶子节点的值就代表它的分类结果。
决策树的训练
明白了决策树的结构和工作原理之后,下面就是训练的过程了。
在理清楚原理之前,我们先来看下数据。我们根据上面决策树的结构,很容易发现,训练数据应该是这样的表格:
| 分类 | 声音是否清脆 | 是否有瓜藤 | 是否有光泽 |
|---|---|---|---|
| 甜 | 是 | 是 | 是 |
| 甜 | 是 | 是 | 否 |
| 不甜 | 否 | 否 | 是 |
| 不甜 | 否 | 否 | 否 |
那么最后我们想要实现什么效果呢?当然是得到的准确率越高越好,而根据决策树的原理,树上的每一个叶子节点代表一个分类。那么我们显然希望最后到达叶子节点的数据尽可能纯粹,举个例子,如果一个叶子节点代表甜,那么我们肯定希望根据树结构被划归到这里的数据尽可能都是甜的,不甜的比例尽可能低。
那么我们怎么实现这一点呢?这就需要我们在越顶层提取规则的时候,越选择一些区分度大的特征作为切分的依据。所谓区分度大的特征,也就是能够将数据很好分开的特征。这是明显的贪心做法,使用这样的方法,我们只可以保证在尽可能高层取得尽可能好的分类结果,但是并不能保证这样得到的模型是最优的。生成最优的决策树本质上也是一个NP问题,我们当前的做法可以保证在尽量短的时间内获得一个足够优秀的解,但是没办法保证是最优解。
回到问题本身,我们想要用区分度大的特征来进行数据划分。要做到这一点的前提就是首先定义区分度这个概念,将它量化,这样我们才好进行选择。否则总不能凭感觉去衡量区分度,好在这个区分度还是很好解决的,我们只需要再一次引入信息熵的概念就可以了。
信息熵与信息增益
信息熵这个词很令人费解,它英文原文是information entropy,其实一样难以理解。因为entropy本身是物理学和热力学当中的概念,用来衡量物体分散的不均匀程度。也就是说熵越大,说明物体分散得程度越大,可以简单理解成越散乱。比如我们把房间里一盒整理好的乒乓球打翻,那么里面的乒乓球显然会散乱到房间的各个地方,这个散乱的过程可以理解成熵增大的过程。
信息熵也是一样的含义,用来衡量一份信息的散乱程度。熵越大,说明信息越杂乱无章,否则说明信息越有调理。信息熵出自大名鼎鼎的信息学巨著《信息论》,它的作者就是赫赫有名的香农。但是这个词并不是香农原创,据说是计算机之父冯诺依曼取的,他去这个名字的含义也很简单,因为大家都不明白这个词究竟是什么意思。
之前我们曾经在介绍交叉熵的时候详细解释过这个概念,我们来简单回顾一下。对于一个事件X来说,假设它发生的概率是P(X),那么这个事件本身的信息量就是:
I(X)=−log2P(X)I(X) = -log_2P(X)I(X)=−log2P(X)
比如说世界杯中国队夺冠的概率是1/128,那么我们需要用8个比特才能表示,说明它信息量很大。假如巴西队夺冠的概率是1/4,那么只要2个比特就足够了,说明它的信息量就很小。同样一件事情,根据发生的概率不同,它的信息量也是不同的。
那么信息熵的含义其实就是信息量的期望,也就是用信息量乘上它的概率:
H(X)=−P(X)log2P(X)H(X) = -P(X)log_2P(X)H(X)=−P(X)log2P(X)
同样,假设我们有一份数据集合,其中一共有K类样本,每一类样本所占的比例是P(K)P(K)P(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 259
259





 到【灌水乐园】发言
到【灌水乐园】发言







