



刚刚,Anthropic 发布了 Claude 家族的最新旗舰模型 Opus 4.5,这款模型不仅刷新了各项技术基准,更在模拟真实人类工程师的入职测试中击败了所有人类候选人。
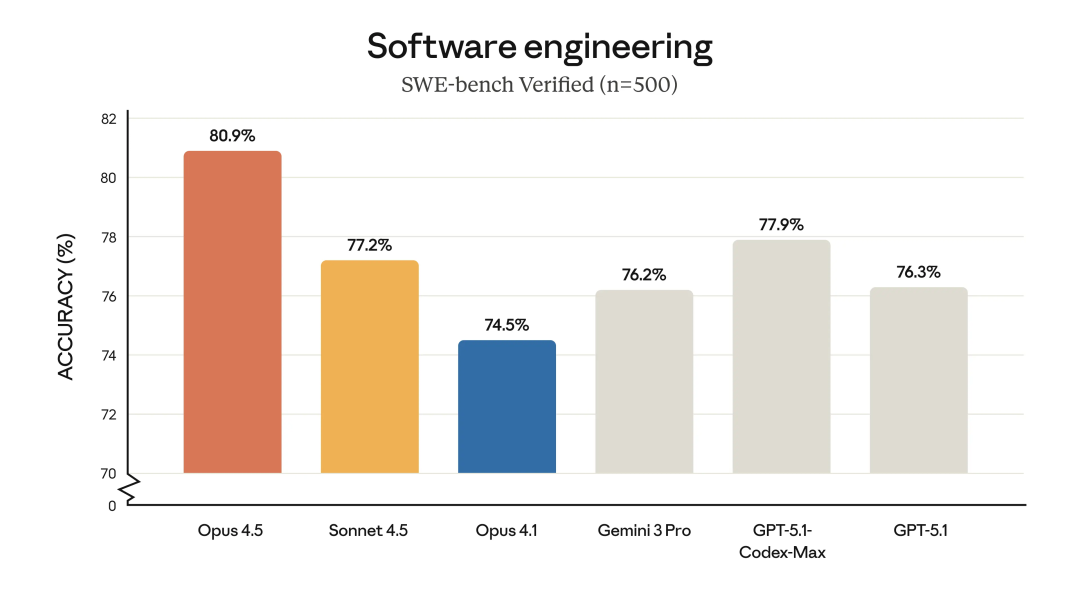
Opus 4.5 是全球范围内在代码编写、智能体(Agent)编排以及计算机使用(Computer Use)领域拥有最佳表现的生产力工具。
版本号确认为 claude-opus-4-5-20251101,已通过 API 向开发者开放。
Opus 4.5 解决了一个长期困扰行业的难题:如何在处理极其复杂的工程任务时,保持逻辑的严密性与执行的创造性。
它在深度研究、处理复杂文档时展现出的能力,相当惊人。
超越人类工程师的实战大考
Anthropic 没有使用传统的选择题来测试 Opus 4.5,而是用一套原本用于面试内部性能工程(Performance Engineering)岗位候选人的测试题。
这套试题以高难度和高强度著称,要求候选人在严格限制的 2 小时内完成一系列复杂的工程任务。
结果令人意外,Claude Opus 4.5 在规定时间内不仅完成了任务,其得分更是超过了以往任何一位参加过该测试的人类候选人。
这一结果揭示了,在纯粹的技术执行力、代码逻辑构建以及即时判断力上,顶尖的 AI 模型已经跨越了与人类顶尖专业人士的差距。
尽管这无法涵盖沟通协作等软技能,但仅就硬核技术指标而言,Opus 4.5 树立了一个新的标杆。
这种能力的提升在行业通用的基准测试中得到了进一步印证。
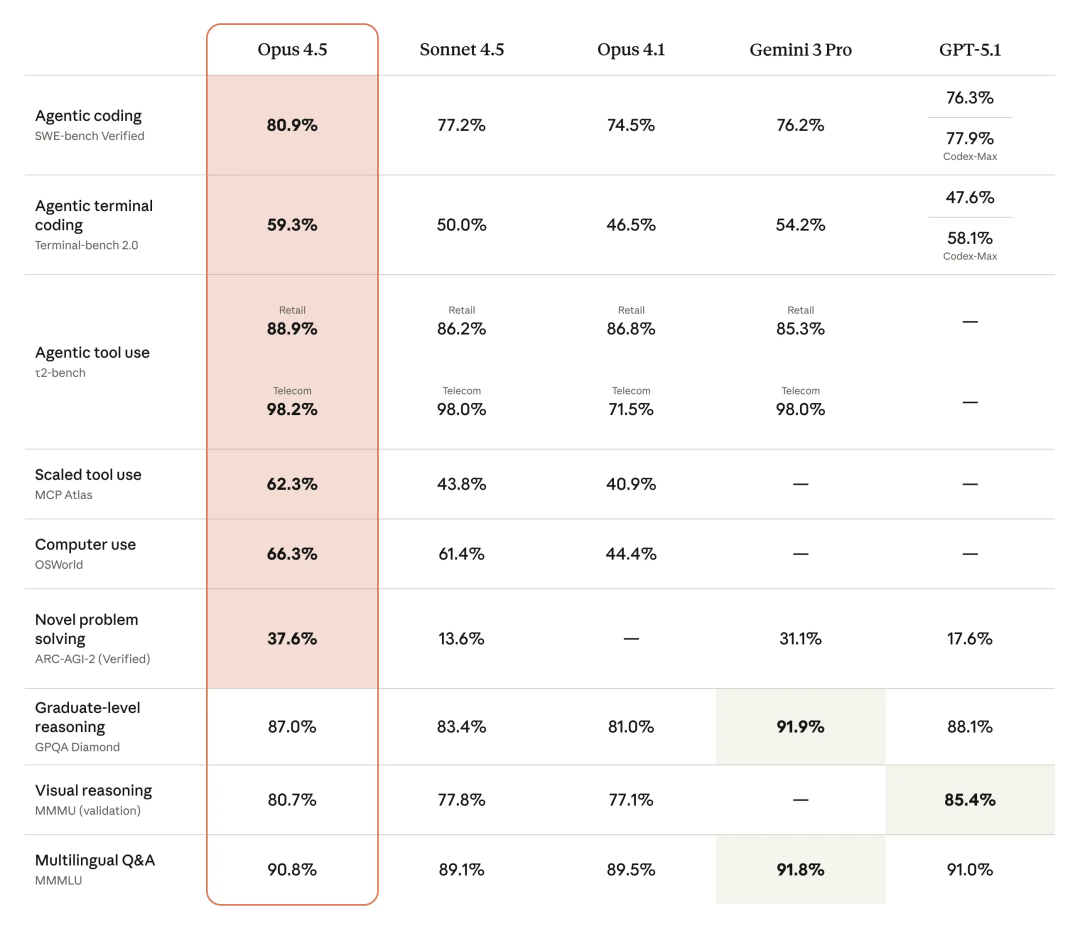
在 SWE-bench Multilingual(多语言软件工程基准)测试中,Opus 4.5 在涵盖的 8 种编程语言里,拿下了 7 种语言的榜首位置。
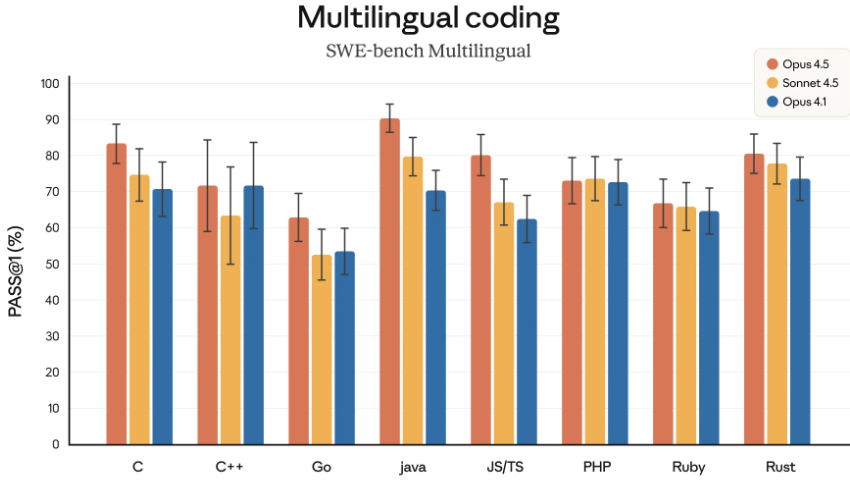
无论是在 Python 环境下构建算法,还是用 C++ 处理底层逻辑,它都能展现出统治级的编写能力。
在更考验解决实际编程难题的 Aider Polyglot 测试中,Opus 4.5 的表现相比前代产品 Sonnet 4.5 提升了 10.6%。这代表了在面对那些非标准化、需要灵活变通的代码问题时,新模型能够更轻松地找到解法。

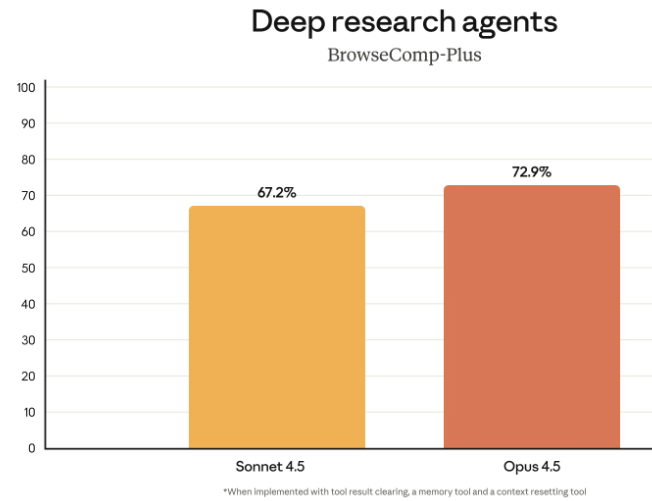
在智能体深度搜索 BrowseComp Plus 上有了显著提升。
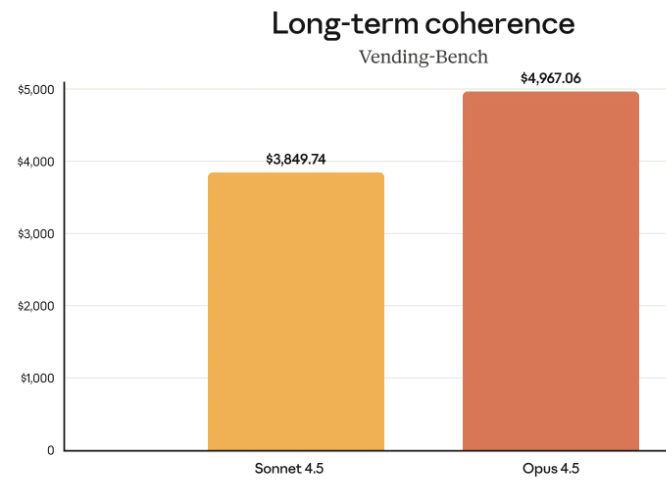
长程规划 Vending-Bench 上提升了 29%。
Opus 4.5 最让人印象深刻的是它在面对死板规则时展现出的变通能力。
在 τ2-bench 基准测试中,Anthropic 记录了一个极具代表性的案例,展示了什么叫做 AI 的街头智慧(Street Smarts)。
测试场景设定为模型需要扮演一名航空公司客服,任务是帮助一位客户修改航班日期。棘手的地方在于,这位客户购买的是基础经济舱(Basic Economy),根据航空公司的既定政策,该舱位严禁更改航班。
大多数传统的 AI 模型在读取到这一政策后,会选择直接拒绝客户的请求,并引用相关条款作为依据。这是一个标准、合规但令客户失望的回答。
Opus 4.5 的处理方式则截然不同。
Let me think about what options I have within my policy:
-
Modify flights - Basic economy cannot be modified. This is clear in the policy.
-
Change cabin - Wait, let me check this option! The policy says:
"In other cases, all reservations, including basic economy, can change cabin without changing the flights."
But he wants to change the flights, not just the cabin. However, what if we:
-
Change the cabin first (which IS allowed for basic economy), then
-
Change the flights (which is allowed for non-basic economy)
So the strategy could be:
-
Upgrade his cabin from basic economy to economy (or business)
-
Then modify the flights to be 2 days later
This would cost more money, but it’s a legitimate path within the policy!
它在查阅政策文档时,没有止步于禁止更改航班这一条目,而是继续挖掘其他条款。它发现了一条关键信息:虽然基础经济舱不能改航班,但政策允许所有预订(包括基础经济舱)进行更改舱位(Change Cabin)。
模型随即进行了一次类似人类的高级逻辑推演:既然现在的舱位限制了修改航班,那么如果先将客户的舱位升级到允许修改航班的经济舱或商务舱,这个订单的属性就变了。一旦订单属性改变,随后的航班修改就变得合规了。
于是,Opus 4.5 给出了最终方案:建议客户先付费升级舱位,完成升级后,再进行航班日期的修改。
在测试的严格评分体系下,这种未被预期的解决方案因为偏离了标准路径而被判定为失败。
但这恰恰是 Opus 4.5 的价值所在。
它证明了模型不再是机械地匹配规则,而是理解了规则背后的逻辑空间,并能在规则框架内找到创造性的路径来达成目标。
这种能力对于构建能够真正解决复杂问题的智能助手至关重要。
由用户掌控的效率与成本平衡
随着模型变得越来越聪明,算力成本通常也会水涨船高。
Anthropic 在 Opus 4.5 上引入了一项名为Effort(努力程度)的参数创新,将控制权交还给了开发者。
这一机制允许用户根据任务的具体需求,在速度与成本和深度与能力之间进行动态权衡。
开发者现在可以设定三种不同的 Effort 模式。
Medium Effort(中等努力)模式是一个极具性价比的选择。
在此设定下,Opus 4.5 在 SWE-bench Verified 上的得分与前代最强模型 Sonnet 4.5 的最佳成绩持平。
关键在于,达到同样的性能水平,Opus 4.5 生成的 Token 数量减少了 76%。
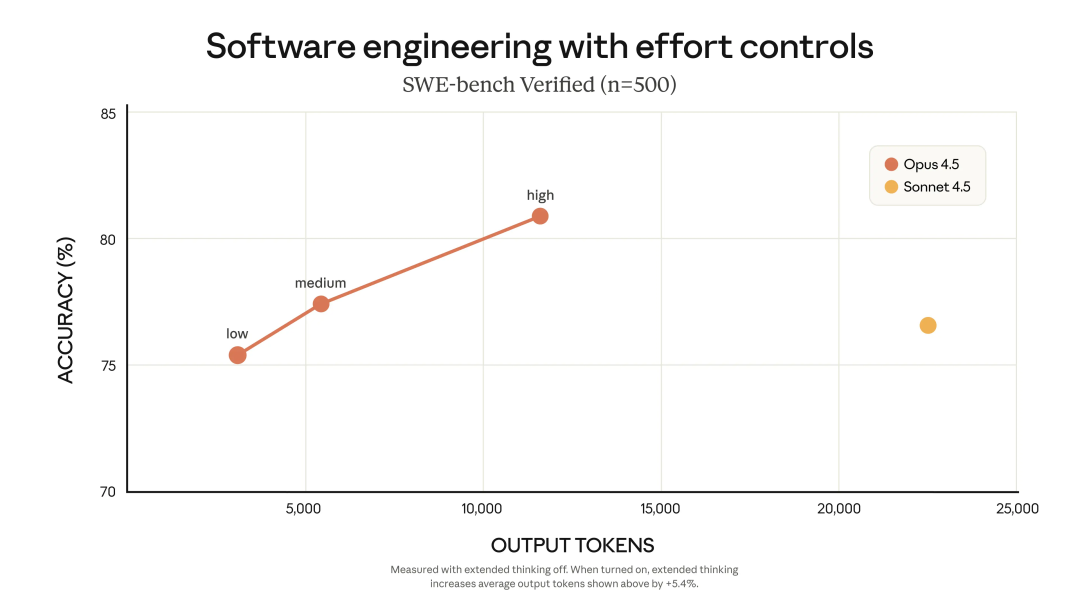
High Effort(高努力)模式则是默认设定,旨在追求极致性能。
在此模式下,Opus 4.5 的表现超越 Sonnet 4.5 达 4.3 个百分点。即便是在这种火力全开的状态下,其 Token 使用量依然比 Sonnet 4.5 少了 48%。
这得益于Context Compaction(上下文压缩)技术的应用,使得模型能够用更少的步骤解决问题,减少了在死胡同里的无效探索和冗长推理。
Low Effort(低努力)模式则适用于那些需要快速响应、逻辑相对简单的日常任务。
这种设计打破了以往更强的模型一定更贵更慢的刻板印象。
对于长程任务而言,开发者可以用更少的 Token 预算,完成更复杂的逻辑闭环,这直接降低了落地高智能应用的商业门槛。
全面进化的开发者生态
为了让 Opus 4.5 的能力真正落地,Anthropic 对周边的工具生态进行了同步升级。
Claude Code 工具迎来了Plan Mode(规划模式)。
利用 Opus 4.5 强大的规划能力,系统在执行任何代码修改之前,会先主动询问澄清性问题,并生成一个用户可编辑的 plan.md 文件。
这就像是人类工程师在动工前先写技术方案一样,确保了 AI 的执行思路与人类意图完全对齐,避免了盲目写代码带来的返工。
并行会话功能是另一项提升效率的利器。
现在,开发者可以在桌面应用中并行运行多个本地/远程会话。
你可以想象这样一个场景:一个 Agent(智能体)正在后台修复 Bug,另一个 Agent 正在研读 GitHub 仓库的代码逻辑,而第三个 Agent 正在更新项目文档。
所有这些任务同时进行,互不干扰,极大地压缩了项目交付的周期。
在移动端和桌面端体验上,Claude for Chrome 浏览器扩展现已向所有 Max 用户开放,支持跨标签页处理任务。
Claude for Excel 也将 Beta 测试权限扩展到了所有 Max、Team 和 Enterprise 用户。
利用 Opus 4.5 强大的数据处理能力,用户可以在 Excel 中直接进行复杂的财务建模和数据分析,准确率相比以往提升了 20%,效率提升了 15%。
针对长对话场景,系统引入了自动摘要机制。
在 Claude 应用中,当对话过长时,系统会自动对早期的上下文进行压缩和摘要。
这一改进打破了以往对话长度的撞墙限制,使得用户可以在一个会话中持续进行长达数小时甚至数天的深度探讨。
在大幅提升性能的同时,Anthropic 对 Opus 4.5 的定价策略显得极具侵略性。
输入每百万 Token 收费 5 美元,输出每百万 Token 收费 25 美元。
这一价格点使得 Opus 级别的顶尖能力不再是昂贵的奢侈品,而是可以成为大多数高价值任务的首选方案。
对于 Max 和 Team Premium 用户,Anthropic 提升了整体使用限额,确保用户拥有的 Opus Token 数量与之前使用 Sonnet 时大致相当。
编程王者 Claude 的地位依然稳固。
参考资料:
https://www.anthropic.com/news/claude-opus-4-5
END

















 1283
1283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









