







由于在构建Delta机构动力学模型的时候采取了一些假设(主动臂从动臂都认为是均质杆1)本次仿真采用关节空间鲁棒计算力矩控制的方法控制机器人。
1.1 计算力矩控制
常规的计算力矩控制策略如图
1所示,使用估计的机器人动力学模型控制实际的机器人,在理想的情况下,即估计所用的模型与实际模型完全一致: M ^ = M , n ^ = n \widehat{M} = M,\ \widehat{n} = n M
=M, n
=n.
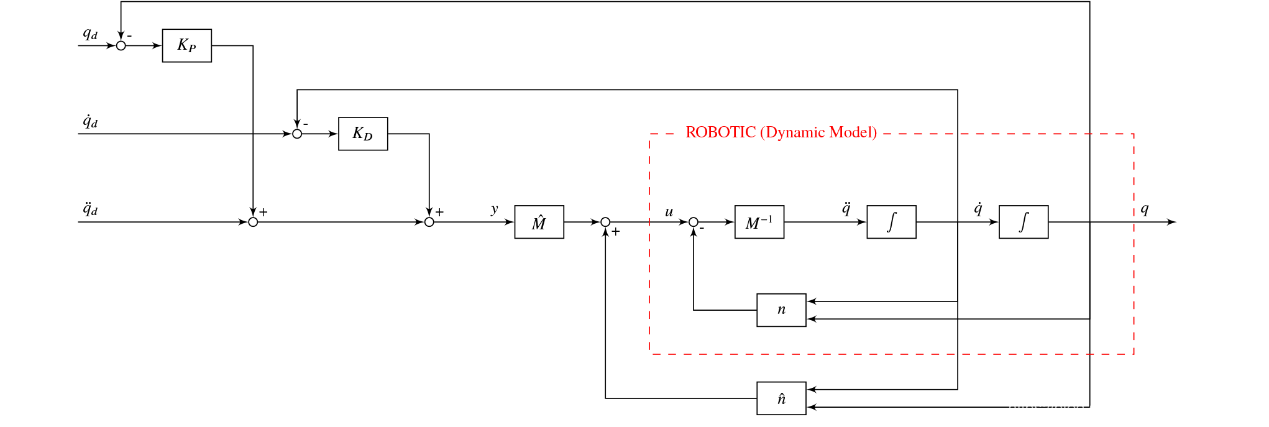
图 1计算力矩控制框图
此时被控系统就被线性化,直接写出其常微分方程:
q ¨ = q ¨ d + K D ( q ˙ d − q ˙ ) + K P ( q d − q ) \ddot{q} = \ {\ddot{q}}_{d} + \ K_{D}\left( {\dot{q}}_{d} - \dot{q} \right) + \ K_{P}\left( q_{d} - q \right) q¨= q¨d+ KD(q˙d−q˙)+ KP(qd−q)
选取合适的 K D K_{D} KD和 K P K_{P} KP就能保证系统的稳定。
根据先前所计算的逆动力学模块,我们首先按照图
1所示的结构构建了计算力矩系统,并对其进行跟踪五次多项式信号的控制测试,得到的结果如图2所示。可以看到控制所用的数学模型与实际模型(Adams模型)有一定差别,导致系统具有较大的稳态误差。
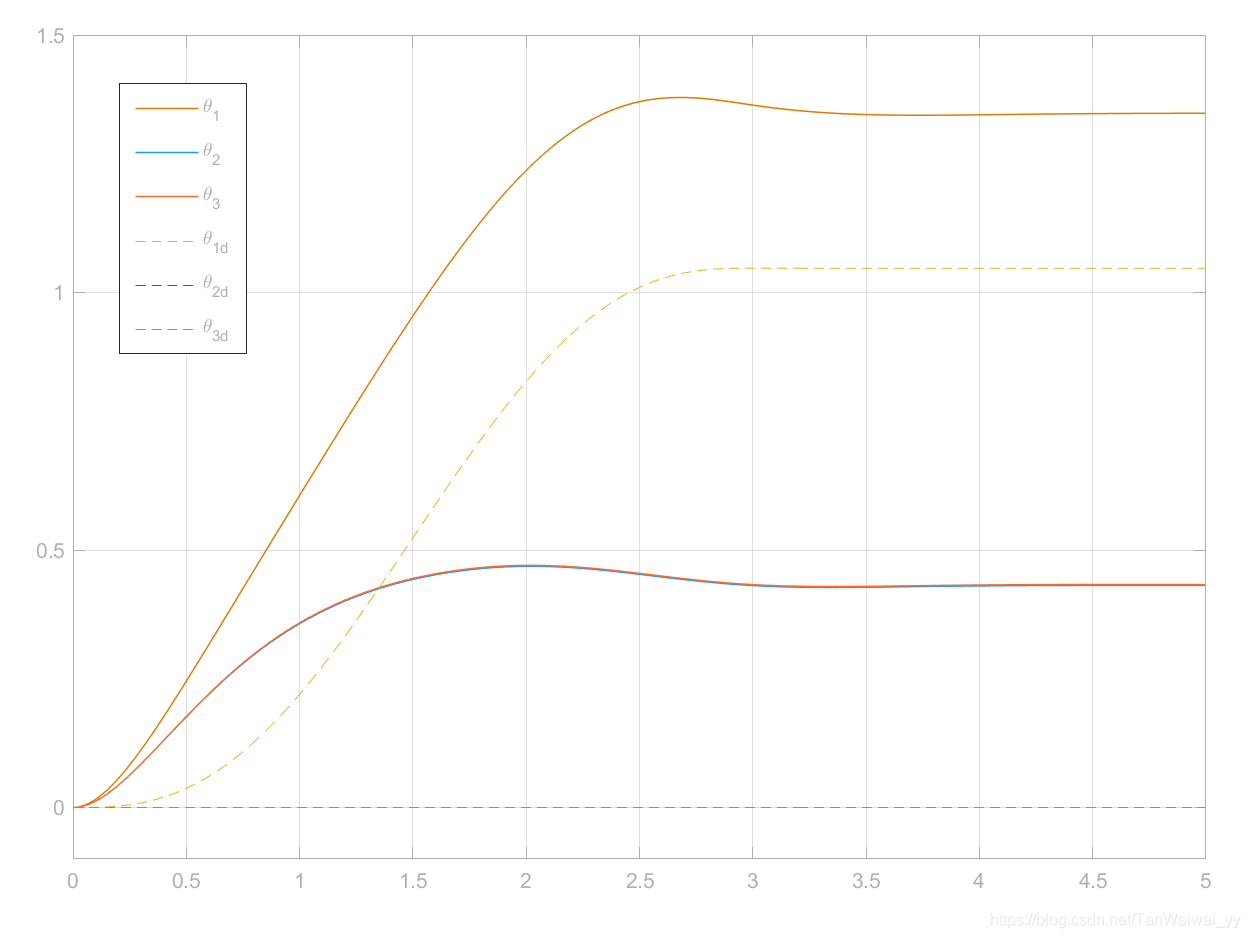
图 2系统跟踪五次多项式轨迹的响应-常规策略
1.2 鲁棒计算力矩
对于这种控制策略所使用的数学模型可能与实际模型不一致的问题,在机器人学专著《Robotics: Modelling, Planning and Control》 (Siciliano, 2010)2 中,有该控制问题详细讨论,其原理就是引入一个鲁棒项来(图4中的 ω \omega ω)辅助控制作为补偿,尽可能减小或抵消因估计不准确带来的影响(记作 η \eta η)。
M q ¨ + n = M ^ y + n ^ {\text{\ M\ }\ddot{q}\ + \ n = \ \ \widehat{M}y\ + \ \widehat{n} } M q¨ + n= M
y + n
q ¨ = y − ( ( E − M − 1 M ^ ) y + M − 1 ( n − n ^ ) ) {\ddot{q}\ = \ y\ - \left( \left( E\ - \ M^{- 1}\widehat{M}\ \right)y\ + \ M^{- 1}\left( n - \widehat{n} \right) \right)} q¨ = y −((E − M−1M
)y + M−1(n−n
))
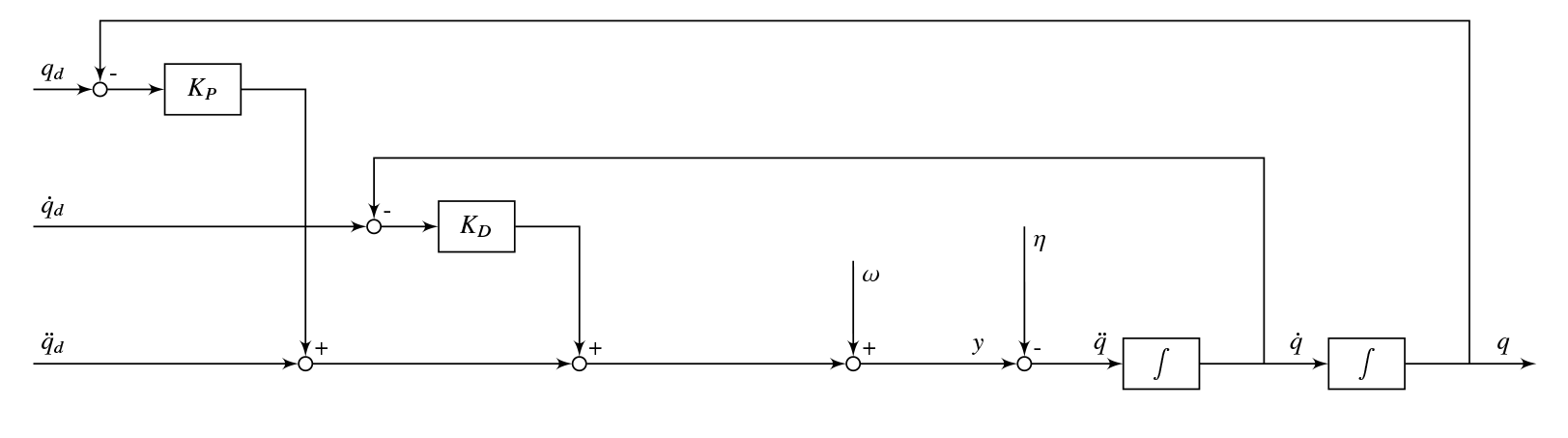 图 4鲁棒计算力矩控制框图
图 4鲁棒计算力矩控制框图
由李亚普诺第二方法可以确定使系统具有鲁棒稳定性的 ω \omega ω,首先构造状态变量 ξ \xi ξ,并将控制系统写成状态方程的形式。
ξ = [ q d − q q ˙ d − q ˙ ] T \xi = \begin{bmatrix} q_{d} - q \\ {\dot{q}}_{d} - \dot{q} \end{bmatrix}^{T} ξ=[qd−qq˙d−q˙]T
ξ ˙ = [ O E − K P − K D ] ξ + [ O E ] ( η − ω ) (1) \dot{\xi} = \begin{bmatrix} O & E \\ - K_{P} & - K_{D} \end{bmatrix}\xi + \ \begin{bmatrix} O \\ E \end{bmatrix}\ \left( \eta\ - \omega \right) \tag{1} ξ˙=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3232
3232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









