



香港大学研究团队开发出一种基于忆阻器的自适应模数转换器,在将能效提升15.1倍的同时,实现了超分辨率精度,解决了存内计算系统中最关键的信号转换瓶颈。

深度学习模型的规模正在以指数级速度增长,数以亿计的参数运算量让传统的冯·诺依曼架构不堪重负。
计算单元与存储单元分离的物理结构,导致数据在两者之间频繁搬运,由此产生的存储墙问题不仅限制了速度,更消耗了大量能源。
存内计算(Compute-in-Memory, CIM)技术应运而生,它通过在存储阵列内部直接完成计算,极大地减少了数据移动。
在众多CIM方案中,利用忆阻器(Memristor)交叉阵列执行模拟向量矩阵乘法(VMM)是最具潜力的方向之一。
然而,现实往往卡在最后一公里:模拟信号必须转换回数字信号才能被后续电路处理。这一重任落在模数转换器(ADC)肩上。
这是一个关于木桶效应的故事。
在现有的混合信号CIM系统中,ADC成了最短的那块木板。
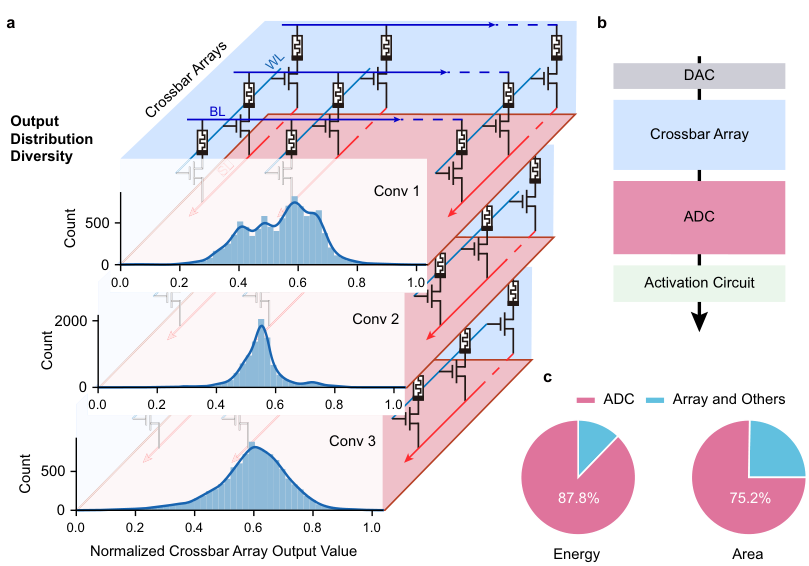
数据表明,在最先进的CIM实现中,ADC竟然占据了高达87.8%的总能耗和75.2%的芯片面积。
不仅如此,神经网络不同层级、不同通道的输出分布千差万别,传统ADC固定的量化方式要么精度不足,要么资源浪费严重。
针对这一痛点,研究人员摒弃了传统思路,利用忆阻器的可编程特性,设计了一种基于模拟内容寻址存储器(Analog CAM)的自适应ADC。
这种设计不追求消除器件变异,反而利用变异来提升精度,最终实现了能效与精度的双重突破。
存内计算与自适应架构设计
我们先剖析一下问题的本质。
典型的CIM系统是一个混合信号系统:数字信号通过数模转换器(DAC)进入模拟交叉阵列,阵列完成乘加运算后输出模拟电流或电压,再由ADC转回数字信号进入激活函数电路。
这里的核心矛盾在于多样性与刚性的冲突。
神经网络在推理过程中,权重分布和输入模式在不断变化。
卷积神经网络(CNN)的不同卷积层,其输出数据的统计分布形状各异。有的层输出集中在低值区,有的则分布广泛。
现有的解决方案大多在做无奈的妥协:
低精度均匀量化(6位以下)虽然硬件简单、省电,但会粗暴地丢失信息,导致模型准确率下降。
高精度均匀量化虽然准,但硬件开销是指数级增长的,这会让CIM原本的能效优势荡然无存。
理论上的自适应算法(如Lloyd-Max)虽然能根据数据分布调整量化边界,但一直缺乏高效的硬件支撑。
要想破局,必须让硬件本身活起来。
研究团队提出了一种全新的解决方案:用忆阻器构建量化单元(Q-cell),直接在模拟域实现可编程的阈值检测。
整个ADC的核心不再是复杂的比较器阵列,而是一个个精巧的Q-cell。
每个Q-cell包含两个忆阻器、五个晶体管以及两个反相器。这个结构的巧妙之处在于它构建了一个可编程的电压分压器网络。
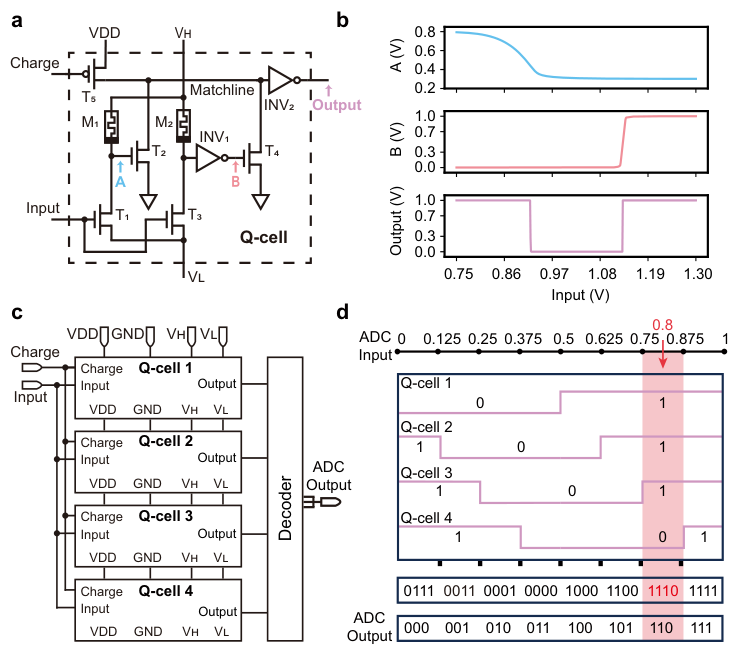
它的工作逻辑非常直接。电压分别施加在由忆阻器和晶体管构成的分压电路上。通过精细调节忆阻器的电导值,可以直接设定该单元对输入电压的响应范围。
当输入电压落在设定的上下边界之间时,电路匹配线(Match Line)保持高电平,经过反相器后输出逻辑0;一旦超出范围,匹配线放电,输出逻辑1。
这是一个一步到位的Flash型转换逻辑,但没有传统Flash ADC那庞大的面积开销。
为了实现多比特量化,设计采用了重叠边界机制。以3位ADC为例,系统使用了4个Q-cell。不同于传统ADC将电压范围切成互不重叠的小段,这里的Q-cell被编程为具有特定重叠区域的电压范围。
例如,四个Q-cell的有效响应范围可能被分别设定为(0, 0.5)、(0.125, 0.625)、(0.25, 0.75)和(0.375, 0.875)。当一个0.8V的输入信号到来时,它只落在第四个Q-cell的区间内(0.75-0.875)。此时,只有第四个Q-cell输出0(激活),其余输出1。这种独特的激活模式生成了1110的代码,解码器随后将其转化为二进制的110。
为了极致利用忆阻器的动态范围,设计中还引入了双偏置策略。
左侧输入晶体管接收覆盖整个输入范围的偏置电压,而右侧仅接收一半。
这种不对称设计保证了无论是设定高阈值还是低阈值,忆阻器都能工作在最佳的电导区间内,避免了器件工作在极端高阻或低阻态带来的不稳定性。
从实验室到物理实现
纸上谈兵终觉浅,硬件设计必须通过流片验证。
研究团队基于标准的微纳加工工艺,制造了8×8的忆阻器阵列来验证这一架构。
器件采用Pt/TaOx/Ta的三明治结构,中间的氧化钽(TaOx)层厚度仅为5纳米,是发生阻变的关键区域。
制备过程在硅晶圆上进行,利用电子束蒸发沉积电极,并通过反应溅射形成功能层。
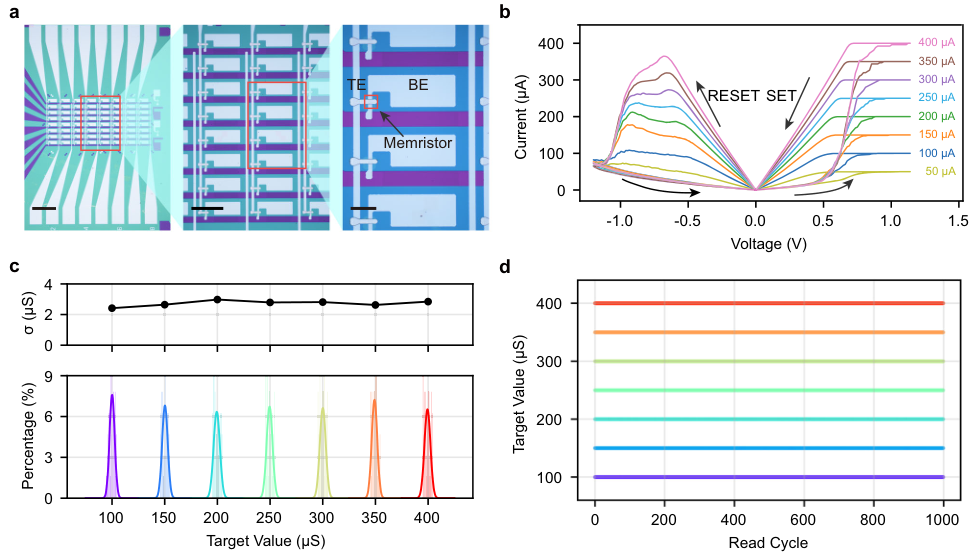
实测数据展示了这种器件惊人的稳定性。在控制编程依从电流的情况下,器件可以精准地呈现出多级电导状态,这是实现可编程量化边界的物理基础。
针对64个器件的统计分析显示,在100微西门子(µS)到400微西门子的工作范围内,器件间的电导变异标准差仅为2.73µS,相对偏差小于1%。这意味着大规模制造的一致性得到了保证。
更重要的是耐久性。
在超过3000万次的开关循环测试中,器件依然保持稳定的开关窗口。
对于ADC这种写入操作(即调整量化边界)相对不频繁的应用场景,即便每天重新校准1000次,器件的使用寿命也能达到87年。这完全消除了对新型存储器件寿命短的顾虑。
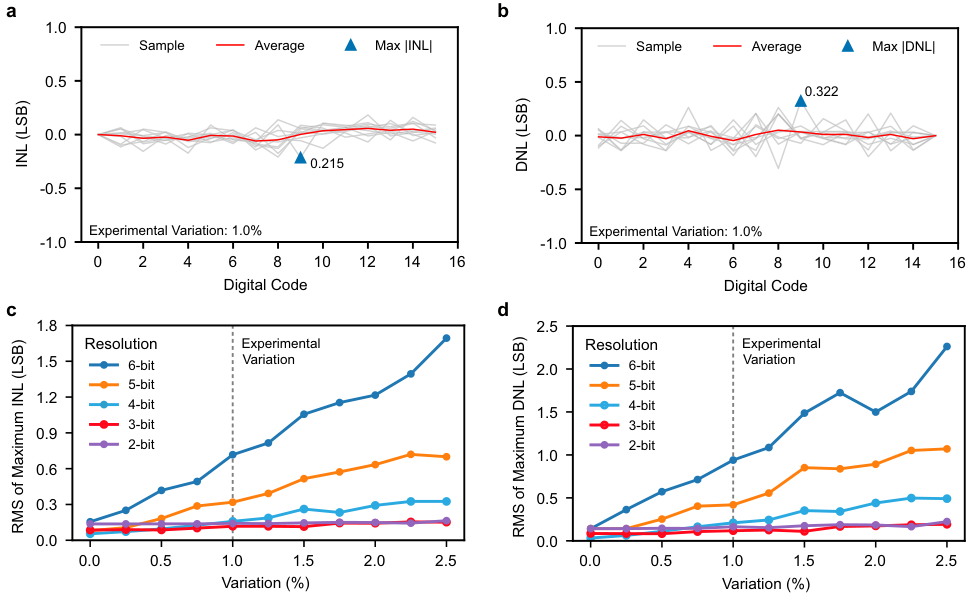
在线性度指标上,4位ADC的实验测量结果显示,最大积分非线性(INL)和微分非线性(DNL)分别被控制在0.215 LSB和0.322 LSB以内。
即使到了5位精度,在考虑实验变异的情况下,RMS值依然保持在0.319 LSB和0.419 LSB的优异水平。
这些硬指标证明了该设计不是实验室的玩具,而是具备工业应用潜力的精密模拟电路。
这项研究最令人拍案叫绝的部分,在于它如何处理误差。
在模拟硬件领域,器件变异(Device Variation)通常是工程师的噩梦。
两个理论上完全一样的忆阻器,实际导电性能总会有细微差别。这种差别会导致量化边界发生偏移,从而引入误差。
但研究团队反其道而行之,开发了一套超分辨率(Super-resolution)策略,将变异变成了提升精度的工具。
这个策略利用了成对ADC之间的分歧。假设我们有两个ADC,它们被编程为拥有相同的量化边界。由于物理变异的存在,这两个边界在实际电压轴上会有一点点错位。
当输入电压恰好落在两个边界之间的狭窄区域时,两个ADC会给出不同的输出结果。
普通的设计会认为这是错误,但在这里,这种不一致本身就是极高价值的信息。它直接告诉系统:输入信号不仅在某个大区间内,而且精确地落在了那个微小的错位区间里。
通过识别这种边界近似状态,系统可以推断出比单个ADC分辨率更高的数值。这就像是用两把刻度线稍微错开的尺子去测量同一个物体,通过观察刻度的对齐情况,读出比最小刻度还要精细的数值。
实验结果验证了这一策略的威力。
在ResNet18网络对ImageNet数据集的分类任务中,利用这种超分辨率策略,4位量化的准确率被提升到了34.8%,比理论上的理想自适应量化还要高出4个百分点。
在6位精度下,准确率达到了65.5%,相比传统的均匀量化提升了整整17.3%。
硬件的物理缺陷,通过算法的智慧,变成了性能的增益。
软硬协同的自适应量化流程
为了将上述硬件潜力转化为实际的神经网络性能,团队设计了一套完整的软硬件协同工作流。
这不仅仅是硬件的胜利,更是算法的胜利。
首先是离线统计。
系统在代表性的训练数据集上运行推理,收集每一层卷积层输出的详细统计特征。这一步相当于给神经网络照X光,看清楚数据的骨架和分布。
接下来是边界优化。
利用修正的Lloyd-Max算法,根据收集到的分布数据,计算出均方误差(MSE)最小的最佳量化边界。这一步是纯数学的优化,确保每一级量化电平都用在刀刃上。
最后是硬件映射。
系统将优化好的边界参数,转化为具体的电导值,通过编程脉冲写入到忆阻器阵列中。由于忆阻器是模拟器件,写入过程采用了编程-验证机制,确保实际电导值与理论值的误差极小。
在推理阶段,每个Q-cell就带着这些量身定制的边界在工作。这种量身定制的效果是显著的:在VGG8网络上,自适应量化将均方误差从均匀量化的14.99猛降至3.10。
颠覆性的能效、面积优势与鲁棒性
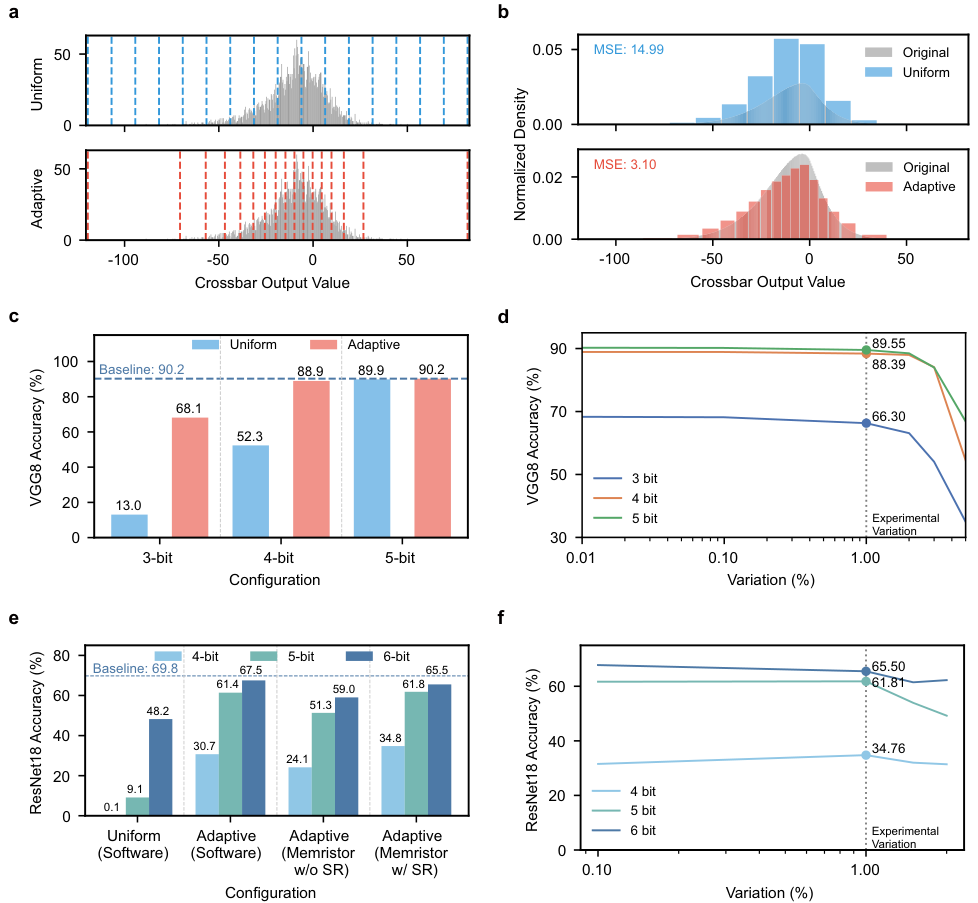
在半导体行业,评价一个设计好坏最硬的指标就是PPA(性能、功耗、面积)。研究团队将该设计与过去27年(1997-2024)在ISSCC和VLSI等顶级会议上发表的ADC设计进行了全方位对比。
结果是碾压级的。
在能效方面,该设计实现了每次转换仅消耗12.58飞焦耳(fJ)。与同类最佳的传统设计相比,能效提升了15.1倍。
在面积方面,一个5位ADC的核心面积仅为24.29平方微米(基于16nm节点估算)。这比传统最紧凑的ADC缩小了12.9倍。
这种微型化和低功耗特性,使得在每一列交叉阵列甚至每几个列就配备一个专用ADC成为可能,从而彻底打开了CIM系统的并行处理带宽。
从系统层面看,这种改变是结构性的。
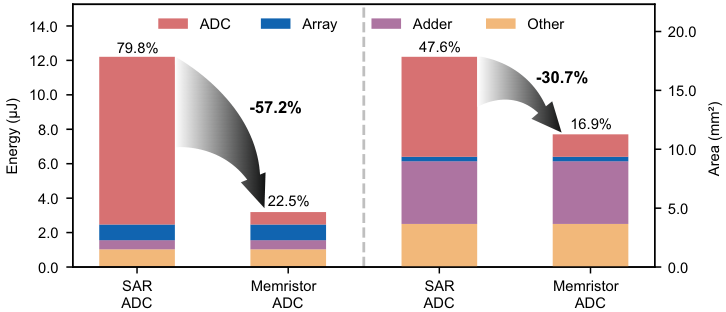
在VGG8的完整CIM实现中,引入该ADC后,原本占据近八成能耗的ADC部分,占比直接降到了22.5%。
整个系统的能耗降低了57.2%,芯片面积节省了30.7%。对于更复杂的ResNet18网络,系统能耗也降低了56.9%。
此外,这种Flash式的直读架构带来了极低的延迟。转换时间仅为0.165纳秒,比基于斜坡比较的忆阻器ADC快了近200倍(32纳秒 vs 0.165纳秒)。
斜坡型ADC需要像爬楼梯一样逐级比较,而该设计则是一眼看穿,速度优势不言而喻。
芯片在真实环境中工作,面临着电源噪声和温度漂移的挑战。
仿真显示,该ADC对高频动态电源噪声有极强的免疫力。即便电源电压出现20mV的峰峰值波动,5位ADC的线性度误差(INL)依然稳稳控制在0.5 LSB以下。
对于静态的直流漂移(DC Drift),这套架构展现出了独特的原位自愈能力。传统的电路需要复杂的补偿电路来抵消漂移,而这里,只需要重新编程忆阻器的电导值即可。
既然量化边界是由忆阻器电导决定的,当环境导致电压基准漂移时,只需将忆阻器设定到一个新的电导值,就能在新的偏置条件下复现原本的逻辑阈值。这种无需额外硬件的校准能力,是传统模拟电路难以企及的。
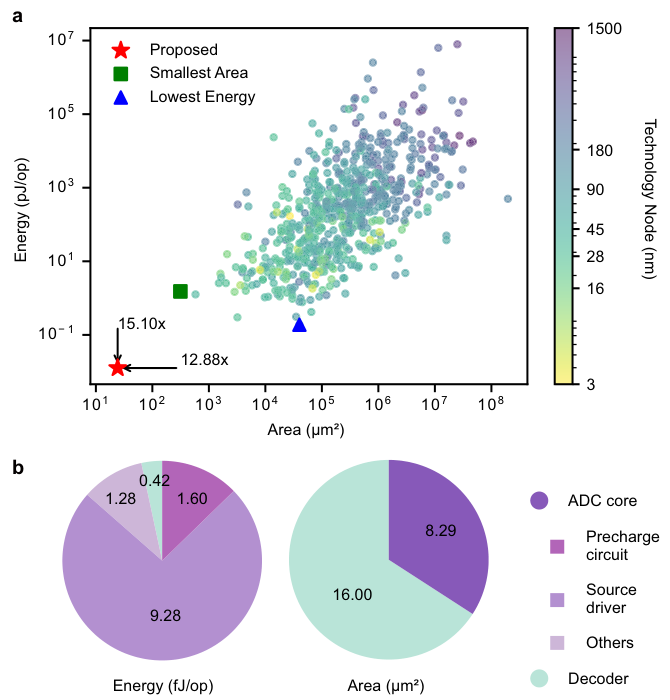
这项工作证明了在后摩尔定律时代,通过器件物理特性与计算算法的深度融合,完全可以突破传统架构的性能天花板。
忆阻器在这里不再仅仅是存储数据的容器,而是变成了一把可伸缩、可调节的智能尺子。
通过让这把尺子主动适应数据的形状,并巧妙利用制造过程中的微小瑕疵,研究团队在极低的功耗和面积下实现了高精度的信号量化。
对于边缘计算、物联网设备以及所有对能效有苛刻要求的AI应用来说,这种基于忆阻器的自适应ADC技术,不仅仅是一个组件的升级,更是通向高效智能计算的一把关键钥匙。
当硬件开始学会适应数据,计算的效率才真正开始起飞。
参考资料:
https://www.nature.com/articles/s41467-025-65233-w

















 1986
1986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









