



字节发布了InfinityStar框架,将一段5秒720p高清视频的生成时间,从主流扩散模型的30多分钟,压缩到了58秒。并且用一套统一的框架,支持图像生成、文本生成视频、图像生成视频、视频续写等多样化的任务。

视觉生成赛道的核心架构,已经从U-Net系统性地迁移到了Transformer。
2022年,Stable Diffusion以一种全新的范式定义了图像生成,它的1.5版本至今仍在消费市场广泛应用。
2023年,DiT架构诞生,标志着扩散模型正式拥抱Transformer作为骨干网络,这为后来的模型规模化扩展铺平了道路。
接着,2024年OpenAI的Sora系统,首次向世界展示了DiT架构在视频生成领域的Scaling Law(规模法则)效应,通过将视频切成时空补丁(Spacetime Patch)进行处理,实现了分钟级别的长视频生成。
这是扩散模型路线的演进。
另一条路线,自回归模型,也在悄然发展。
2023年的VideoPoet项目,探索了语言模型在视频生成中的应用潜力,但它受限于视频离散化的质量和生成效率。
2024年4月,VAR(视觉自回归建模)提出了一种全新的图像生成视角,称之为下一尺度预测。它不再像传统自回归模型那样一个像素一个像素地预测,而是将预测单位从token级别提升到了特征图(Feature Map)的尺度级别,这极大地提升了生成质量。
同年12月,Infinity模型在VAR的基础上,引入了比特级建模,将模型的词汇表规模扩展到了惊人的2的64次方。这让它在图像生成任务上,达到了与扩散模型旗鼓相当的性能,同时保持了超过8倍的推理速度优势。
两条路线都在高歌猛进,但各自的短板也异常清晰。
基础的扩散模型需要反复执行50到100次去噪步骤,生成一段720p的视频,耗时通常超过30分钟,并且它很难自然地支持视频的续写和外推。
传统的自回归模型,比如Emu3,需要预测数以万计的token,一次生成延迟高达数分钟,视觉保真度也一直落后于扩散模型。
视觉质量、生成效率、任务通用性,三者似乎难以兼得。
InfinityStar打破了这个困境。
它在保证工业级应用所要求的视觉质量的前提下,实现高效的、像水流一样可持续的生成能力。
视频的本质是时空的分离
InfinityStar的架构设计,源于一个对视频数据本质的第一性原理思考。
视频,并不是一个在时间和空间上均匀分布的数据结构。
它实际上是一个复合体,由相对静态的外观信息和持续变化的动态运动信息共同构成。
目前的大多数方法,比如Sora,倾向于将视频视为一个统一的3D数据块进行处理。
这种方式虽然直观,但却让模型难以将这两种正交的特征——外观与运动——进行解耦学习。模型需要在一个统一的网络里,同时理解一只猫的毛发纹理和它奔跑的姿态,这增加了学习的难度。
InfinityStar提出了一种截然不同的思路:时空金字塔模型(Spacetime Pyramid Model)。
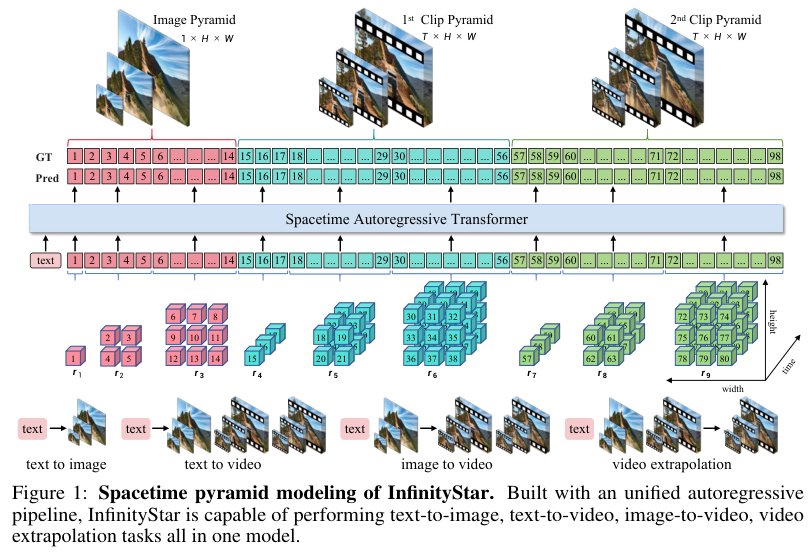
它的核心思想,是显式地将空间尺度的增长与时间维度的扩展分离开来,从而实现一种更符合物理直觉的建模方式。
具体来说,系统会将一段输入的视频,分解成一连串连续的片段。
每个片段的长度是固定的,比如5秒钟,以16fps计算,就是80帧。
第一个片段的首帧,会被单独作为一个特殊的片段c₁来处理。它的时间长度T=1,专门用来编码视频最核心的静态外观线索,比如场景的布局、物体的材质和颜色。
从第二个片段开始,所有后续片段都保持T>1的等长结构,专门用来编码运动信息。
在每个片段的内部,模型采用了一种K个尺度的金字塔结构来表示信息。你可以把它想象成一层层分辨率不断提高的图像,从模糊的轮廓到清晰的细节。
这种设计,巧妙地构建了一个两层自回归结构。
在片段内部,模型按照尺度从小到大,像爬楼梯一样逐级生成,这叫尺度级联。
在片段之间,模型按照时间顺序,一个片段接一个片段地生成,这叫时序级联。
这种时空解耦的设计,使得模型在保持长时序一致性的同时,避免了跨片段的尺度级依赖爆炸。因为在生成新片段时,它不需要回头去关注历史片段的每一个生成细节,只需要一个更高层级的整体信息。
这为长视频的生成,提供了理论上可以无限扩展的能力。
为了验证这种设计的优越性,团队进行了一项对比实验。他们设计了一种伪时空金字塔(Pseudo-Spacetime Pyramid)架构,这种架构像传统方法一样,将时间和空间维度同等处理,在金字塔的每一层同时扩展时空分辨率。

实验结果显示,这种耦合的设计,导致外观和运动信息纠缠不清,在VBench(视频生成综合评估套件)上的总分从81.28分下降到了80.30分,并且生成的视频普遍缺乏细粒度的纹理细节。
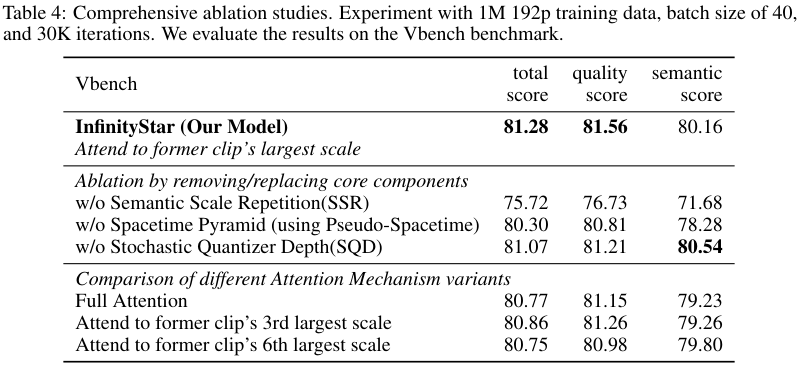
这证明了InfinityStar时空分离设计的正确性。
让视频分词器站在巨人的肩膀上
一个高质量的视觉分词器(Visual Tokenizer),是所有离散自回归模型的基础。它的作用,是将连续的像素信息,转换成像语言一样的离散token,交给Transformer处理。
但训练一个视频分词器的成本,远高于图像分词器。
一帧768×768的图像,转换后的token序列长度大约在1K到4K之间。
而一段5秒钟的720p视频(1280×720分辨率,80帧),在时空压缩率为16×16×4的情况下,会生成大约9.2万个token。
计算量呈现出数量级的增长。
如果采用传统方法,从零开始训练一个离散的视频分词器,需要消耗数万个GPU小时,而且模型收敛非常缓慢。
InfinityStar为此提出了一种极为高效的策略:知识继承(Knowledge Inheritance)。
它的物理本质,是保留并利用一个已经训练好的、强大的连续视频VAE(变分自编码器)所学习到的流形表示能力。
与其让新模型从混沌中学习如何理解视频,不如让它直接继承一位老师傅的毕生功力。
具体实现上,团队选用了业界顶尖的Wan 2.1 VAE作为基础模型。这个模型的编码器,可以在16×16×4的压缩率下,产出64维的连续特征向量。
他们在这个预训练好的VAE的编码器和解码器之间,插入了一个没有可学习参数的量化器。
这个量化器采用二进制球面量化(Binary Spherical Quantization)技术,并且词汇表的大小是根据尺度动态分配的。对于信息量较少的前12个小尺度,使用2的16次方(约6.5万)的词汇表;对于包含大量细节的后14个大尺度,使用2的64次方的超大词汇表。
这种非均匀的分配策略,使得模型的收敛速度提升了30%,并且重建质量没有任何损失。

实验数据有力地证实了这一策略的有效性。
在一个内部的高动态视频基准测试集上(480p分辨率,81帧),通过继承连续VAE权重训练的分词器,其PSNR(峰值信噪比)达到了33.37dB,SSIM(结构相似性)为0.94,LPIPS(学习感知图像块相似度)低至0.065。

相比之下,从零开始训练的分词器,各项指标仅为30.04dB、0.90和0.124,差距巨大。
一个更有说服力的事实是,即使完全不进行微调,仅仅是继承了权重的分词器,就已经能够合理地重建视频,PSNR达到22.6dB,远超过一个预训练的图像VAE所能达到的16.4dB。

训练曲线图显示,继承策略在仅仅1万次迭代步数内,损失函数就迅速达到了平台期,而其他方法则需要至少3万步以上才能达到类似的水平。
这种站在巨人肩膀上的方法,极大地节约了训练成本,并为整个模型的高性能奠定了一个坚实的基础。
除了知识继承,团队还解决了另一个棘手的问题:时空金字塔结构导致的信息分布极端不均衡。
在26个尺度的配置下,前10个尺度包含的总token数不足5000个,而最后5个尺度包含的token数则超过了8万个。
在训练过程中,量化器会很自然地倾向于将更多的信息压缩到数据量更大的后期尺度中,导致早期尺度中的token几乎不包含任何有效信息。
这会让后续的VAR Transformer难以学习和建立跨尺度之间的依赖关系,因为早期尺度的信息是空的。
为了解决这个问题,团队引入了一种名为随机量化器深度(Stochastic Quantizer Depth, SQD)的正则化机制。
它的原理类似于一种蒙特卡洛dropout(随机失活)。
在训练时,最后N个尺度会以一个概率p被随机地丢弃,这样就产生了2的N次方种可能的尺度组合。
这种随机性,迫使模型不能过度依赖后期尺度,强制它将更多的核心语义信息存储到更加保险的早期尺度中。
可视化的实验结果非常直观。

在没有使用SQD的情况下,仅用前6个尺度重建的图像,只能看到一些模糊的色块。
而在启用了SQD之后,同样只用前6个尺度,已经可以恢复出物体的清晰轮廓和场景的整体布局。
让Transformer更懂时空的逻辑
在拥有了一个强大的分词器之后,优化的重心就转移到了核心的自回归Transformer上。
团队在这里也引入了两项关键的优化。
第一个优化,叫做语义尺度重复(Semantic Scale Repetition, SSR)。
在金字塔的众多尺度中,最开始的几个尺度决定了视频的全局信息,包括场景布局、主体位置、相机运动等核心要素。团队将这些尺度称为语义尺度。
InfinityStar对这些语义尺度实施了一种重复预测机制。
这个操作听起来会增加计算量,但实际上,由于早期尺度的token数量占总token数的比例极低(不足3%),因此整个操作带来的额外计算开销还不到5%。
但其带来的性能提升是巨大的。
融实验表明,如果去掉语义尺度重复机制,模型的VBench总分会从81.28分,断崖式暴跌到75.72分。其中,语义一致性这个子项的得分,从80.16分骤降至71.68分。

从定性生成的视频对比中可以发现,没有SSR时,视频中经常出现恼人的结构闪烁和主体变形。
而在启用了SSR之后,即便是像人物翻书、快速切菜这类复杂的、带有精细操作的运动,其动作的连贯性也得到了显著的改善。
第二个优化,是时空稀疏注意力(Spacetime Sparse Attention, SSA),它直击长视频生成的核心痛点:上下文长度爆炸。
在标准的注意力机制下,模型在生成第c个片段的第k个尺度时,需要attend(关注)到所有历史片段的所有尺度信息。
这意味着,上下文序列的长度会随着片段数量N的增加而线性增长,导致显存占用达到O(N²)的级别,很快就会超出硬件的承受极限。
InfinityStar提出的时空稀疏注意力策略,极大地简化了这个过程。
它规定,模型在生成当前尺度时,除了attend同片段内的前序尺度,只需要额外attend前一个片段的最后一个尺度(即信息最完整的那个尺度)即可。
这个简单的改动,将计算复杂度从O(N²)成功降低到了O(N)。
在一个192p分辨率、161帧的生成任务中,SSA实现了1.5倍的加速,同时显存占用从57GB降低到了40GB。
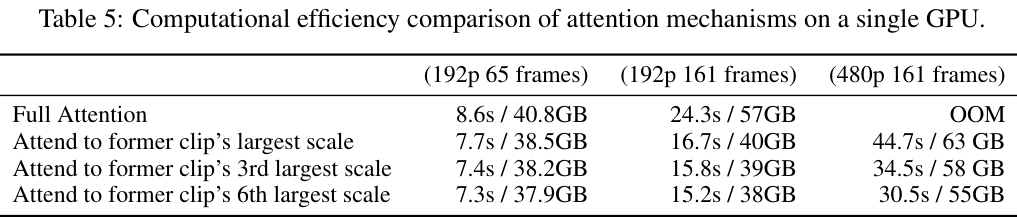
在一个更具挑战性的480p、161帧任务中,全注意力机制因为显存不足(OOM)而直接失败,而SSA在44.7秒内顺利完成,显存占用为63GB。
在性能方面,SSA的VBench总分达到了81.28分,反而超过了计算量更大的全注意力(80.77分)。这被归因于稀疏注意力降低了模型的曝光偏差累积问题,让模型更专注于最相关的时序信息。
性能表现与零样本的惊人泛化
经过一系列的架构创新和技术优化,InfinityStar的最终性能表现如何?
在文本到图像(T2I)生成任务中,InfinityStar-T2I模型在两个权威基准GenEval和DPG上进行了评估。
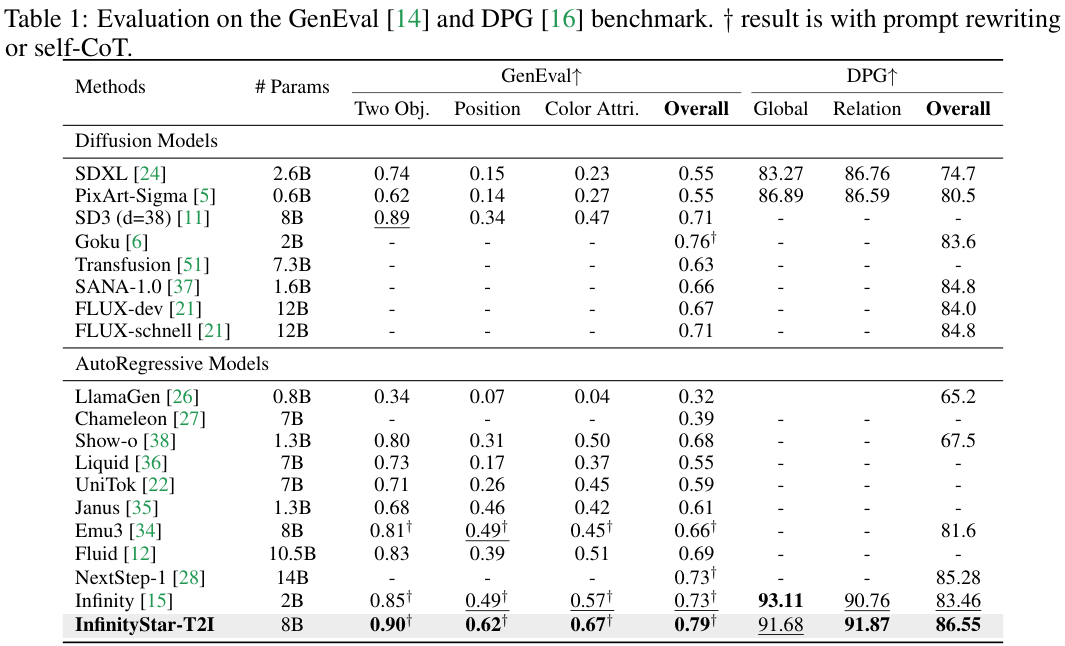
GenEval基准包含了346个复杂的测试用例,重点考察模型对于对象组合、空间关系和属性绑定的理解能力。
InfinityStar以8B参数的规模,取得了0.79的总体分数,超越了14B参数的NextStep-1(0.73分)和12B参数的FLUX-dev(0.67分)。
在DPG基准上,它测试的是模型生成图像与文本提示的语义对齐度,InfinityStar的总分达到了86.55分,比前代Infinity模型提升了3.09个百分点。

在文本到视频(T2V)生成任务中,VBench是行业公认的综合评估套件,它包含16个评估维度,总分由人类动作、场景、多对象、外观质量、语义等多个子项加权得出。
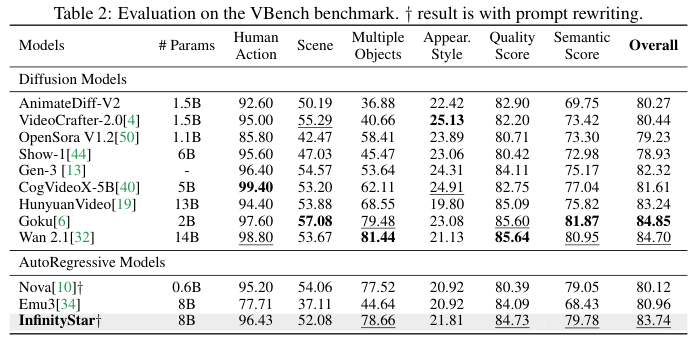
InfinityStar在8B参数下,获得了83.74分。这个分数超越了13B参数的HunyuanVideo(83.24分),并与14B参数的Wan 2.1(84.70分)和2B参数的Goku(84.85分)等顶尖的扩散模型处于同一水平。
值得注意的是,这个分数在所有已知的开源自回归模型中,位列第一,相比于Emu3(80.96分)和Nova(80.12分)等模型,提升显著。
在人工评测环节,50名专业的评估人员对InfinityStar和HunyuanVideo生成的视频进行了双盲对比。
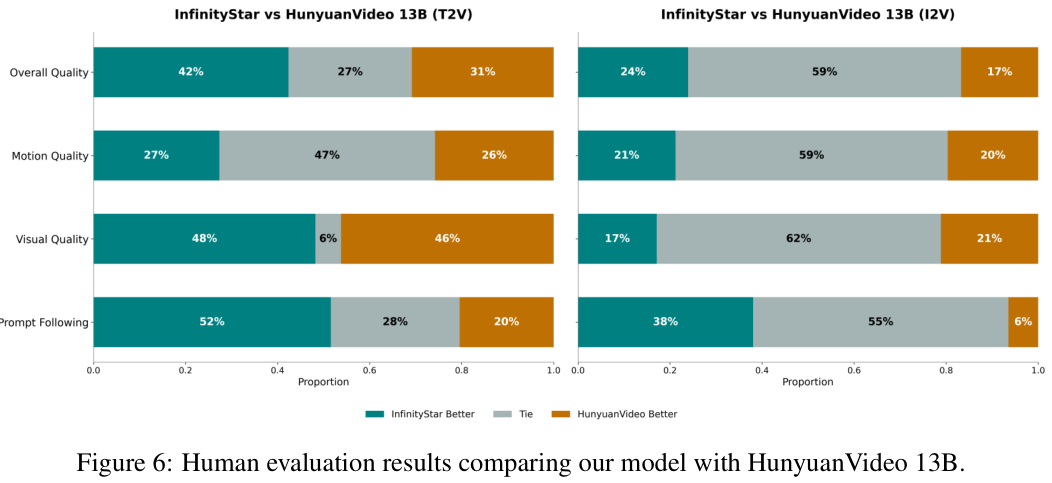
在T2V任务中,InfinityStar在文本遵循度、视觉质量、运动平滑度、时序一致性这四个关键指标上,全面领先,胜率分别达到了68%、72%、65%和71%。
在图像到视频(I2V)任务中,胜率同样全面领先,分别为64%、58%、61%和63%。
这些评测中的视频,时长均为5秒,分辨率为720p。
除了强大的基准性能,InfinityStar还展现出了惊人的零样本(Zero-shot)泛化能力。
尽管模型只在文本到视频的数据上进行了训练,但它能够自然地扩展到视频续写和图像生成视频等任务。

给定一段5秒的参考视频,模型可以流畅地将其续写到20秒。视频中的核心运动模式,比如人物的行走姿态、手势的细微变化,都保持了高度的连贯性,语义漂移被控制在了极低的水平。

在I2V任务中,模型能够同时满足首帧图像信息和文本指令。无论是猫头鹰在空中飞翔,还是滑雪者在雪地转弯,生成的视频都自然且物理合理,并且能够很好地执行复杂的相机运动指令,比如跟随拍摄或低角度拍摄。
在技术指标上,其零样本I2V的时序一致性得分高达0.91,与那些经过专门监督微调的模型相比,差距在3%以内。
最后,是效率的对比。

单张英伟达A100 GPU上,生成一段5秒钟、720p分辨率(81帧)视频的端到端延迟,这个时间包含了文本编码、token生成和VAE解码的所有环节。
顶尖的扩散模型Wan 2.1耗时1864秒,超过了30分钟。
优秀的自回归模型Nova生成480p视频需要354秒,接近6分钟。
而InfinityStar,只需要58秒。
它实现了相对于扩散模型超过32倍的加速,相对于同类自回归模型超过6倍的加速。
这种效率的来源在于,InfinityStar的自回归步数K只有26步,每一步都可以并行预测数千个token。其总计算量,大约只相当于扩散模型单次UNet前向传播的十分之一。
走向无限长的交互式生成
为了让模型能够支持更具想象力的长交互视频生成,团队还专门训练了一个名为InfinityStar-Interact的扩展模型。
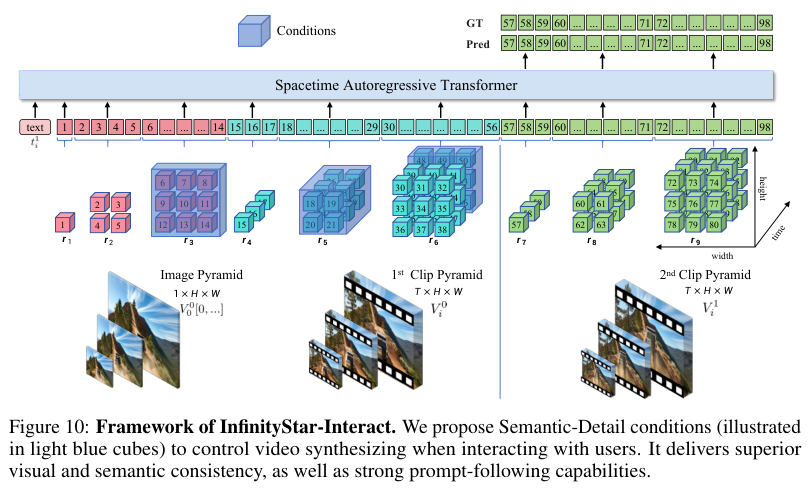
直接训练一个能够处理超长序列的模型是不可行的,会因为显存溢出而失败。
因此,模型采用了一种5秒滑动窗口的训练策略,窗口的步长为2.5秒,这样视频就被切分成了相互重叠的片段。
在训练时,模型每次只看到一对相邻的片段。但在推理时,这种机制可以被无限地扩展下去。
为了抑制在多轮交互后可能出现的语义漂移,模型在生成时,会始终将最早片段的首帧作为一个全局的视觉参考。
同时,为了在保持跨片段一致性的同时降低交互延迟,系统还设计了一种语义-细节双分支条件机制。
语义分支会将前一个片段的特征图在空间上进行32倍的下采样,将其压缩成一个高度浓缩的摘要信息。
细节分支则只从前一个片段中,切片最后几帧的高分辨率特征,用于保证帧与帧之间的平滑过渡。
通过这种方式,作为条件的token总数从33.6K个大幅降低到了5.8K个,使得交互延迟减少了5倍。

实验证明,如果没有这个双分支条件,仅仅依赖末帧作为基线条件,生成到第四个片段时,视频中人物的面部ID已经发生了明显变化。
而双分支条件则能很好地保持ID的一致性,动作衔接的像素误差小于2个像素。
当然,InfinityStar目前也存在一些技术局限性。
在高动态场景中,模型有时需要在保证运动连贯性和维持图像纹理细节之间做出权衡,这会导致图像质量指标约1.5dB的下降。
模型的参数规模目前为8B,相比大参数模型,还有巨大的成长空间。
在长交互生成中,误差累积的现象依然存在。大约10轮交互之后,视频质量会出现约12%的下降,表现为轻微的结构抖动和颜色漂移。
通过时空金字塔建模、知识继承分词器、随机量化器深度、语义尺度重复和时空稀疏注意力这五项核心技术,InfinityStar构建了首个能够支持720p工业级视频生成的离散自回归框架。
它在推理速度上,实现了数量级的提升,将视频生成带入了分钟级时代。
参考资料:
https://arxiv.org/pdf/2511.04675
https://github.com/FoundationVision/InfinityStar
https://huggingface.co/FoundationVision/InfinityStar
http://opensource.bytedance.com/discord/invite
END

















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









