



麻省理工学院何恺明团队发布了一项颠覆性研究,直指当前扩散生成模型的核心痛点。

研究指出:主流模型实际上并没有在做去噪工作,回归最原始的洁净数据预测才是高维像素生成的正解。

不知道何恺明是谁吗?

计算机视觉领域的世界级科学家,现任麻省理工学院副教授。
他最著名的成就是发明了残差神经网络ResNet,这项突破性工作解决了深度神经网络训练中的梯度消失难题,获得了2016年CVPR最佳论文奖,成为人工智能发展的里程碑。
2022年,他入选AI 2000全球最具影响力学者榜单并高居榜首;2023年摘得未来科学大奖数学与计算机科学奖。
何恺明从高考状元到MIT教授,始终致力于构建能理解复杂世界的智能模型,其研究让机器看世界的能力产生了质的飞跃,深刻影响了现代人工智能的发展进程。
扩散模型的预测目标已偏离去噪本质
生成式人工智能领域近年来被扩散模型彻底席卷。
从DALL-E 3到Sora,这些震撼世界的应用背后,核心引擎几乎都是去噪扩散概率模型(DDPM)及其变体。
但当剥开这些复杂系统的外壳,审视其数学核心时,会发现一个有趣的现象:今天的去噪模型,绝大多数并不直接输出去噪后的图像。
回顾扩散模型的发展史,最初的构想确实是单纯的去噪——从一张满是雪花点的损坏图像中恢复出干净的原始画面。
这是一个符合人类直觉的过程。但在模型演进的两个关键节点上,路径发生了偏移。
第一个节点是噪声预测的引入。
研究者发现,让神经网络去预测被添加到图像上的那个噪声,比直接预测图像本身能获得更好的生成质量。这一发现迅速成为了行业标准,DDPM因此名声大噪。
第二个节点是速度预测的提出。
为了将扩散模型与基于流(Flow-based)的方法统一起来,研究者引入了一个结合了洁净数据和噪声的物理量——流速度。
于是,在当前的工程实践中,无论是预测噪声还是预测速度,神经网络的输出目标都变成了某种含噪量。
虽然从数学公式推导上,只要知道了噪声或速度,结合当前时刻的输入,就能反推出洁净图像,这在理论上是等价的。
这种数学上的等价性让学界和业界产生了一种错觉:神经网络足够强大,无论你让它预测什么,只要信息完备,它都能学会。
何恺明团队的这项研究打破了这一沉默的共识。
他们指出,数学上的等价不代表学习难度上的等价。在机器学习的世界里,训练目标的选择至关重要。洁净图像和噪声,在数据分布的几何形态上,有着天壤之别。
这里必须引入一个核心概念:流形假设(Manifold Assumption)。
在计算机视觉的高维空间中,自然图像并不是随机分布的。
一张256x256像素的彩色图片,其可能的像素组合是一个天文数字,但真正看起来像照片的组合只占极小一部分。
这些有意义的图像数据,大致聚集在一个低维的流形上。这就像在三维空间中,一张卷曲的二维纸张。
洁净图像位于这个低维流形上。
但是,噪声是高维的,它弥漫在整个观测空间中。当我们向图像添加噪声时,实际上是将数据点从低维流形推向了广袤的高维荒原。
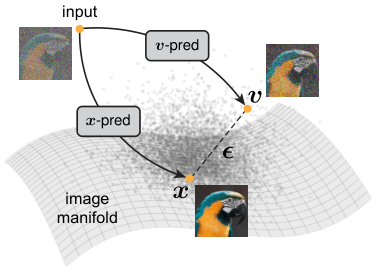
上图清晰地展示了这一几何直觉。洁净图像x稳居流形之上,而噪声ɛ或流速度v则游离于流形之外。
当我们在高维像素空间(Pixel Space)训练神经网络时,如果目标是预测噪声,模型就必须具备极高的容量,因为它需要记住并重建整个高维空间中的随机扰动信息。
这是一种对算力的巨大浪费,也是对模型容量的苛刻挑战。
相反,如果让模型直接预测洁净图像,任务就变得截然不同。
模型只需要学会将高维荒原上的点投影回低维流形上。
它不需要记住噪声的细节,只需要学会忽略它。对于一个容量有限的神经网络来说,丢弃信息(去噪)远比重建信息(预测噪声)要简单得多。
这便是这篇论文的核心论点:在高维空间中,预测洁净数据与预测噪声有着本质的区别。
回归到最基础的去噪任务,让模型直接输出洁净图像,是解决高维生成难题的密钥。
高维空间中的维度诅咒与预测悖论
为了验证流形假设对预测目标的影响,研究团队没有直接在大规模数据集上跑模型,而是设计了一个极其精妙的玩具实验(Toy Experiment)。
这个实验剥离了复杂的干扰因素,直观地展示了维度诅咒是如何摧毁噪声预测模型的。
实验设定非常纯粹。
研究者构建了一个d维的隐含数据,将其通过一个随机生成的正交矩阵投影到一个更高维度的D维观测空间中。
在这个实验中,隐含数据的维度d被固定为2,相当于我们前面提到的那张二维纸张。而观测空间的维度D则是一个变量,从2一直增加到512。
模型方面,研究者使用了一个非常简单的5层多层感知机(MLP),隐藏层宽度固定为256。
这是一个典型的弱模型,特别是当观测维度D达到512时,模型的宽度甚至小于数据的维度,处于欠完备(Under-complete)状态。
实验结果极具冲击力,完美验证了理论假设。
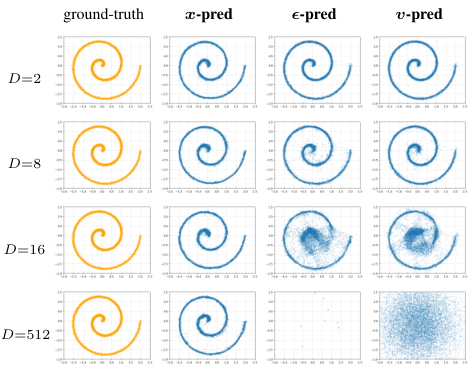
请看上图的数据可视化。每一行代表不同的维度设置,每一列代表不同的预测目标。
当观测维度D=2时,也就是数据维度和观测维度一致时,无论是预测洁净数据、预测噪声还是预测速度,模型都能完美还原出螺旋状的数据分布。此时,噪声预测和数据预测确实是等价的。
当维度增加到D=16时,情况开始发生变化。
预测洁净数据的模型依然稳健,生成的螺旋线清晰可见。但预测噪声和预测速度的模型开始出现抖动和模糊,原本清晰的几何结构变得难以辨认。
当维度飙升至D=512时,灾难发生了。
D=512意味着数据被埋藏在一个巨大的高维空间里,而用于拟合的神经网络只有256维宽。
此时,预测噪声和预测速度的模型彻底崩溃,输出结果变成了一团毫无意义的乱码,完全丢失了数据的结构信息。
然而,令人惊叹的是,直接预测洁净数据的模型在D=512的情况下依然表现完美。
尽管模型是欠完备的,尽管参数量远远少于观测空间的自由度,它依然准确地抓住了那个低维的螺旋结构。
这个实验揭示了一个深刻的数学真理:在高维空间中,噪声的信息量随着维度增长而爆炸性增长,预测它需要匹配的巨大模型容量。
而洁净数据的信息量受限于其低维流形的本质,并不随观测维度的增加而显著增加。
这就是为什么在像素级图像生成中,传统的噪声预测方法会遇到巨大的困难。
图像像素动辄数以万计(例如256x256的图像有近20万维度),在如此高维的空间里预测噪声,就像是试图背诵一本充满了随机字符的天书。
而预测洁净图像,仅仅是让模型学会哪里是字符,哪里是空白。
当前的扩散模型主流架构,如DiT(Diffusion Transformer),为了规避这个问题,通常采用变分自编码器(VAE)作为分词器(Tokenizer),先将高维图像压缩到一个低维的潜在空间(Latent Space)。
在潜在空间里,数据维度大大降低,噪声预测变得可行。
但这种做法引入了额外的复杂性:预训练的VAE、对抗损失、感知损失等,使得整个系统变得臃肿且不透明。
何恺明团队的发现证明,只要选对了预测目标,我们完全可以在原始的高维像素空间直接进行生成,而无需依赖任何降维手段。
极简架构JiT让像素级生成重获新生
基于上述理论发现,研究团队提出了一种极简的架构设计,命名为Just image Transformers(JiT)。
这个名字本身就带着一种返璞归真的自信——仅仅是图像Transformer,除此之外,别无他物。
JiT的设计哲学是对当前复杂架构的一种反叛。
它摒弃了分词器(Tokenizer),不需要预训练的VAE来压缩图像;它摒弃了层次化设计,没有U-Net中复杂的上采样和下采样;它也不需要为了稳定训练而引入的额外损失函数。
它就是一个最朴素的Vision Transformer(ViT),直接作用于原始像素。
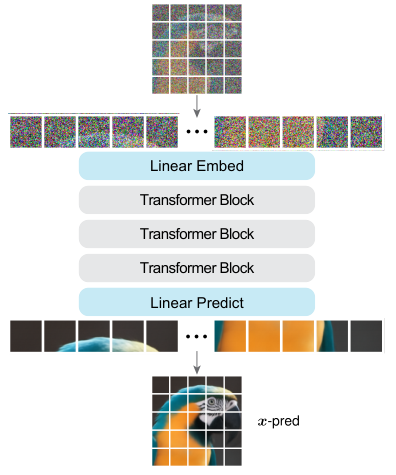
让我们拆解一下这个架构的运作流程。
输入是一张的原始图像。JiT将其切割成非重叠的图块(Patch)。
与标准ViT不同的是,为了应对高分辨率,JiT采用了非常激进的大图块尺寸。
这意味每一个图块转化成的Token,其维度是极高的。一个32 x 32 x 3的彩色图块,展平后是一个3072维的向量。这比Transformer内部的隐藏层维度(通常为768或1024)还要大得多。
按照传统观点,将如此高维的向量直接输入到维度较小的网络中,会造成严重的信息瓶颈。
但基于前文的流形假设,既然我们预测的是低维流形上的洁净图像,这种维度的压缩不仅不是问题,反而可能是一种优势。
图像被切分并展平后,经过一个简单的线性投影层进入Transformer主干。
主干由堆叠的Transformer块组成,使用标准的注意力机制。
时间步(Time)和类别(Class)信息通过adaLN-Zero层注入到网络中,这是目前扩散模型的标准操作。
最后,一个线性层将处理后的Token直接投影回像素空间,输出预测的洁净图像图块。
整个过程没有任何黑盒操作。从输入到输出,每一个环节都是透明可控的线性变换或注意力计算。
研究团队在ImageNet数据集上对JiT进行了严格测试。结果表明,在预测洁净图像(x-prediction)的设定下,JiT展现出了惊人的鲁棒性。

在256x256分辨率下,使用16 x 16图块(维度768),JiT-B模型取得了约8.6的FID分数。作为对比,如果在同样的设置下强行使用噪声预测或速度预测,FID分数会飙升到300以上,生成的图像完全是一团噪点。
这再次印证了在高维像素空间,预测目标的选择决定了模型的生死。
更进一步,研究者做了一个反直觉的瓶颈测试。他们在Patch嵌入层引入了一个线性瓶颈结构,先将高维的图块(768维)强行压缩到一个极低的维度(如16维或32维),然后再映射回网络内部。
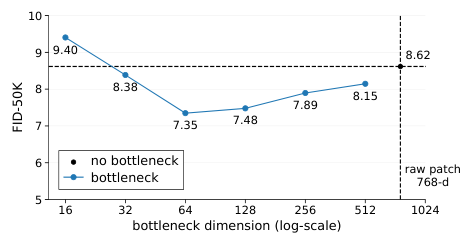
常理告诉我们,将768维的信息压缩到16维,必然会导致大量信息丢失。但在JiT的实验中(如上图所示),引入这个极窄的瓶颈并没有摧毁模型。
这个现象物理意义极强:它说明图像中真正有价值的信息确实是低维的。
网络不需要保留所有像素的细节,只需要抓住那几个关键的流形特征。瓶颈层充当了一个天然的过滤器,滤去了高频噪声,强迫模型专注于流形的重建。
这一发现彻底解放了模型设计的思路。
既然不需要匹配输入维度,我们就可以在极高分辨率的图像上,使用非常大的图块,配合相对轻量级的计算网络,实现高效的生成。
线性扩展能力打破计算成本壁垒
在像素空间进行图像生成,长久以来面临的最大障碍是计算成本。
传统的卷积神经网络(如U-Net)在处理高分辨率图像时,计算量随着像素数量的增加呈二次方甚至更高增长。
这也是为什么目前主流的高分辨率生成模型(如Stable Diffusion)都选择在压缩后的潜在空间(Latent Space)工作。
JiT架构通过解耦设计,巧妙地绕过了这一壁垒,展现出了优越的线性扩展能力。
研究团队展示了JiT在不同分辨率下的扩展策略。当图像分辨率从256x256提升到512x512时,图像的总像素数增加了4倍。按照传统逻辑,计算量也应该暴涨。
但JiT采取了不同的策略:保持序列长度(Sequence Length)不变,按比例增大图块尺寸(Patch Size)。
由于Transformer的计算复杂度主要取决于Token的数量(即序列长度),因此,512分辨率模型的计算量(FLOPs)与256分辨率模型几乎持平。
这种策略的唯一代价是每个Token的维度变大了(从768增加到3072)。但如前所述,JiT通过直接预测洁净图像,完美消化了这种高维输入。
实验数据有力地支持了这一策略。研究者训练了从Base (B)、Large (L)、Huge (H) 到 Giga (G) 四种不同规模的模型。

在ImageNet 512x512分辨率上,JiT-G/32模型达到了1.78的FID分数。这一成绩极具竞争力。更重要的是,JiT-G在512分辨率下的计算成本,与其在256分辨率下的成本处于同一数量级。这打破了分辨率提升必然导致算力爆炸的魔咒。

研究甚至挑战了1024x1024的超高分辨率。在这种设置下,图块尺寸达到了惊人的64 x 64,每个Token的维度高达12288。即便面对如此夸张的维度,JiT依然能够稳定训练,并生成高质量的图像(FID 4.82)。
除了分辨率的扩展,JiT还展现出了跨分辨率的通用性。
由于模型结构在不同分辨率下保持一致(Token数量相同),一个在512分辨率上训练的模型,可以直接用来生成256分辨率的图像,甚至表现比专门训练的256模型还要好。
这意味着模型真正学到了图像的内在结构,而非死记硬背像素排列。
在与现有的顶尖模型对比中,JiT的表现令人印象深刻。
在潜在空间扩散模型(Latent-space Diffusion)阵营,以DiT为代表,它们依赖复杂的预训练VAE和感知损失。
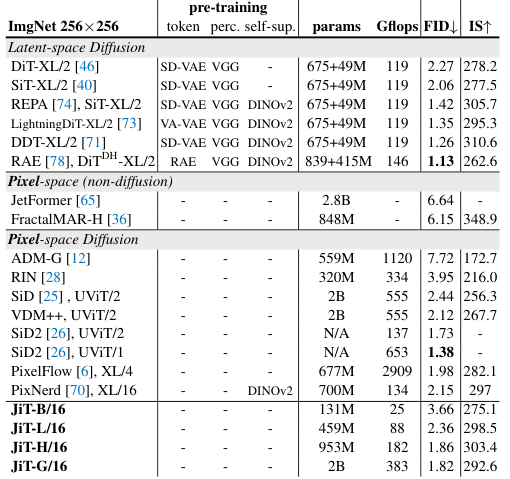
JiT完全抛弃了这些拐杖,实现了自包含(Self-contained)的生成,FID分数却能与DiT-XL(2.27)等模型分庭抗礼,甚至在JiT-G版本上实现了超越(1.82)。
在像素空间扩散模型(Pixel-space Diffusion)阵营,传统的ADM模型虽然效果不错,但参数量巨大且计算效率低下。JiT通过大图块和Transformer架构,在保持高性能的同时,大幅降低了计算复杂度。
为了将性能推向极致,研究团队在JiT的基础上引入了一些通用的Transformer改进技术,如SwiGLU激活函数、RMSNorm归一化、旋转位置编码(RoPE)等。
他们还借鉴了大语言模型的思路,通过在输入序列中直接拼接多个类Token(Class Token)来实现条件控制,这种上下文类条件(In-context Class Conditioning)进一步提升了生成质量。
这些改进虽然引入了少量技术细节,但依然保持了架构的通用性和简洁性。
这一系列实验,验证了一种全新的生成范式:去噪生成模型不需要复杂的包装,不需要依赖其他模型的辅助,它完全可以独立、高效地在最原始的数据形态上工作。
回归本源开启科学探索新篇章
何恺明团队的这项研究,其意义远不止于在ImageNet上跑出了几个漂亮的FID分数。它标志着计算机视觉领域对扩散模型理解的一次深刻修正,一种从工程堆叠向第一性原理的回归。
长期以来,扩散模型的研究被锁死在潜在空间的舒适区。
研究者习惯了先用VAE把图像压缩,再在小小的潜在空间里做文章。
这种做法虽然工程上有效,但却引入了强烈的归纳偏置(Inductive Bias)。
VAE的结构、预训练的数据、感知的损失函数,都在潜移默化地影响着生成的图像。
JiT的出现,证明了这种依赖是可以被打破的。
通过正确地定义预测目标——预测洁净数据而非噪声,神经网络完全有能力直接处理高维的原始数据。
这种自包含的特性,对于科学领域的应用具有无法估量的价值。
在许多科学领域,如气象预测、蛋白质结构生成、天文观测数据处理,数据往往是极高维的,而且并没有现成的、针对特定领域的分词器或VAE可用。
设计一个高质量的Tokenizer本身就是一项极其困难的任务。
JiT提供了一条通用的路径。
由于它不依赖任何特定领域的预训练组件,只需要原始数据即可训练,因此它可以被无缝迁移到任何需要生成建模的领域。
无论是预测台风的云图,还是生成新的药物分子结构,只要数据满足流形假设,JiT就能发挥作用。
此外,JiT的极简设计也为未来的硬件优化铺平了道路。
没有了复杂的上采样、下采样和特殊的卷积操作,纯Transformer架构极其适合在现代GPU和专用AI芯片上并行加速。
其线性的计算扩展能力,使得处理更高分辨率(如4K、8K)视频生成成为可能。
在AI模型变得越来越臃肿、越来越像黑盒的今天,何恺明团队提醒我们:有时候,阻碍我们前进的,正是我们为了解决问题而引入的那些复杂工具。
噪声是高维的混乱,数据是低维的秩序。大道至简,去噪即是求真。
参考资料:
https://arxiv.org/abs/2511.13720
https://people.csail.mit.edu/kaiming/
https://github.com/LTH14/JiT
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









