



让多模态AI学会思考,反而会把图画错了,这个反直觉的现象揭示了当前思考生成模型的缺陷。
北京大学,字节跳动,普林斯顿大学,中国科学院自动化研究所,芝加哥大学提出了让图像并行生成的新范式。


在人工智能的进化图谱中,让模型在行动前先思考,曾被视为通向更高智能的必经之路。
大语言模型中的思维链(CoT)技术已经无数次证明:通过拆解步骤、显式推理,模型处理复杂任务的能力会呈指数级上升。
这一逻辑很自然地被迁移到了多模态领域——在生成或编辑图像之前,让模型先生成一段文本推理,规划好要画什么、怎么改,理论上应该能得到更精准的结果。
然而,该研究发现了一个令人不安的事实:在涉及世界知识推理的复杂指令下,这种先思考、后作画的模式,反而降低了生成图像的语义保真度。
问题出在顺序二字上。
目前主流的多模态模型,大多采用自回归(Autoregressive, AR)架构。这种架构就像一条单向流动的流水线:先由文本模块吐出推理文字,再将这些文字作为上游原料投喂给图像生成模块。
这种机制隐含着一个巨大的风险——误差传播。
一旦上游的推理文本出现哪怕一丝微小的偏差,比如对背景纹理的描述过于冗长,或者对主体特征的定义稍显模糊,下游的图像生成模块就会拿着错误的图纸全力施工。
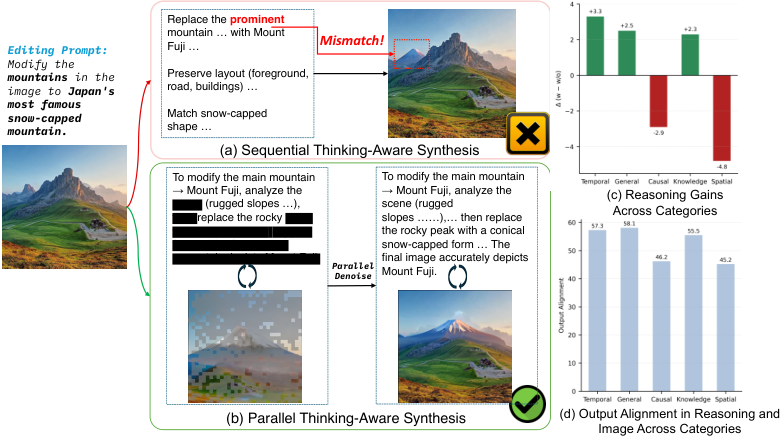
看上图中的案例,用户要求将山替换为富士山。现有的SOTA模型Bagel虽然开启了思考模式,但它的推理过程跑偏了,花费大量笔墨去描述背景的碎石纹理。
结果,图像生成模块忠实地执行了这一跑偏的指令,最终生成的图像里根本没有富士山,只有一堆乱石。
原本用来辅助生成的思考,变成了干扰生成的噪声。
这一发现动摇了当前多模态研究的一块基石。
为了系统性地解决这个问题,研究团队并没有在旧有的自回归路线上修修补补,而是推倒重来,提出了一种全新的并行多模态扩散框架——MMaDA-Parallel。
它不再让文本和图像排队通过,而是让它们在同一个时间维度上并行生长,通过双向注意力机制实时互校。
这是一种生成哲学的转变:真正的多模态协同,不是接力跑,而是双人舞。
诊断新标尺:ParaBench基准的构建逻辑
在解决问题之前,必须先精准地量化问题。
现有的多模态基准测试存在一个盲区:它们通常只看结果,不看过程。
评测标准往往是将最终生成的图像与初始的提示词进行比对。这种端到端的评估方式,完全忽略了中间那个至关重要的变量——推理文本。
如果推理文本本身就是错的,那么图像生成得再精美也是徒劳;如果推理文本是对的,但图像没跟上,那是生成模块的锅。混在一起看,永远找不到病根。
为了剥离出真相,研究团队构建了ParaBench。
这是一个专门为评估思维感知(Thinking-Aware)生成而设计的诊断级基准。
ParaBench并未追求海量的数据规模,而是追求极致的难度与精度。它包含300个精心设计的提示词,分为两大阵营:
-
200个编辑任务:涵盖增加、移除、替换等操作,但不仅限于此,更包含了需要深层逻辑推理的复杂编辑。
-
100个生成任务:专注于开放式、创造性的复杂场景合成。
这个基准引入了一个被称为AI法官的评估机制,利用GPT-4.1从六个细粒度维度进行裁决:
-
文本维度:文本质量、文本对齐。
-
图像维度:图像一致性、图像对齐、图像质量。
-
核心维度:输出对齐(Output Alignment)。
输出对齐是ParaBench的灵魂。
它不看别的,专门盯着模型生成的推理文本和最终图像看。它要回答的问题是:你画出来的东西,和你嘴里说的逻辑,是一回事吗?
利用ParaBench对当前最先进的开源模型Bagel进行体检,结果验证了研究团队的猜想。

这说明,性能的退化不是图像生成能力的缺失,而是图文协同的断裂。
在顺序生成的旧范式下,模糊或错误的推理就像是给瞎子指路,直接导致了后续生成的灾难。
并行扩散:重构时空交互的底层架构
既然顺序排队是万恶之源,那就让它们并排走。
MMaDA-Parallel的核心,是基于离散扩散(Discrete Diffusion)的并行架构。
想象一下拼图。
传统的自回归模型拼图,是先写好一张说明书(文本),然后按照说明书从左上角开始,一块一块地拼出画面(图像)。
MMaDA-Parallel的拼图方式是:说明书和画面同时出现在桌面上,一开始都是模糊的碎片。在拼凑的过程中,文字碎片会参考图像碎片的形状,图像碎片也会参考文字碎片的含义。
每一秒钟,文字和图像都在互相确认、互相调整。
为了实现这种全双工的交互,MMaDA-Parallel在底层数据表示上做了一个大胆的统一。
它将文本和图像全部Token化。
文本使用了LLaDA分词器,图像使用了MAGVIT-v2量化器。
在模型眼中,无论是描述颜色的单词Red,还是代表红色的像素块,本质上都是离散的数字Token。
这些Token被扔进同一个序列中,形成了一个交错的队列。
为了区分身份,模型引入了特殊的标记符:<|task|>定义任务,<|soi|>和<|eoi|>标定图像边界,<|thinkgen|>和<|thinkedit|>则明确告诉模型,现在是生成模式还是编辑模式。
这种统一表示带来了一个巨大的优势:双向注意力(Bidirectional Attention)。
在传统的Transformer架构中,注意力掩码通常是下三角矩阵,意味着现在的Token只能看之前的Token。
而在MMaDA-Parallel中,注意力是全向的。
在去噪的任何一个时间步,文本Token可以看见所有的图像Token,图像Token也可以看见所有的文本Token。
这彻底消除了顺序生成带来的暴露偏差(Exposure Bias)。
图像不再被动地等待文本指令,文本也不再需要凭空臆造画面细节。两者在生成过程中互为锚点,共同演进。
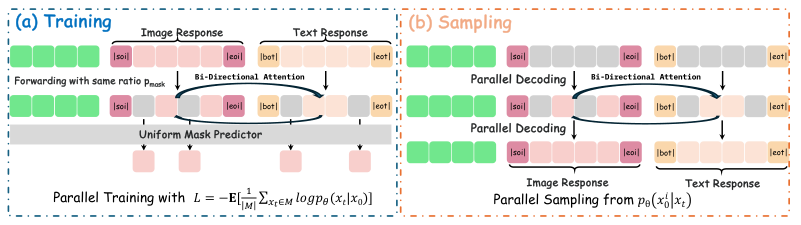
为了训练这个庞大的并行网络,研究团队设计了一套精密的训练目标。
这是一个联合掩码Token预测器。
在训练时,输入部分保持静止,只有输出部分(包括推理文本和目标图像)会被随机掩盖(Mask)。模型的任务是根据上下文,预测出那些被盖住的Token原本是什么。
这里有一个极具工程智慧的细节:时间步相关的损失权重。
文本和图像的学习难度是不一样的。为了平衡两者的动态,研究团队给它们分配了不同的权重函数。图像Token的权重恒定为1,而文本Token的权重被设定为1/t。
这意味着在去噪初期(t较大时),文本的权重较小;随着去噪接近尾声(t变小时),文本的权重逐渐增加。
这种动态调整极大地稳定了训练过程,避免了某一模态主导梯度,确保了模型能同时学会说话和画画。
双调度器,在轨迹中寻找语义共鸣
虽然在架构上实现了并行,但文本和图像毕竟是两种属性截然不同的数据。
文本是高度语义化的,一个词错了,整句话的意思可能就变了;图像是高度冗余的,几个像素错了,肉眼可能根本看不出来。强行让它们用完全相同的节奏去噪,并不是最优解。
MMaDA-Parallel为此引入了双调度器(Dual Schedulers)机制。
在解码过程中,模型沿着一条共享的时间轴前进,但在每个时间点,文本和图像的揭示速度是不同的。
-
文本调度器:采用全线性揭示策略,结合半自回归的置信度解码。这符合文本生成的逻辑性,需要一定的顺序感来保证语法的连贯。
-
图像调度器:采用余弦揭示策略,结合全局置信度解码。这符合图像生成的整体性,往往是先确立大轮廓,再填充细节。
尽管节奏不同,但在每一步反向去噪时,模型都会联合预测所有当前被掩盖位置的分布。即便文本只揭示了30%,图像揭示了50%,已揭示的部分依然可以通过全向注意力机制,为对方未揭示的部分提供线索。
这种设计巧妙地保留了各模态的生成特性,同时在全局层面实现了信息的实时互通。
仅有并行的架构和监督微调(SFT),还不足以达到完美的跨模态对齐。
传统的强化学习(RL)优化通常只看结果。
模型生成完一张图,评判给个分,告诉模型好或不好。这种输出级(Output-level)的反馈太粗糙了。它就像是一个老师,只在期末考试给学生打个分,平时完全不管学生的解题步骤。
对于并行生成而言,真正的魔鬼隐藏在过程之中。
研究团队在分析微调后的模型时,发现了一个迷人的现象:语义同步(Semantic Synergy)。
当模型被要求将一件衬衫改成彩虹色时,在去噪的中间某个步骤,文本中出现红、黄、蓝这些单词的瞬间,图像中对应区域的像素块也开始呈现出色彩倾向。
这说明,跨模态的对齐不是在最后才发生的,而是在生成的轨迹(Trajectory)中逐步建立的。
基于这一洞察,并行强化学习(ParaRL)应运而生。
ParaRL不做期末考试,它做随堂测验。它不再仅仅奖励最终的成品,而是将奖励信号渗透到了去噪的每一个步骤中。
这是一个巨大的计算挑战。如果对每一步都计算奖励,计算量将是天文数字。ParaRL采用了一种稀疏优化策略。在每次训练迭代中,它随机抽取几个关键的时间步(例如s=3),只计算这些时刻的对齐度。
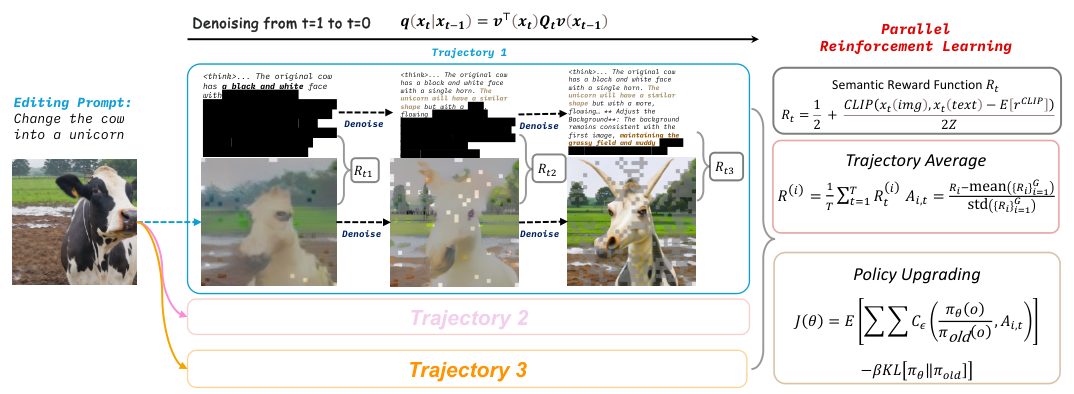
但问题来了:中间步骤生成的往往是半成品,不仅图像模糊,文本也是残缺的。如何评价半成品的质量?
研究团队发现,即使是部分解码的Token,也蕴含了足够的语义信息。通过计算这些中间态文本与中间态图像的语义对齐度(Semantic Alignment),可以直接作为奖励信号。
为了让这个信号稳定可用,研究者没有直接使用原始的CLIP分数(因为方差大且数值不稳定),而是设计了一套基于统计的归一化方案。
他们先统计训练数据中CLIP分数的均值和方差,然后将实时计算的分数进行标准化(Standardization),并截断映射到[0, 1]区间。
这样一来,模型在生成的每一步都能收到清晰的反馈。
这种密集且即时的奖励机制,比传统的稀疏奖励强大得多。它迫使模型在整个生成轨迹中始终保持图文一致,彻底根除了说到做不到的顽疾。
15万条数据,刷新SOTA
没有高质量的数据,再好的算法也跑不起来。
现有的公开数据集,要么只有图文对,要么只有简单的指令,缺乏MMaDA-Parallel所需的推理痕迹(Reasoning Trace)。
为了解决这个问题,研究团队构建了一个包含15万(150K)条数据的高质量训练集。
数据构建的过程本身就是一个工程样板。他们首先从现有的多个图像编辑和生成基准中汇集原始数据(输入图像、指令、输出图像)。然后,利用多模态大模型Qwen-2.5-VL作为老师,逆向生成对应的推理过程。
但这还不够。生成的推理可能质量参差不齐。团队实施了严格的过滤机制,剔除那些推理逻辑不通或与图像不符的样本。最终形成的四元组数据Let <输入图像, 指令, 推理痕迹, 输出图像>,成为了训练MMaDA-Parallel的燃料。
在ParaBench基准测试中,MMaDA-Parallel击败同是思考模型的Bagel。
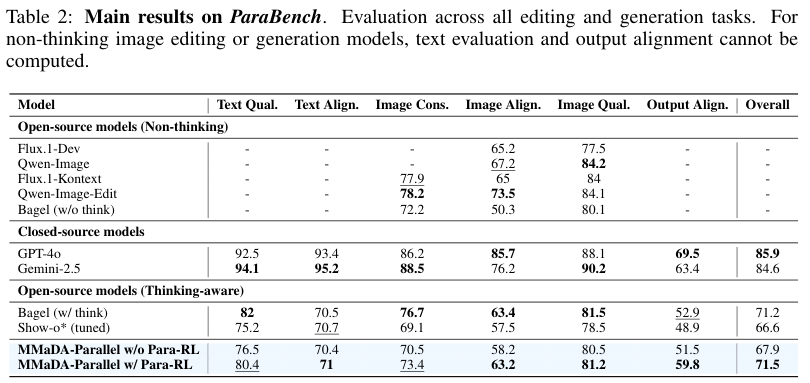
最关键的指标输出对齐(Output Alignment),在经过ParaRL优化后达到了59.8分,相比之前的SOTA模型Bagel(52.9分),提升幅度高达6.9%。
更令人印象深刻的是,MMaDA-Parallel是在相对较小的数据规模上达成这一成就的。Bagel的训练数据量比它大三个数量级。这证明了并行架构和轨迹级优化在数据效率上的碾压性优势。
定性对比则更加直观。

看上图中的融化蛋糕案例。
指令要求展示蛋糕在烈日下融化。
Bagel模型的推理虽然提到了光影,但生成的图像仅仅是让蛋糕表面变亮了一点,看起来像个塑料模型,完全没有物理形态的改变。因为它无法理解融化这个物理过程在视觉上意味着形状的坍塌。
而MMaDA-Parallel生成的图像,蛋糕边缘呈现出真实的流淌感,巧克力酱顺着盘子滑落,光泽感不仅体现了亮度,更体现了液化的质感。
这是因为MMaDA-Parallel的推理文本中,精确地描述了失去结构、边缘软化等物理细节,并且这些描述在并行生成的过程中,实时地指导了像素的排列。
再比如枯萎的植物案例。
Bagel生成的植物只是颜色稍微黄了一点,叶子依然挺拔。
MMaDA-Parallel生成的植物,叶片卷曲、下垂,茎部弯折,完美地在视觉上翻译了缺水这一生物学状态。
在更考验逻辑的计数任务中,Bagel经常数不清三个人或两个钟面,而MMaDA-Parallel凭借精准的并行对齐,能够准确地生成指定数量的物体。
这直接得益于其在生成过程中,文本计数与图像实体生成的实时校验。
MMaDA-Parallel让思考与行动不分离。通过摒弃自回归的顺序枷锁,拥抱并行的扩散架构,并利用ParaRL在生成的每一毫秒中注入语义对齐的奖励,让AI告别了想得越多错得越多。
参考资料:
https://tyfeld.github.io/mmadaparellel.github.io/
https://huggingface.co/tyfeld/models
https://github.com/tyfeld/MMaDA-Parallel

















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









