



历史总是押着相同的韵脚在前行!
著名科技领域战略分析师 Benedict Evans 发布了第三份题为《AI 吞噬全世界》的重磅报告。

在科技产业的分析领域,Benedict Evans 是一个无法绕开的名字。
作为前 Andreessen Horowitz(简称 a16z)的合伙人,以及曾在 Enders Analysis 和 Orange 担任战略顾问的资深分析师,Evans 擅长通过宏观数据与历史周期的对比,抽丝剥茧地还原技术变革的本质。
他并不沉迷于单纯的技术参数,而是更关注技术如何转化为商业价值,以及这一过程中产生的经济摩擦。
这份题为《AI eats the world》的报告,剥离了围绕在生成式 AI 周围的营销泡沫,直击行业的底层逻辑:资本支出(CAPEX)的恶性通胀、应用场景的某种停滞、以及技术从新奇事物向基础设施演进过程中的必然阵痛。
硅谷弥漫着一种精神分裂般的气息。
一边是英伟达和台积电的生产线冒着火星,另一边是企业 CIO 看着不知如何落地的 AI 试点项目发愁。
Evans 站在 2025 年的时间节点,剥开了这层光怪陆离的外壳。他没有谈论那些令人昏昏欲睡的参数细节,而是把目光投向了钱的流向、电的缺口以及人类习惯的惰性。
科技行业的历史就是一部平台更迭史。
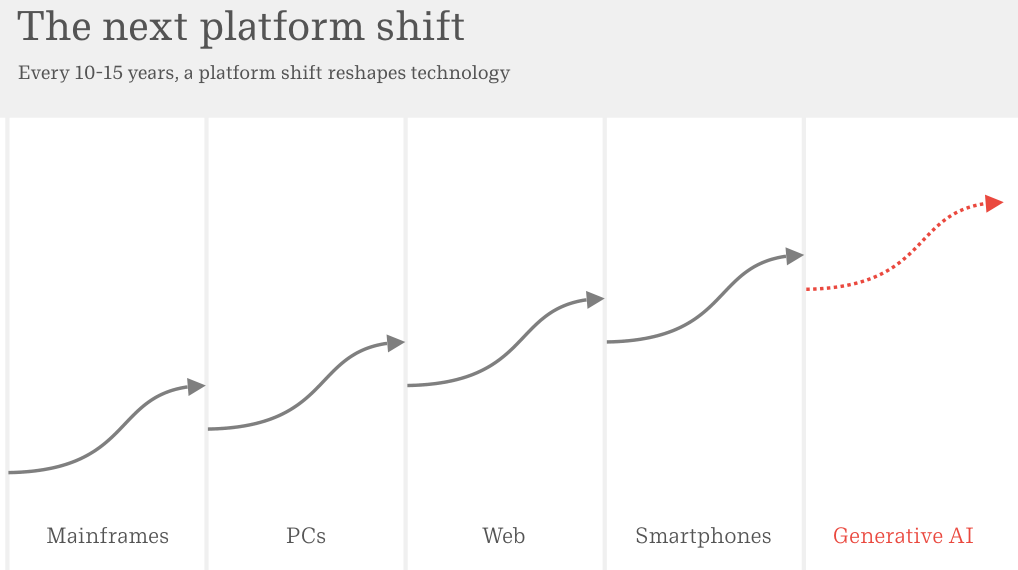
我们经历过大型机(Mainframes)、个人电脑(PCs)、互联网(Web)和智能手机(Smartphones)。
每一个周期大约持续 10 到 15 年。
现在轮到了生成式 AI(Generative AI)。这条曲线看起来无比熟悉,但这次有点不一样。
以前无论是摩尔定律还是光纤带宽,我们大致知道明年会发生什么。
现在的我们面对大语言模型,就像盯着一个黑盒。
DeepMind 的创始人 Demis Hassabis 说得很直白,通往通用人工智能(AGI)的道路还需要多次未知的突破。
我们不知道 Scaling Law 定律什么时候会撞墙,也不知道现在的投入是不是在往无底洞里扔钱。
平台转移通常有三个步骤。
第一步是内部技术重构(Inside tech),新的守门人出现,价值链被打碎重组。
第二步是外部技术渗透(Outside tech),新工具开始改变卖鞋的、卖保险的以及拍电影的。
第三步是残酷的洗牌,早期赢家往往死在沙滩上。
PC 时代的早期霸主不是最后的赢家,移动互联网时代的 Nokia 和 BlackBerry 如今只活在回忆里。
现在 OpenAI 和 NVIDIA 看起来不可一世,但历史告诉我们要对这种暂时性的垄断保持怀疑。
焦虑的美金与物理世界的报复
数据不会撒谎,但数据会让人心惊肉跳。
2025 年,微软(Microsoft)、谷歌(Alphabet)、亚马逊(AWS)和 Meta 这四家公司在资本支出(CAPEX)上的预算接近 4000 亿美元。
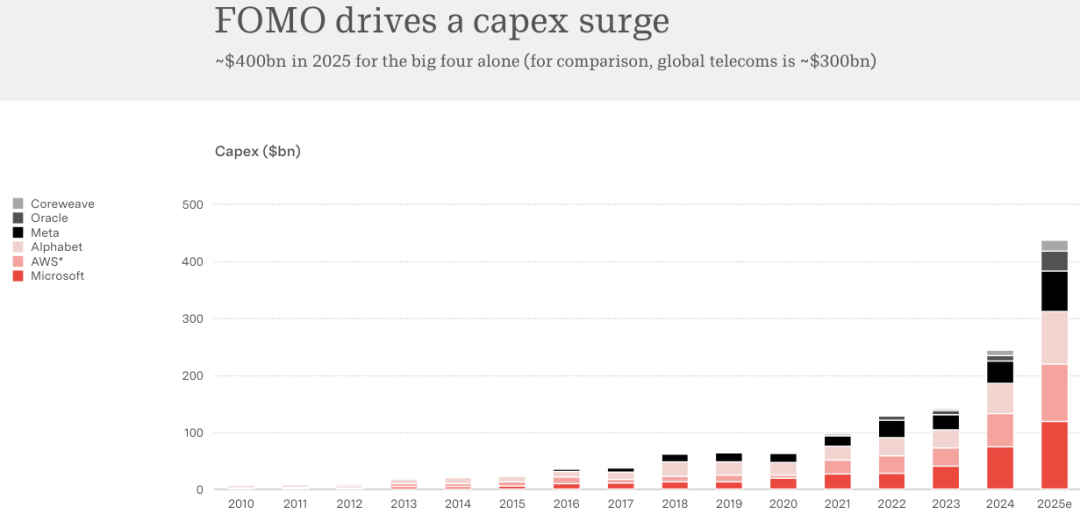
全球电信行业为了维持地球上的通信网络,每年的总资本支出也就 3000 亿美元。
石油和天然气行业的上游投资大约是 5400 亿美元。
这四家科技公司在 AI 基础设施上的投入,已经快要赶上全人类挖石油的钱。
这不是理性的财务决策,这是博弈论中的死局。
谷歌 CEO Sundar Pichai 在 2024 年就说了,投资不足的风险远大于投资过度。
Meta 的扎克伯格说得更轻巧,最坏的情况无非是提前建好了未来几年的容量。
每一家巨头都被错失恐惧症(FOMO)死死掐住咽喉。谁都不敢停下来,谁停下来谁就可能是下一个雅虎。
这种恐慌性投资带来了一个有趣的现象:资本租赁(Capital Leases)规模垂直攀升。
有些公司的云资本支出甚至超过了相关收入的 100%。
这是一种极其激进的财务杠杆。巨头们用手中的自由现金流(FCF)做燃料,试图烧出一个未来。
只要增长曲线还是指数级的,这个游戏就能玩下去。一旦曲线变平,这就是一场巨大的灾难。
钱可以印,但电不能。芯片也不能凭空变出来。
软件工程师习惯了代码世界的无限扩展,但 AI 数据中心是实打实的物理存在。
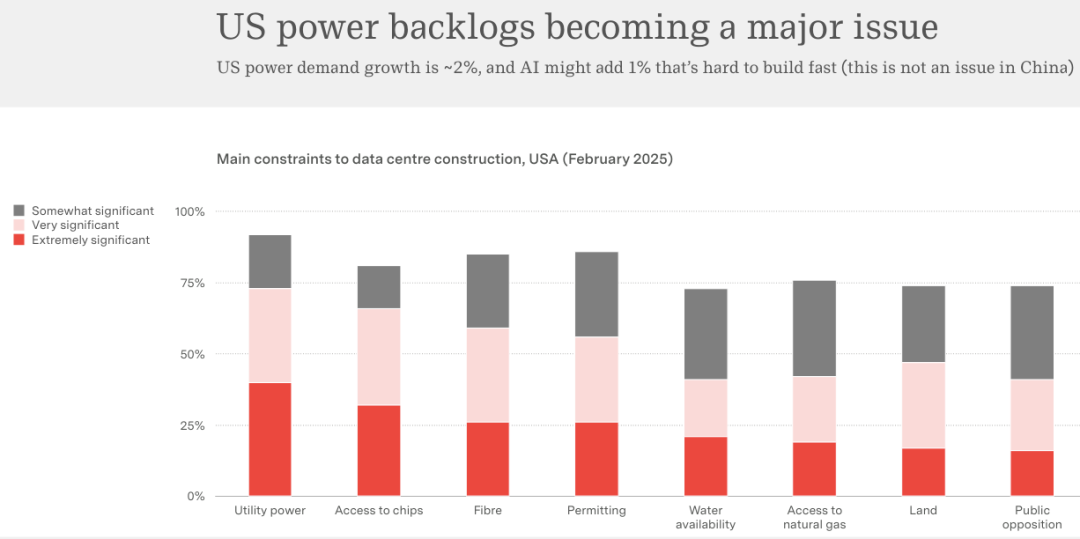
它需要钢筋水泥,需要冷却水,最需要的是电。美国电网已经老了。电力需求的年增长率只有 2%,而 AI 带来的额外 1% 需求是硬生生挤进来的。
施耐德电气(Schneider Electric)在 2025 年 2 月做了一项调查。
阻碍美国数据中心建设的第一大瓶颈不是缺钱,也不是缺芯片,而是缺电。排在后面的才是芯片获取和光纤铺设。
台积电的工厂里机器轰鸣,但也跟不上英伟达的订单。
英伟达的营收曲线就像是被什么东西拽着直冲云霄。这背后隐藏着一种极其脆弱的供应链关系。
即使你有无限的美元,从沙子变成 H100 显卡也需要物理时间。
更有趣的是这个行业内部的资金流向。Evans 称之为循环收入(Circular Revenue)。
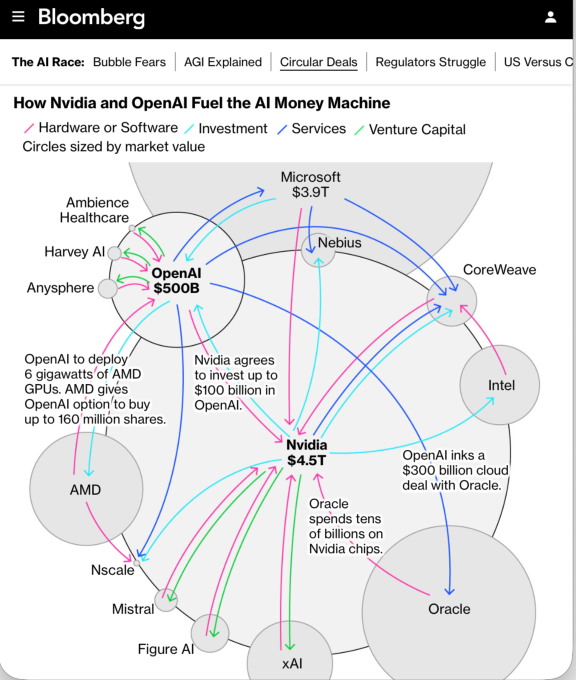
我们来追踪一下这笔钱的旅行路线。
微软给 OpenAI 投了几百亿。OpenAI 转手把这笔钱交给微软的 Azure 云服务买算力。Azure 转手把这笔钱交给英伟达买显卡。英伟达赚得盆满钵满,反手投资了 CoreWeave 这样的算力租赁公司。CoreWeave 再拿着英伟达的钱买英伟达的显卡。
这就像是一个完美的内循环。大家都在记账,大家的收入都在涨。
但这中间缺少了一个关键环节:真正的终端用户在哪里?
如果最终没有一个卖鞋的、卖汉堡的或者写代码的人为这些算力买单,这个循环就是建立在沙滩上的城堡。
OpenAI 需要靠巨头输血来维持昂贵的推理成本(Inference Cost),它自己还没有形成正向的现金流造血能力。
拿着锤子找钉子的尴尬期
资本端热火朝天,应用端却冷静得可怕。
ChatGPT 确实有 8 亿的周活跃用户(WAU)。但只有 5% 的人愿意为它付费。
更糟糕的是,大多数用户并不是每天都用它。数据展示了一个明显的实验多,日常使用少的特征。
人们因为好奇注册了账号,问了几个傻问题,然后就把它扔在一边。
真正把它整合进日常工作流(Daily Workflow)的人是少数。
企业端的情况也差不多。
埃森哲(Accenture)等咨询公司签了很多生成式 AI 的合同,但这更多是企业在交学费。
麦肯锡(McKinsey)的数据很诚实。除了 IT 部门和软件开发部门,其他像人力资源、供应链、制造这些核心业务部门,AI 的部署率低得可怜。绝大多数项目都停留在试点(Pilot)阶段。
为什么?因为企业不是赌徒。
企业不能容忍一个只有 80% 准确率的员工,自然也不能容忍一个胡说八道的 AI。
幻觉问题(Hallucinations)在写诗的时候是浪漫,在做财务报表的时候就是犯罪。
数据隐私是另一个拦路虎。
没有哪个大公司愿意把核心机密上传到别人的云端。
还有那些跑了 20 年的 ERP 系统,那是企业的神经中枢,想把最新的 LLM 接进去,技术难度不亚于给飞行中的飞机换引擎。
目前真正跑通的场景只有吸收(Absorb)类。这类场景有一个共同点:显而易见、低风险。
最典型的是编程。GitHub Copilot 这样的工具已经成了标配。
Vibe coding成了一个新词,它代表了软件开发的一个新抽象层。以前我们用汇编,后来用 C 语言,再后来用 Python,现在我们用自然语言。这大幅降低了写代码的门槛。
另一个是营销。联合利华(Unilever)和欧莱雅(L’Oréal)正在用 AI 生成广告素材。成本降低了,素材数量提升了 10 到 20 倍。这很实用,但这只是让现有的工作更快,并没有创造出以前不存在的新工作。
模型白菜价与杰文斯悖论
大家都在卷模型,结果就是模型越来越像。
截至 2025 年 10 月,不管是 OpenAI、Google Gemini、Anthropic Claude,还是来自中国的 DeepSeek,顶尖模型在 MMLU-Pro 这种通用基准测试上的得分差距已经微乎其微。
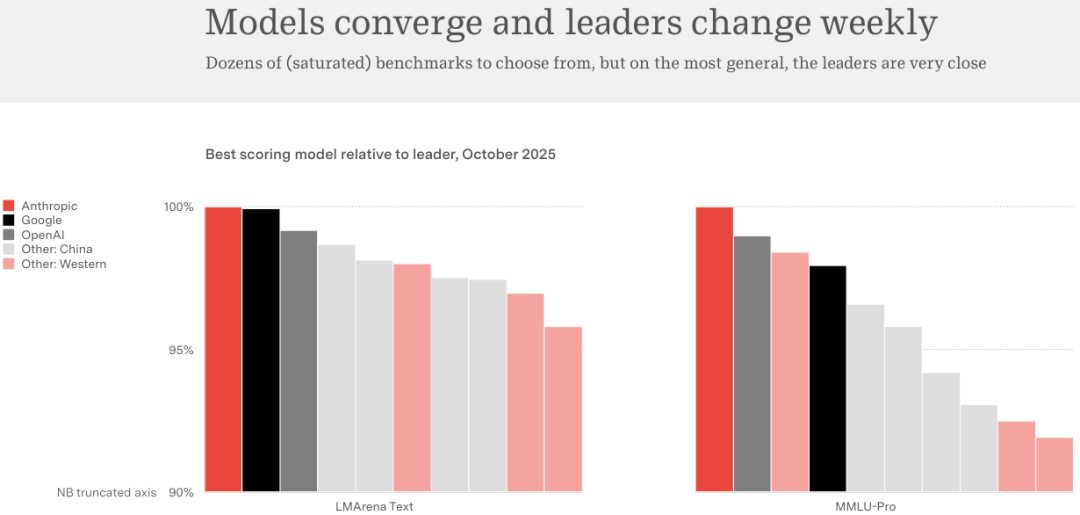
这是一个残酷的信号:拥有最好的模型不再是护城河。模型正在变成像电力、石油一样的商品。
如果模型是商品,那么价值会流向哪里?
Evans 给出了两个方向。
一个是向下游(Down the stack)。谁能把规模做到极致,谁就能赢。这是云服务商(AWS, Azure)和芯片制造商(Nvidia, TSMC)的游戏。
另一个是向上游(Up the stack)。谁拥有网络效应,谁拥有专有数据,谁拥有极致的产品体验,谁就能赢。
这就是为什么微软虽然投了 OpenAI,但它的股价逻辑已经变了。它正在从一个靠网络效应赚钱的软件公司,变成一个靠资本准入赚钱的基础设施公司。
经济学里有一个反直觉的理论叫杰文斯悖论(Jevons Paradox)。
19 世纪的人们认为,改进蒸汽机提高煤炭利用效率,会减少煤炭的使用。
结果恰恰相反。效率提高了,使用成本降低了,煤炭的用途被极大地扩展了,总消耗量反而暴涨。
AI 也是一样。
当智能的成本趋近于零,我们不会只用它来做现在做的事。
AI 给了企业无限的实习生(Infinite Interns)。这不意味着企业会裁掉所有员工。这意味企业会去做以前因为成本太高而做不起的事。
以前,只有 VIP 客户才能享受一对一的专人服务。现在,AI 可以让每一个买牙刷的用户都享受到这种服务。
以前,把一段三行字的要点扩充成一封邮件需要人写五分钟。现在,AI 可以在一秒钟内把这三行字变成 300 个不同版本的广告文案,投放到不同的渠道。
1900 年,蒸汽机给英国提供了相当于其人口总数 5 倍的劳动力。
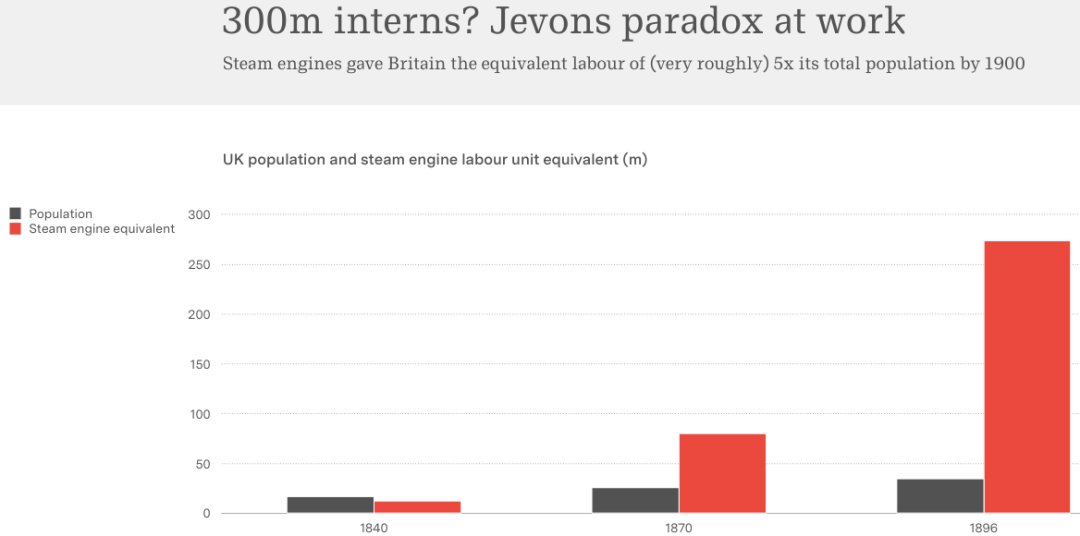
2025 年,LLM 给我们提供了 3 亿个乃至 30 亿个数字实习生。
我们不需要像对待人类那样对待它们。我们不需要付社保,不需要担心它们请病假。我们只需要学会如何核查(Verify)它们的工作。
这里不仅是替代,更是解绑(Unbundling)。
互联网解绑了报纸。分类广告去了 Craigslist,新闻去了 Twitter。LLM 将会解绑更多复杂的任务束。
我们现在还在用 AI 做加法,比如在搜索结果旁边加一个摘要。未来我们会用 AI 做减法,直接解决问题,而不是给你十个链接让你自己找答案。
从功能到颠覆的漫长征途
技术落地从来不是一蹴而就。
Evans 提出了一个三阶段模型:吸收(Absorb)、创新(Innovate)、颠覆(Disrupt)。
我们现在正处在最基础的吸收阶段。
我们只是在用 AI 自动化那些显而易见的任务,比如写邮件、写代码。这只是把 AI 当作现有流程的一个功能(Feature)。
接下来的创新阶段,我们会看到新的产品形态。就像 Uber 利用了智能手机的定位功能创造了新的打车模式,而不是仅仅把出租车公司的电话搬到网上。
最后的颠覆阶段,是重新定义问题本身。
现在的搜索还是给你一堆链接。未来的 AI 应该直接给你答案。现在的电商还是给你推荐一卷打包胶带。未来的 AI 应该通过你买胶带这个行为,推断出你在搬家,然后直接给你推荐保险、灯泡和搬家公司的一整套解决方案。
这需要时间。云技术(Cloud)说了这么多年,到现在也只占了企业工作负载的 30%。电梯从需要人工操作员到完全自动化,用了 50 年。
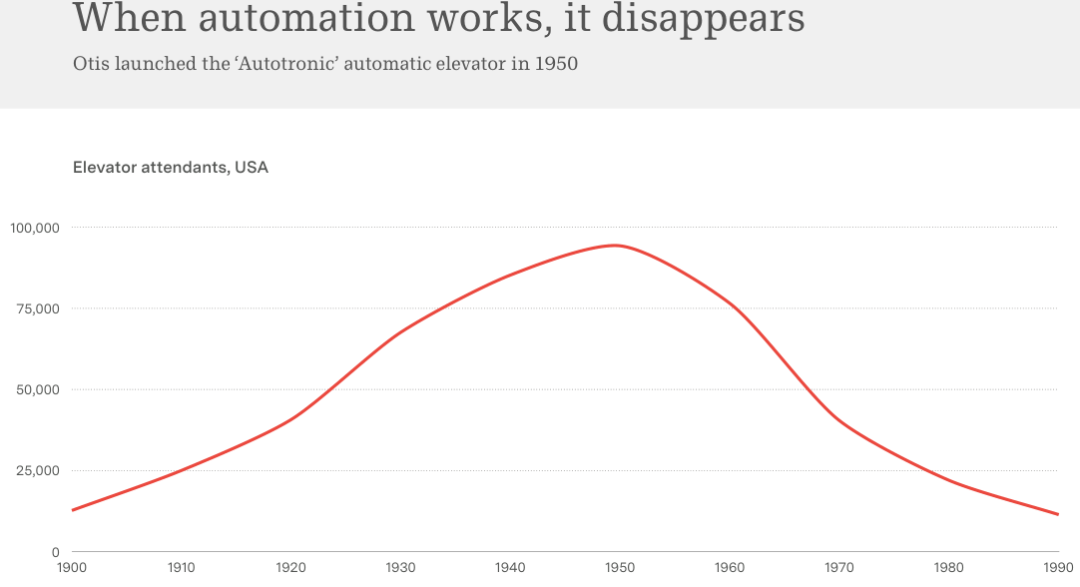
1997 年,《Wired》杂志就发封面文章说Web 已死。那时候互联网确实很难用,只有拨号上网,网页全是乱码。但后来的故事我们都知道了。
今天对 AI 的各种嘲笑和质疑,无论是说它只会一本正经地胡说八道,还是说它找不到商业模式,都像极了当年嘲笑互联网的人。
泡沫确实存在,甚至很大。4000 亿美元的投入在短期内肯定无法收回成本。股市可能会崩盘,公司可能会破产。但技术不会倒退。
AI 不会通过消灭工作来吞噬世界。
它通过提供近乎无限的智能供给,重构我们与信息、与软件、与物理世界的关系。
这是一场漫长的消化过程。
一切才刚刚开始。
参考资料:
https://www.ben-evans.com/presentations
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









