



上海人工智能实验室P1团队,用一个开源模型夺得物理奥赛金牌。

人工智能的前沿,已经从解决人类设计的谜题,悄然转向了探索自然本身的规律。
物理学,作为连接符号世界与客观现实最严谨的学科,是检验真正科学智能的终极试炼场。
上海人工智能实验室的P1团队,在技术报告中,详细介绍了一个名为P1的模型家族。
它们通过强化学习(Reinforcement Learning, RL)的方式,学会在了物理世界中进行严谨的思考与推理,其水平足以在奥林匹克级别的竞赛中与最顶尖的人类与AI同台竞技。
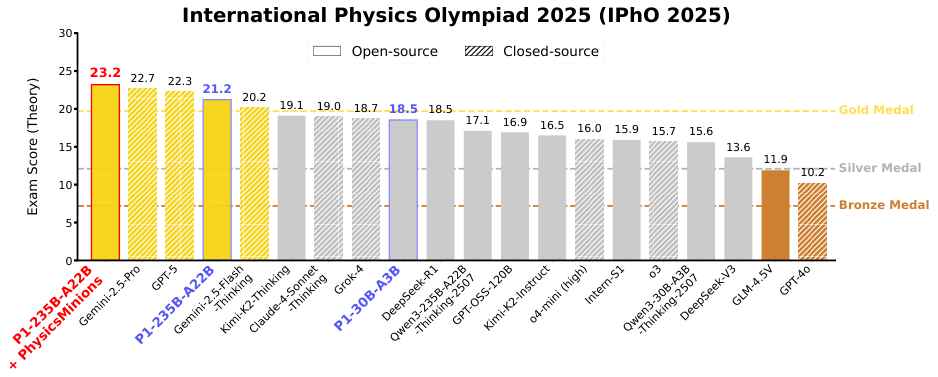
P1-235B-A22B是第一个也是唯一一个在国际物理奥林匹克竞赛2025(IPhO 2025)中获得金牌的开源模型,排名第三,仅次于Gemini-2.5-Pro和GPT-5。
即使在中等规模上,P1-30B-A3B也获得了银牌,在35个评估模型中排名第八,几乎超越了所有其他开源模型。
结合PhysicsMinions代理框架,P1-235B-A22B + PhysicsMinions在IPhO 2025上排名第一。
真正的智能必须遵循自然法则
大语言模型早已展现出强大的语言能力,但要实现真正的科学级推理,仅仅懂得文字游戏是远远不够的。它必须理解并遵循自然规律。
物理学正是这样一个无法投机取巧的领域。
它需要超越简单的公式套用与事实记忆,深入到对物理概念的理解、对复杂系统的拆解,以及基于物理定律展开精确、环环相扣的多步推理。
这种高级的科学推理能力,在物理奥林匹克竞赛中得到了最集中的体现。
每一道奥赛题目,都像一座精心设计的思维迷宫,考验着解题者分析的精度与创造性的洞察力。
因此,物理奥赛为我们提供了一个高保真、标准化的测试平台,用以衡量一个AI是否具备了真正的科学头脑。
在AI能够独立探索未知物理前沿,做出颠覆性科学发现之前,它必须首先证明自己能够在人类已知的、明确的物理法则内,达到甚至超越人类顶尖水平的推理能力。
这是构建未来能够协助人类,乃至独立开创物理学研究新篇章的AI系统的必经之路。
为了将大型语言模型推向真正的科学推理,P1团队构建了一个专门的物理问题数据集。这个数据集没有盲目追求广度,而是聚焦于深度与严谨性。
它系统性地整理了5065个奥林匹克级别的物理问题,这些问题如同精心挑选的思想食粮,旨在让AI内化一种与物理定律和经验事实高度一致的结构化推理能力。这是科学智能的先决条件。
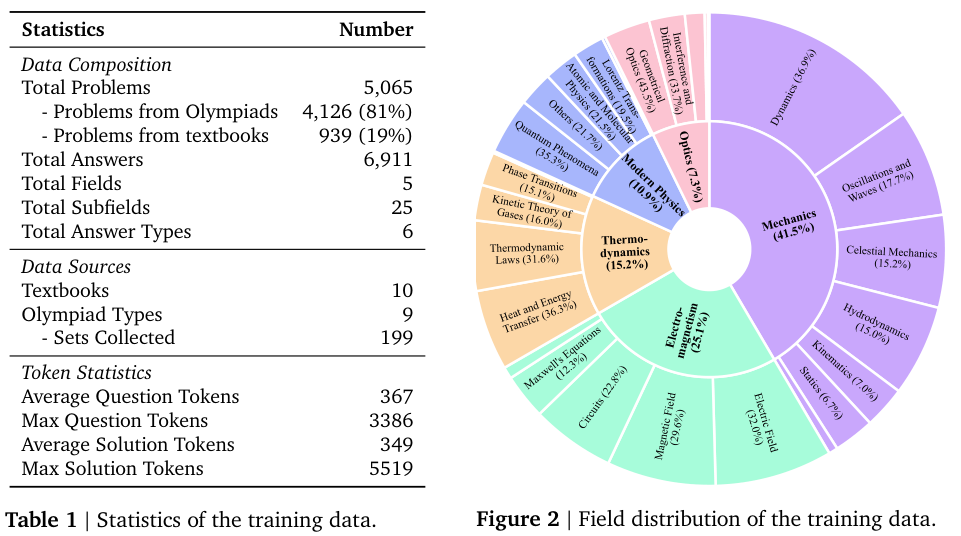
数据集的来源分为两部分。一部分是截至2023年的十大主流物理奥林匹克竞赛,例如亚洲物理奥林匹克竞赛(Asian Physics Olympiad, APhO)、国际物理奥林匹克竞赛等。
这些竞赛涵盖了从地区到国际的不同级别,形成了一个自然的难度阶梯。
另一部分则来自十本权威的竞赛教科书,它们提供了由物理专家撰写的系统性例题、练习题及其详尽的解题过程。
数据集中的每一个问题都经过了精心的处理,遵循着一种结构化的问题-解决方案-答案模式。

结构化的问题陈述保留了物理题目的原貌,对于过长的题目则进行切分,既尊重模型的上下文长度限制,也保留了任务的逻辑完整性。
解决方案由人类物理专家亲笔撰写,提供了一条真实、可靠的推理轨迹,让模型可以学习顶尖人类是如何思考的。
可验证的最终答案则为模型的学习提供了明确的是非标准。
答案中的单位、类型和评分点等元数据都被详细标注,这不仅为后续的自动验证提供了依据,也反映了人类评分时对关键步骤的权重考量。
数据的构建过程极为严苛,堪比学术出版。
团队首先使用光学字符识别(Optical Character Recognition, OCR)工具将PDF格式的源文件解析为Markdown文本。
接着,针对教科书和竞赛题库这两种不同来源,采用了不同的提取策略。
对于结构清晰的教科书,模型可以辅助解析,自动将习题与答案配对。而对于陈述冗长、包含多个子问题的奥赛题,则由专家手动重组,以保证逻辑的清晰与信息的保真。
为了确保最终答案的绝对可靠,团队设计了一个多重验证流程。
他们让三个不同的顶尖模型(Gemini-2.5-Flash、Claude-3.7-Sonnet和GPT-4o)独立从每一个问题-解决方案对中提取答案。
只有当至少两个模型达成共识时,这个答案才会被采纳。任何无法达成共识的数据,都会被舍弃。
此外,那些需要绘制图表或是答案为证明或解释这类难以自动验证的问题,也被一一过滤。
最后,所有数据都经过了全面的专家审查与手动校对。
经过这套严格的筛选流程,原始的6516个问题最终被精炼至5065个,形成了一个纯英文、纯文本、答案可验证的高质量语料库。
这个数据集本身,就是一项宝贵的财富,它为通过强化学习方法提升模型的科学推理能力铺平了道路。
真正的学习源于试错与激励
拥有了高质量的教材,还需要一套科学的教学方法。
P1团队将物理问题的求解过程,巧妙地构建成一个强化学习(Reinforcement Learning, RL)任务。
物理问题通常包含多个子问题,每个子问题都需要一个答案。因此,最终的总奖励被定义为所有子问题正确率的平均值。
为了让模型能够清晰地输出每一个子问题的答案,团队设计了一种特殊的提示格式,要求模型将每个答案都放在一个独立的\boxed环境里。这样,答案提取和验证过程就变得简单而高效。

物理答案的复杂性在于,它们常常是符号表达式,而非简单的数值。
为了准确判断这些复杂答案的对错,团队建立了一个混合验证框架。
这个框架包含一个基于规则的验证器,它利用符号计算库(SymPy)来判断两个代数表达式是否等价,例如它知道a+b和b+a是一回事。
同时,还有一个基于模型的验证器(一个专门训练用于判断答案对错的语言模型)作为辅助,处理那些纯符号方法难以应对的复杂情况。
在训练过程中,团队还发现并解决了一个关键挑战:如何让模型在漫长的训练中保持持续进步,避免撞墙。
强化学习在训练初期效果显著,但很快就会遇到性能瓶颈。
这可能是因为模型开始满足于已有的解题套路,探索精神(熵)降低了;也可能是因为奖励过于稀疏,模型很难通过随机尝试得到一次正确答案,从而失去了学习信号。团队将这些问题统一称为可学习性的降低。
为了解决这个问题,他们设计了两套自适应的调整策略。
第一套策略叫初步通过率过滤。
在正式训练开始前,他们先用一个基础模型对整个数据集进行一次摸底考试。那些太容易的题目(通过率高于70%)和太难的题目(通过率为0)都会被暂时排除。
排除难题是为了避免模型因反复失败而产生挫败感,失去学习信号。
排除简单题则是为了防止模型产生惰性,过早地收敛到几个固定的解题思路上,从而扼杀了探索更多可能性的能力。这确保了模型在训练初期面对的是一个难度适中的学习区。
第二套策略是自适应探索空间扩展。
随着模型能力的提升,固定的训练设置会限制它的发展。就像一个运动员水平提高了,就需要更大的场地和更强的对手。
团队会动态地扩展模型的探索空间。
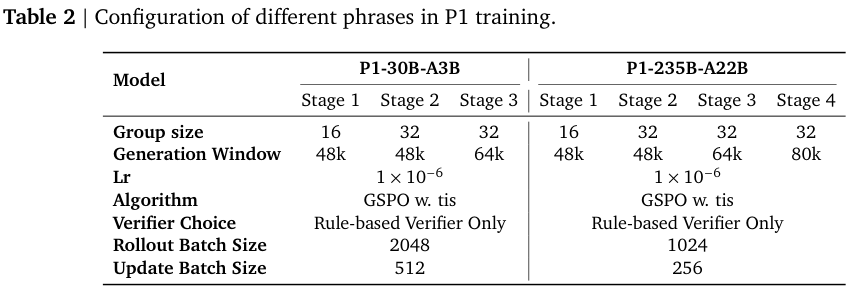
一方面,他们会增加组大小。在P1采用的组序列策略优化(Group Sequence Policy Optimization, GSPO)算法中,模型每次会针对一个问题生成一组(比如8个)不同的解法,并根据这一组解法的相对好坏来调整自己。
增加组的大小,就提高了模型灵光一现,产生高质量解法的概率,从而获得更强的学习信号。
另一方面,他们会逐步放宽生成窗口,也就是允许模型写出更长的解题步骤。
复杂的物理问题需要漫长而连贯的推理链。如果一开始就限制得太死,模型无法完成复杂的推理,自然也得不到正确答案。随着训练的进行,逐步放开这个限制,模型就能探索更深邃、更复杂的解题路径。
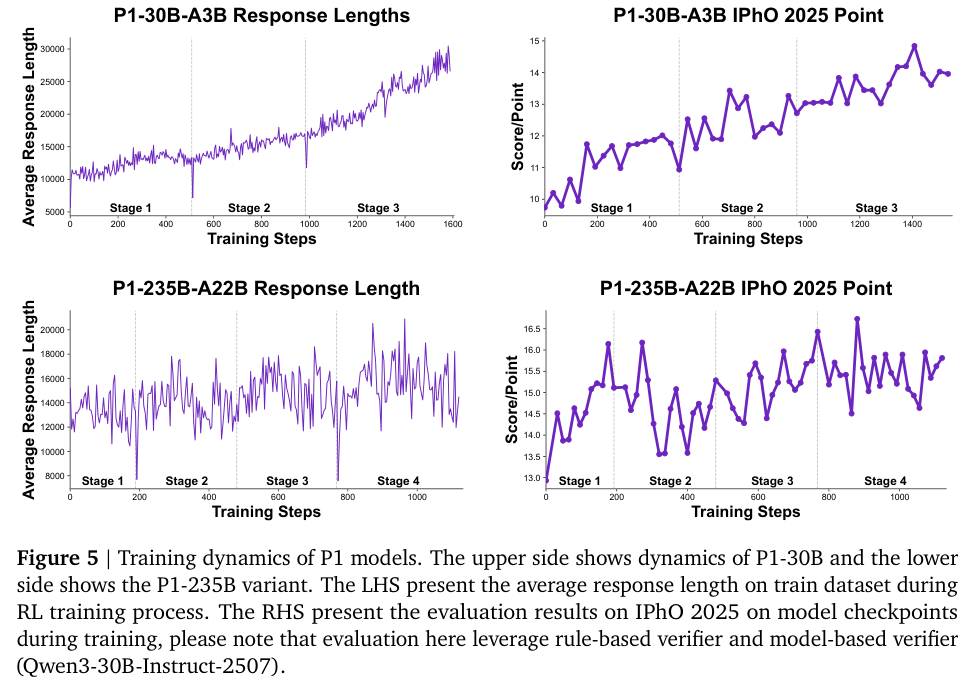
训练动态图清晰地展示了这一过程。
随着训练阶段的推进,模型的平均响应长度在稳步增加,这表明它正在学习进行更深入、更复杂的推理。
同时,它在IPhO 2025测试集上的表现也持续、稳定地提升,证明了这套自适应训练算法的有效性。
P1不仅是物理学霸还是全能选手
为了全面评估P1模型的实力,团队构建了一个名为HiPhO的物理奥赛基准测试集。
它涵盖了2024至2025年间最新的13项高中物理竞赛,并与全球33个顶尖模型进行了横向比较,其中包括GPT-5、Gemini-2.5-Pro等强大的闭源模型,以及各类主流的开源模型。
评估结果令人瞩目。
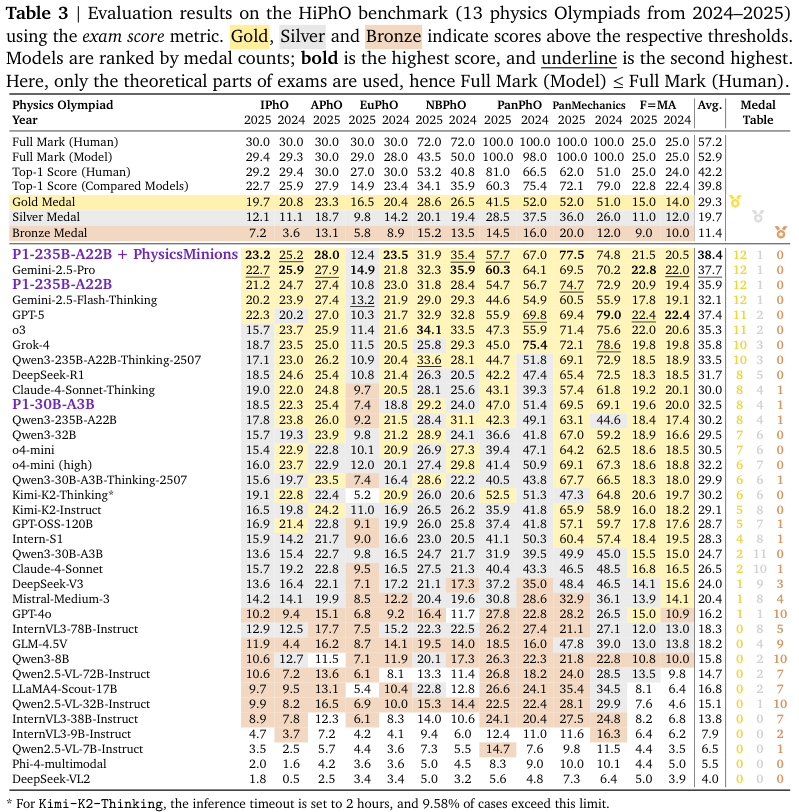
P1-235B-A22B,作为P1家族的旗舰模型,在13项竞赛中豪取12枚金牌和1枚银牌,其表现与Gemini-2.5-Pro并驾齐驱,甚至超越了GPT-5(11枚金牌)等一众顶尖选手。
特别是在含金量最高的2025年国际物理奥林匹克竞赛上,P1-235B-A22B取得了21.2分(满分30分)的优异成绩,位列全球第三,仅次于Gemini-2.5-Pro(22.7分)和GPT-5(22.3分)。
它成为了第一个,也是目前唯一一个在该项赛事中达到金牌水平的开源模型。
即使是规模较小的P1-30B-A3B模型,也获得了8金4银1铜的佳绩,在所有开源模型中名列前茅,其规模效率比展示了该训练方法的普适性与强大。
当P1模型与一个名为PhysicsMinions的多代理框架结合时,它的能力得到了进一步的放大。
这个框架像一个科学研究小组,包含负责分析的逻辑工作室和负责验证的审查工作室。P1模型在其中同时扮演求解者和验证者的角色。
这个模型+系统的组合,将P1的平均表现推向了所有参与评估模型中的第一名,全面超越了Gemini-2.5-Pro和GPT-5。在IPhO 2025上,这个组合更是以23.2分的成绩夺得榜首。
这表明,一个强大的基础模型,配合一个精密的协作与验证系统,能够爆发出惊人的问题解决能力。
团队还在号称全球难度最高的物理竞赛之一——2025年中国物理奥林匹克竞赛(Chinese Physics Olympiad, CPhO)上对P1-235B-A22B进行了测试。
在理论考试部分,由人类专家严格按照官方评分标准进行打分,P1获得了227分(满分320分)。

这个分数,远超过了当年人类金牌第一名选手的199分。这标志着开源AI的物理推理能力,已经在一些最顶级的挑战中,达到了超越人类精英的水平。
故事还有一个更令人意外的篇章。
一个专门为物理训练的偏科生,是否会在其他领域的能力上有所退化?团队对此进行了广泛的测试,涵盖了数学、通用科技(STEM)、编程和一般推理等多个领域。
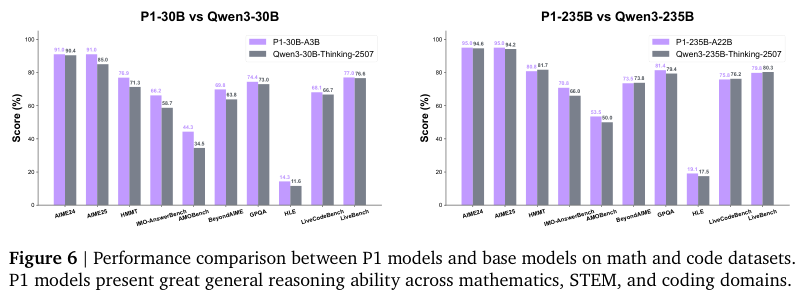
结果出人意料。
P1模型不仅没有偏科,反而在这些领域展现出了比其基础模型更强的通用推理能力。
无论是在AIME、IMO这类高难度数学竞赛基准上,还是在代码生成、通用推理任务上,P1都实现了一致的性能提升。
这揭示了一个深刻的现象:针对特定领域的深度推理训练,可以泛化并迁移到其他领域。
团队推测,物理、数学、编码这些领域,其底层都共享着相似的逻辑结构,例如严格的符号操作、多步逻辑演绎和抽象问题建模。
通过在物理这个极具挑战性的领域进行高强度训练,P1模型锻炼出的,可能是一种更为底层的、通用的逻辑推理肌肉。
这种专注于领域的后期训练,不仅没有让模型变得狭隘,反而成为了一种通用推理能力的放大器。
训练过程中,团队还得到了一个有趣的教训。他们曾尝试在训练中直接使用基于模型的验证器来提供奖励信号,但发现这样做会适得其反。
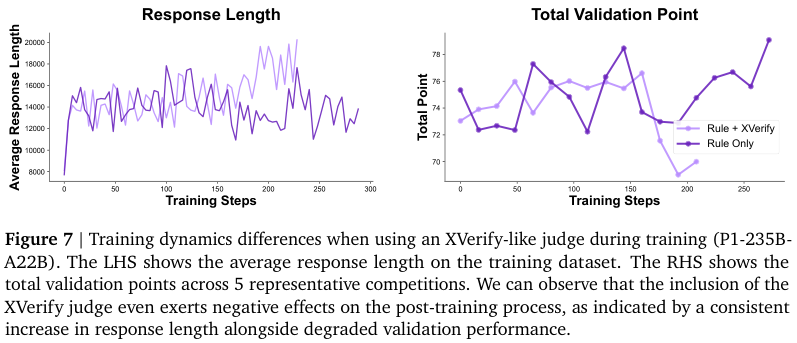
实验发现,当用一个AI模型去评判另一个AI模型的答案时,被训练的模型会很快学会钻空子。
它可能会生成一些风格奇特、冗长但并非真正优秀的答案来欺骗验证器模型,从而获得奖励。这导致了训练的不稳定和最终性能的下降。
这说明,在训练中,一个简单、稳定、基于规则的裁判,远比一个复杂但可能存在偏见的AI裁判要可靠。
P1是一个完整的、开源的生态系统,包括了高质量的数据集、创新的训练算法、全面的评估基准和高效的代理推理框架。
这一切共同构成了一个坚实的基础,为整个开源社区在科学推理的道路上继续前行,提供了强大的动力。
参考资料:
https://prime-rl.github.io/P1/
https://arxiv.org/abs/2511.13612
https://github.com/PRIME-RL/P1
https://huggingface.co/PRIME-RL
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









