



单张 GPU 也能同时运行多个大模型微调实验,Hugging Face TRL 库正式集成 RapidFire AI,将大模型开发从低效的串行试错带入超并行时代。

开源社区迎来了一次重要的技术融合。Hugging Face 宣布其核心微调库 TRL(Transformer Reinforcement Learning,Transformer 强化学习)正式集成 RapidFire AI。
这是对大模型后训练阶段工作流的重构。
RapidFire AI 引入的超并行实验引擎,通过自适应分块调度技术,让开发者在硬件资源不变的情况下,将实验验证速度提升了 16 到 24 倍。
对于深受算力瓶颈困扰的个人开发者与中小团队,这意味着可以用消费级显卡完成过去需要集群才能承担的超参数搜索任务。
随着 Llama、Qwen 以及 DeepSeek 等高质量开源基座模型的普及,大模型开发的重心已彻底转移。
从头预训练(Pre-training)成为少数巨头的游戏,绝大多数开发者和企业面临的核心任务是后训练(Post-training)。
这包括监督微调(SFT)、直接偏好优化(DPO)以及近期因 DeepSeekMath 而备受关注的群组相对策略优化(GRPO)。
这个阶段看似门槛降低,实则对精细化操作的要求极高。
面对一个新的业务场景,开发者往往会陷入巨大的超参数搜索空间中。
学习率设定为 2e-4 还是 5e-5,直接决定了模型是快速收敛还是发生灾难性遗忘。
LoRA 的秩(Rank)选择 8、64 还是 128,需要在参数效率与模型表现力之间寻找微妙平衡。
Batch Size(批次大小)与梯度累积步数的组合,既关乎显存占用,又影响训练的稳定性。
优化器选择 AdamW 还是 Lion,调度器使用 Cosine 还是 Constant,每一个选择都是一个变量。
在 RapidFire AI 介入之前,算力受限的团队通常采用低效的串行试错模式。
开发者配置好参数 A,运行 2 小时,观察 Loss(损失)曲线,发现效果不佳,修改参数为 B,再运行 2 小时。
这种模式下,反馈周期极长,一天往往只能验证 3 到 4 个想法。
这种时间成本迫使许多开发者放弃了科学的对比实验,转而掉入直觉陷阱。
他们倾向于凭经验或照搬社区的默认参数直接开始训练,错失了模型性能提升的最佳配置,导致最终交付的模型效果平庸。
虽然市面上存在 Ray Tune 或 Optuna 等超参数优化工具,但它们的设计逻辑通常基于集群假设。
这些工具假定用户拥有海量计算资源,可以为每个实验分配独立的 GPU。
当用户只有 1 到 2 张 A100 或 H100 时,这些工具只能退化为普通的串行队列管理,无法解决核心的效率问题。
RapidFire AI 正是为了打破这一僵局而生,它的目标是在有限的硬件上,通过算法与工程优化,榨干每一滴算力。
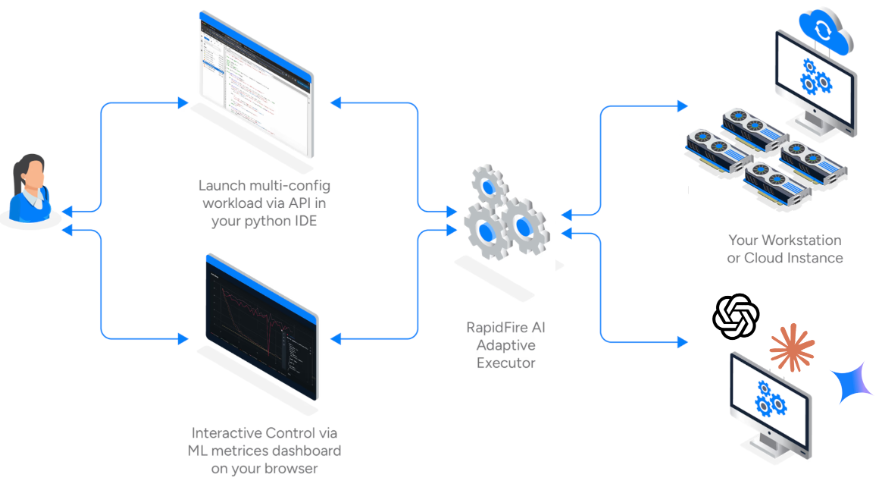
RapidFire AI 技术架构与超并行机制
RapidFire AI 是一个专为大语言模型定制化(包括微调与 RAG 评估)设计的实验执行引擎。
它的核心价值不在于更快地完成单一模型的训练,而在于更快地获得不同配置间的比较结果。
它通过自适应分块调度技术,实现了在单 GPU 上并发推进多个实验配置。
自适应分块调度(Adaptive Chunk-based Scheduling)是其最底层的核心逻辑。
传统训练模式是将整个数据集一次性输入给模型 A,跑完一个 Epoch(周期)或全部 Step(步数)后再轮到模型 B。RapidFire AI 则将数据集切分为多个微小的块(Chunks)。
工作流变得完全不同。
系统首先提取数据块 1,加载配置 A 进行训练,随后快速切换到配置 B 训练同一个数据块,以此类推。
当所有配置在数据块 1 上都完成训练后,系统会立即进行评估,并根据表现决定是否进入数据块 2。
这种机制带来了极具价值的早期信号。开发者无需等待数小时,往往在几分钟内,当第一个数据块处理完毕,就能看到所有配置在相同数据分布下的 Loss 曲线对比。
如果配置 C 的表现显著劣于其他组,系统或用户可以立即终止该实验,将释放出的算力分配给表现更好的配置 A 和 B。
频繁切换模型配置通常会带来巨大的显存加载与卸载开销,导致计算效率下降。
RapidFire AI 的工程团队为此实现了一套高效的共享内存机制。
在 PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)场景下,这一机制发挥了巨大作用。
基座模型(如 Llama-3-8B)的权重被锁定驻留在显存中,不随实验切换而移动。
不同实验配置之间差异的仅仅是 LoRA Adapter 的权重或超参数设置。
由于 Adapter 的参数量相对于基座模型极小,RapidFire AI 能够以极低的延迟在显存中热切换这些 Adapter。
这种设计消除了传统模型切换的 I/O 瓶颈,使得 GPU 的计算单元利用率从传统的 60% 提升至 95% 以上。
交互式控制操作(IC Ops)是 RapidFire AI 区别于传统 HPO 工具的另一大杀手锏。
传统工具是静态的,设定好搜索空间后只能被动等待结果。
RapidFire AI 提供了动态干预能力。开发者可以在训练过程中实时监控仪表盘。
如果发现配置 A 表现优异,但推测更大的学习率可能带来更好效果,可以直接在控制台执行 Clone-Modify(克隆并修改)操作。
系统会克隆配置 A 当前的状态,修改学习率,立即分叉出一个新实验继续运行。
同样,Warm-Start(热启动)功能允许利用表现最好的中间检查点开启新的探索分支,而 Prune(剪枝)功能则支持手动或自动终结表现差的陪跑配置。
Hugging Face TRL 的生态地位与痛点
理解此次集成的意义,需要先厘清 TRL 在 Hugging Face 生态中的位置。
TRL 是一个全栈库,旨在将强化学习等先进技术应用于 Transformer 语言模型的后训练阶段。
它拥有三大核心功能模块:SFT、DPO 和 GRPO。
SFTTrainer 是业界进行指令微调的标准工具,它封装了复杂的 Prompt 格式化、数据打包等逻辑,极大地降低了微调门槛。
DPO 则成为了 2023 年至 2024 年的主流对齐算法,它不需要单独训练奖励模型,直接利用偏好数据优化策略,比传统的 PPO(Proximal Policy Optimization,近端策略优化)算法更稳定且节省显存。
GRPO 是近期源自 DeepSeekMath 的前沿算法,与 PPO 依赖单一 Critic 不同,GRPO 通过对同一个 Prompt 生成一组回复,计算组内相对优势。
这种方法对于数学推理、代码生成等存在标准答案或可验证性的任务极其有效。
尽管 TRL 极大简化了算法的代码实现,但它并未解决调参难题。
特别是 GRPO 这类新算法,对 Group Size(组大小)、Beta 值以及学习率等超参数极其敏感。
TRL 用户为了获得理想效果,往往需要编写大量脚本来循环运行不同的参数组合。
这种重复且低效的劳动正是 RapidFire AI 介入的最佳切入点。
此次 Hugging Face 官方博客的发布,标志着 RapidFire AI 正式成为 TRL 生态的一等公民。
集成的最大亮点在于零代码修改的体验。
RapidFire AI 为 TRL 的核心 Trainer 提供了即插即用的替代品。
SFTConfig 对应 RFSFTConfig,DPOConfig 对应 RFDPOConfig,GRPOConfig 对应 RFGRPOConfig。
这种命名上的对应关系意味着 TRL 的老用户几乎不需要改变他们的心智模型。
在代码层面,这种转变显得尤为简洁。
传统 TRL 写法中,用户定义 SFTConfig 并实例化 SFTTrainer,然后调用 train 方法。
而在 RapidFire AI 集成写法中,用户只需导入 RapidFire 的 Experiment 和 AutoML 模块。
通过 RFModelConfig 定义多个包含不同 RFSFTConfig 的配置组,放入 RFGridSearch 中。
最后,实例化 Experiment 并调用 run_fit 方法。

仅仅几行代码的变动,工作模式就从串行跑一个实验变成了并行跑 N 个实验。
在架构层面,RapidFire AI 建立了一个三方通信架构。
IDE 或 Python 进程负责用户定义的实验逻辑。
多 GPU 执行后端利用 TRL 的 Trainer 接口,但在数据加载器(Dataloader)层面进行了分片劫持,并通过共享内存管理模型权重。
MLflow 仪表盘则实时接收所有并发实验的指标。
当用户调用 run_fit 时,RapidFire AI 接管了 TRL 的训练循环。
在每个数据块的边界,它会挂起当前 Trainer 的状态,保存轻量级的 Checkpoint,然后唤醒下一个配置的 Trainer。
由于集成深度到了 TRL 内部,这种切换对 PyTorch 而言是透明且安全的。
集成带来的效能质变
官方基准测试显示,在单张 A100 显卡上对比 4 到 8 个配置,传统串行模式需要 120 到 240 分钟,而 RapidFire AI 模式仅需 7 到 12 分钟即可在首个数据块上获得具有统计意义的对比结果。
这不仅是时间的节省,更是认知迭代速度的质变。开发者可以在一杯咖啡的时间里验证多种假设,而不是等待整晚。
GPU 利用率的提升是另一个显著收益。
在串行实验中,GPU 经常因为数据处理、模型保存、代码切换等原因处于闲置状态。
RapidFire AI 的流水线设计使得 GPU 计算单元始终处于饱和状态。
对于按小时计费的云 GPU 用户,利用率从 60% 飙升至 95% 以上直接等同于成本的大幅降低。
对于 GRPO 等复杂算法的调参难题,这一集成提供了完美的解决方案。
GRPO 引入了 num_generations 参数,即每个 Prompt 生成多少个回复用于对比。
如果该值设置过小,策略优化的方差会变大,模型难以学到有效特征。
如果设置过大,显存压力剧增,训练速度极慢。
使用 RapidFire AI,开发者可以同时设定 4、8、16 三组配置。
在第一个 Chunk 跑完后,如果发现 16 的显存压力过大或速度过慢,而 8 的 Reward(奖励)增长曲线与 16 相当,就可以果断砍掉 16,专注于 8。
这种动态决策能力在传统模式下是无法实现的。
交互式修正功能引入了 Human-in-the-loop(人在回路)的实验理念。
训练过程中发现 Loss 不降是常态。
过去只能杀掉任务,修改代码重新排队。
现在,开发者可以在 Dashboard 上暂停实验,选择该实验并点击 Clone,将学习率减半,选择 Warm Start 继承刚才的权重,点击 Resume 继续运行。模型训练从未如此灵活且具有掌控感。
Hugging Face 一直致力于 AI 的民主化。
如果说 TRL 降低了 RLHF 的算法门槛,那么 RapidFire AI 则大幅降低了算力门槛和工程门槛。
它让只有一张 RTX 4090 等消费级显卡的学生或个人开发者,也能像拥有 H100 集群的大厂工程师一样,科学地进行超参数扫描和模型对比。
这种能力的下放将极大地激发开源社区的创新活力。
虽然目前的集成重点在于微调,但 RapidFire AI 的架构同样支持 RAG 系统的评估。
随着 TRL 开始探索 Agent 环境,例如集成 OpenEnv,RapidFire AI 的并发评估能力将成为优化 Agent 决策逻辑的关键工具。
未来,我们有理由期待 RFRLOOConfig(Reinforcement Learning with Online Outcomes)等更多高级配置的加入,进一步丰富实验场景。
AI 开发工具链正在向精细化、自动化、交互化方向演进。
对于致力于在大模型时代保持竞争力的开发者而言,掌握这一套工具链,是从盲目炼丹转向科学实验的关键一步。
无需等待,不再盲猜,现在的你可以在单卡上即刻验证十种微调策略。
参考资料:
https://huggingface.co/blog/rapidfireai
END


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









