



大模型在复杂任务中表现惊人,却在简单逻辑变体上频频翻车。
这种高分低能的悖论,是如何产生的?
伊利诺斯大学、华盛顿大学、普林斯顿大学、哈佛大学等组成的一个跨学科研究团队,发布了一项重磅研究。

研究人员通过引入认知科学框架并重构推理结构,让AI学会像人一样思考,带来高达66.7%的性能跃升。
大语言模型正经历前所未有的能力大爆发。它们能写出精妙的代码,通过高难度的专业考试,甚至在某些领域展现出超越人类专家的知识储备。
在这个光鲜亮丽的表象之下,隐藏着一个让研究者深感困惑的现象:这些通过了图灵测试级别的庞然大物,往往会在极其简单的逻辑变体问题上摔跟斗。
这种高基准性能与低泛化能力之间的巨大撕裂,提醒我们:模型输出的正确答案,可能并非源于我们所理解的推理,而是某种基于概率的统计拟合。
现在的训练和评估体系,太过于关注结果的正确性,却从未真正审视过产生这些结果的认知过程。这导致我们无法分辨,模型究竟是在进行真正的逻辑推演,还是在进行一场高明的死记硬背。
为了解开这个黑箱,一个跨学科研究团队通过合成数十年的认知科学研究成果,建立了一套包含28个认知元素的分类体系,并对18个主流模型进行了史上最大规模的实证分析。
这是对机器思维的一次全面体检,更是一次试图弥合人类认知与人工智能鸿沟的深刻尝试。
搭建思维的脚手架
要理解AI为什么不会思考,我们必须先定义什么是思考。
认知科学领域的大师大卫·马尔(David Marr)曾提出过著名的分析层次理论,将信息处理系统分为计算层、算法层和实现层。
以此为基础,我们可以将推理这项复杂的心理活动,拆解为四个相互交织的核心维度。
想象一个正在玩乐高积木的孩子,他的目标是搭建一艘太空飞船。这个过程完美地具象化了我们提出的认知分类体系。

孩子心中清楚,这艘飞船不能自相矛盾。他不能同时认为这个机翼很稳固又认为它马上要掉下来。
这种对一致性的追求,就是逻辑连贯性。这是有效推理必须满足的计算目标。
飞船是由积木块组成的,红色的透明驾驶舱这个概念,是由颜色、部件类型和材质属性组合而成的。理解整体必须基于理解部分及其组合规则,这就是组合性。
更重要的是,孩子学会了搭飞船,稍微变通一下就能搭出城堡、恐龙或者飞机。
利用有限的积木块和组合规则,生成无限的新创意,这种能力被称为生产力。它是区分真正的智能与机械记忆的分水岭。
这一切操作,都不是在语言层面完成的,而是在孩子的大脑中,基于对物体属性的抽象理解进行的。这种在语言表达之前的抽象表征操作,叫做概念处理。
这四个要素——逻辑连贯性、组合性、生产力、概念处理,构成了推理的宪法,也就是推理不变量。它们规定了什么是有效的推理,无论是在人脑中,还是在硅基芯片上。
拥有了规则,还需要指挥官。孩子在动手前会问自己:我擅长搭这个吗?积木够不够?这就是自我意识。
他会观察周围:现在是比赛时间,我要搭快点,还是现在是自由玩耍,我可以慢慢试。这种对环境约束的感知,是情境意识。
基于这些判断,他会决定策略:是先在脑子里想好全图(自上而下),还是一块块拼着看(自下而上)?这属于策略选择。
由于目标宏大,他需要把造飞船拆解为造机身、造机翼、装驾驶员。在过程中,因为缺零件,他可能要把装轮子的目标换成装滑撬。这种动态调整,是目标管理。
在搭建的每一步,他都在看:机翼歪了吗?这样搭结实吗?这种持续的监测和修正,就是评估
这五项能力组成了元认知控制。它们不直接参与搭建,但决定了搭建的方向和质量。当前的AI模型,恰恰在这里表现出了最大的缺失。
指挥官下令后,大脑需要调取图纸和知识。这些知识是如何组织的?
最简单的是顺序组织,像菜谱一样,第一步做什么,第二步做什么。这在大模型中最为常见。
但世界往往更复杂。飞船由机身、机翼组成,机翼又由板材和连接件组成,这种父子嵌套关系是层级组织。
机身支撑机翼,引擎提供动力,这种错综复杂的关联构成了网络组织。
除此之外,还有按优劣排序的序数组织,理解前因后果的因果组织,安排先后顺序的时间组织,以及处理空间位置关系的空间组织。
最后,是将图纸变为现实的具体动作。
孩子需要从杂乱的积木中找到相关的几块,排除干扰,这是选择性注意。他需要把大问题拆成小问题,解决后再合起来,这是分解与整合。
当发现机翼装不上去时,他可能会回退几步,重新设计,这叫回溯。或者他突然发现,其实只要把机翼倒过来装就行了,这种视角的转换叫表征重构。
他还会运用正向链式推理(从零件推导整体)和反向链式推理(从目标反推零件)。
这28个认知元素,共同构成了一个完整的思维闭环。任何一个环节的缺失,都会导致推理的崩塌。
错位的智能:模型在什么时候变笨
为了验证这套理论,研究团队对18个开源模型(包括Qwen3、DeepSeek-R1、Olmo-3等)进行了地毯式测试,收集了近20万条推理轨迹,并将其与人类的思考过程进行对比。
分析结果令人不安。模型在认知元素的使用上,展现出了一种与任务难度完全倒挂的逆向关系。
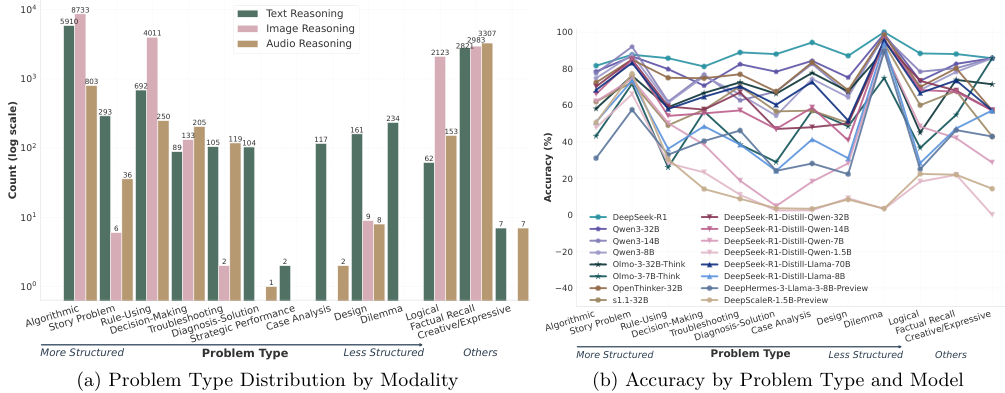
在处理结构良好的简单问题(如算法题、规则应用)时,模型表现得像个全能选手,广泛调用了各类认知工具。此时,它们的行为丰富度极高。
一旦进入结构不良、没有标准答案的复杂领域(如案例分析、设计问题、伦理困境),模型却突然变得畏手畏脚。
它们抛弃了多元化的思考策略,退缩到最原始、最僵化的模式:顺序组织、逻辑连贯性检查和正向链式推理。
这恰恰是错误的应对方式。
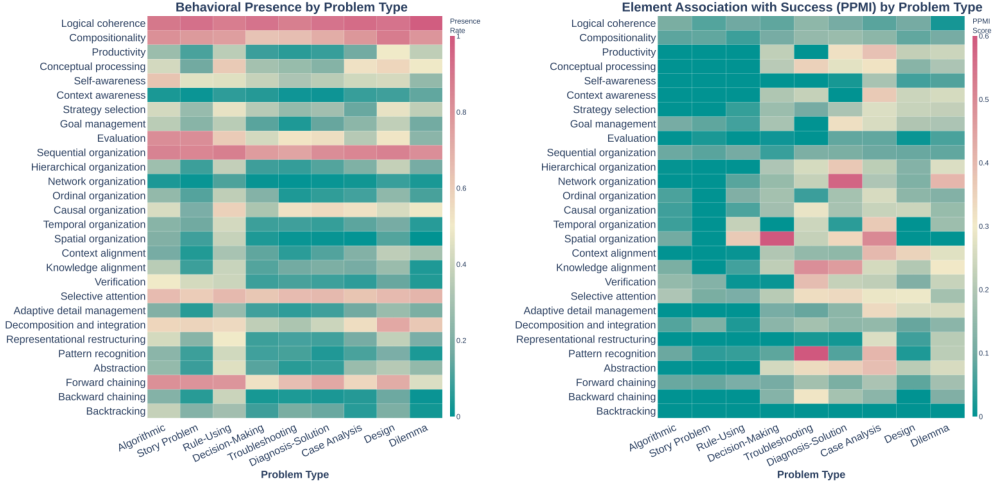
数据热图清晰地显示,在解决复杂问题时,成功的推理轨迹往往包含了丰富的空间组织、网络组织、反向链式推理和表征重构。也就是说,越是困难的问题,越需要灵活多变的思维策略。
现在的模型,学会了在不需要花样的地方耍花枪,却在最需要变通的关头,只会一条道走到黑。
它们在设计问题上的表现尤其糟糕,因为它们缺乏构建空间关系和因果网络的能力,只能试图用线性的文字序列来描述立体的、动态的系统。
更有趣的是执行差距。
模型非常频繁地进行逻辑连贯性检查(出现率91%),看起来很严谨。
但统计显示,这一行为与最终能否答对问题几乎没有正相关性(PPMI仅为0.091)。
这意味着,模型虽然经常嘴上说要检查逻辑,甚至识别出了矛盾,但它们根本无法有效地解决这些矛盾。这是一种有识别、无修正的无效努力。
同样的情况也发生在元认知评估上。
模型经常输出让我看看这样对不对,但在那些缺乏明确真值的开放性问题中,这种自我评估往往流于形式,变成了一种毫无意义的口头禅,完全起不到纠偏的作用。
机器的冲动与人类的定力
当我们把人类的思考过程和AI的推理轨迹放在显微镜下对比时,这种差异变得更加触目惊心。
研究提取了算法问题和诊断问题的典型推理结构图。这不仅是看用了什么招式,更是看招式的连招顺序。
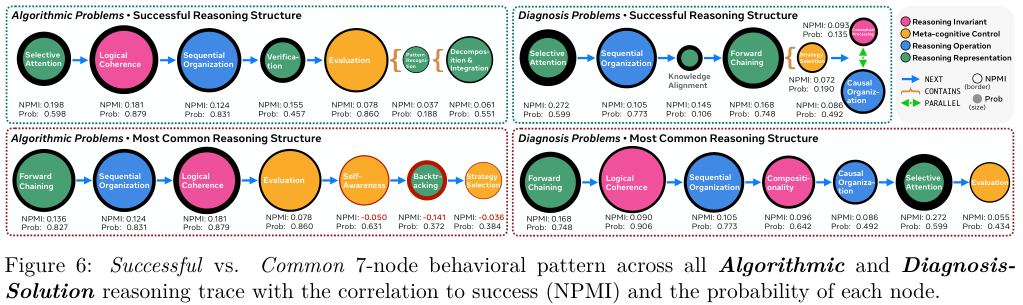
在面对一个复杂的诊断问题(比如找出系统故障的原因)时,人类专家和成功的推理轨迹展现出了一种深思熟虑的定界策略。
人类通常的路径是:选择性注意 → 顺序组织 → 知识对齐 → 正向链式推理。
翻译过来就是:先观察现象,过滤噪音;再理清步骤;然后调动相关的专业知识储备,确认问题的边界和约束条件;最后才开始推导结论。
这是一套先谋后动、先问是什么再问怎么办的成熟思维模式。
而AI模型最常用的路径是什么?
正向链式推理。
是的,几乎没有前戏。模型倾向于跳过所有的定界、分析和约束检查阶段,直接冲进解决方案的推导中。
这种过早的求解冲动,解释了为什么模型经常生成看似通顺但完全不符合现实约束的幻觉答案。
它们就像一个急于抢答的学生,题目还没听完就喊出了答案。
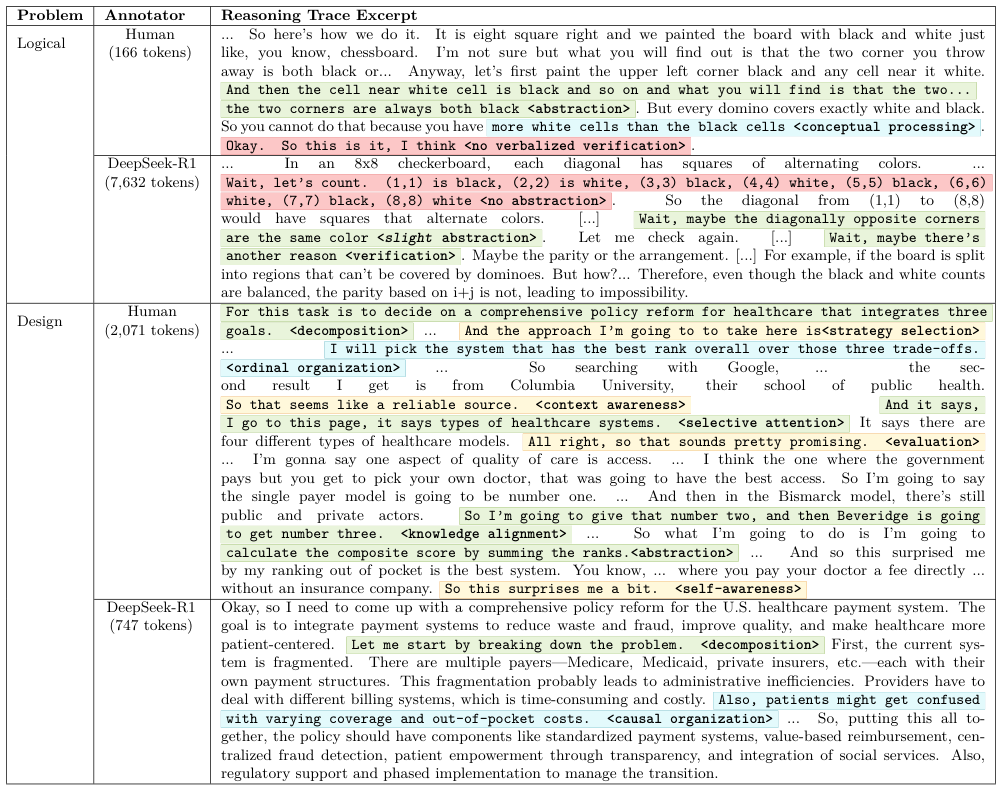
在微观层面,人类的思考轨迹中充满了抽象和概念处理。
面对逻辑难题,人类会迅速提取核心概念,剥离无关细节,这使得人类的推理往往更短、更高效。
相比之下,LLM更依赖于浅层的、冗长的顺序重述和枚举,试图通过罗列所有可能性来撞大运。
此外,人类表现出极强的自我意识(49% vs 19%)。
人类会频繁地停下来确认:我刚才那个假设好像有点问题、这个我不确定。
而AI则表现出一种盲目的自信,或者说,它根本不知道自己知道什么或不知道什么。
AI更多地依赖反向链式推理和生产力(即生成新内容)。
这可能是因为模型倾向于将中间推理步骤全部外化写出来,而人类则将这些步骤在脑海中隐式处理了。
重塑认知:教AI学会慢思考
既然找到了病灶——模型在复杂问题上缺乏正确的认知结构,那么治疗方案也就呼之欲出了。
研究团队提出了一种名为认知结构引导(Cognitive Structure Guidance)的测试时干预技术。
原理很简单:既然我们已经通过大数据挖掘出了各类问题下最成功的推理结构图,为什么不在提问时,直接把这张思维导图交给模型呢?
研究者将那些成功的图结构转化为线性的提示指令。
比如,在问一个诊断问题时,不再只是扔给模型一个问题,而是引导它:
-
首先,请识别出关键信息,并明确问题的约束条件;
-
然后,回忆相关的专业知识框架;
-
最后,再基于上述信息进行推导。
这一干预产生的效果是立竿见影的。
实验结果表明,这种外部施加的认知脚手架,能显著提升模型的推理性能。
特别是对于Qwen3系列和DeepSeek-R1等具备较强基础能力的现代模型,效果尤为惊人。

在诊断问题上,Qwen3-7B的准确率提升了66.7%。
在伦理困境问题上,Qwen3-14B的准确率提升了60.0%。
这个结果证明了一个极其重要的事实:现在的模型其实潜藏着解决复杂问题的能力,只是它们不知道在什么时候该用什么招式。
它们就像一个武学奇才,内功深厚,但临敌经验不足,容易乱打一气。
一旦有一位明师在旁指点剑路,立刻就能发挥出惊人的威力。
当然,这种方法并非万能药。
对于参数量较小、基础能力较弱的模型(如DeepScaleR-1.5B),强行施加复杂的认知结构反而会导致性能下降。
这说明,要理解并执行这种高级的思维指导,模型本身需要具备一定的指令遵循能力和认知灵活性。
这就像把一套高深的剑谱教给一个刚入门的学徒,不仅没用,反而会让他手忙脚乱。
我们不仅要关注结果
这项研究不仅是对模型的一次诊断,更是对整个人工智能研究社区的一次反思。
通过对arXiv上近1600篇相关论文的元分析,研究发现了一个明显的设计-行为差距。
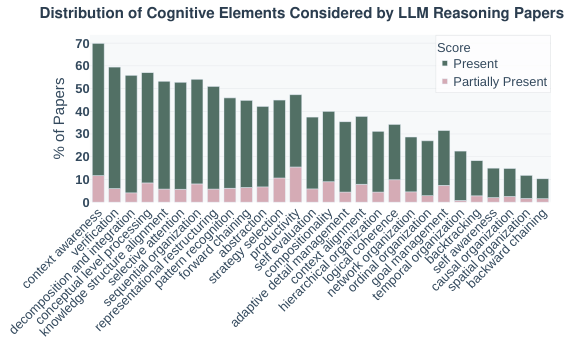
目前的AI研究高度集中在那些容易量化的认知元素上。
约55%的论文关注顺序组织,60%关注分解与整合。
因为这些线性的、程序化的步骤很容易写成代码,也很容易评分。
然而,那些对真正的高级智能至关重要的非线性能力,却被系统性地忽视了。
仅有16%的论文涉及自我意识,10%涉及空间组织,22%涉及时间组织。
这种研究偏差导致了我们现在的模型呈现出一种偏科的状态:它们是优秀的执行者,能完美地执行线性的指令序列,但它们是拙劣的思考者,缺乏对自我状态的感知,缺乏对时空关系的深层理解,更缺乏在复杂环境中动态调整策略的元认知能力。
这也解释了为什么我们在训练中明明加入了思维链(CoT),模型却往往只是学到了思维的皮毛(格式),而没有学到思维的灵魂(结构)。
我们奖励的是最终答案的正确,而不是中间思考过程的合理。
这就好比只要学生蒙对了答案就给满分,长此以往,学生自然只会钻研蒙题技巧,而不会去真正理解题目。
未来的AI进化之路,必须从单纯的算力堆叠,转向对认知架构的精细雕琢。
我们需要开发能够预测认知能力涌现的训练理论,而不仅仅是看着Loss曲线下降;我们需要设计能够奖励元认知监控的目标函数,让模型学会三思而后行;我们需要构建能够惩罚僵化策略的训练环境,逼迫模型跳出舒适区,去探索更复杂的思维路径。
这不仅是让AI变得更聪明,更是为了让我们更了解智慧本身。
通过在硅基上重建人类的认知结构,我们或许能反过来,从另一个视角看清人类思维的本质。
毕竟,真正的智能,不在于算得有多快,而在于想得有多深。
参考资料:
https://arxiv.org/abs/2511.16660
https://github.com/pkargupta/cognitive_foundations
END

















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









