



AI大模型,在预训练阶段吞下整个人类互联网的知识,而在训练结束后,几乎丧失了形成新的长期记忆的能力。
而且,每当模型试图学习新知识时,就会像覆盖旧磁带一样,不可避免地损害甚至抹去已经掌握的旧技能。
Google Research的几位科学家,向全世界展示了他们的一项研究,直指这个AI领域最根本的难题之一。

他们的研究论文《Nested Learning: The Illusion of Deep Learning Architectures》(嵌套学习:深度学习架构的幻觉),已提交给顶级会议NeurIPS 2025。

问题的根源:被割裂的架构与算法
长期以来,为了缓解灾难性遗忘,研究者们兵分两路。
一路人马专注于调整模型架构,比如设计更精巧的记忆模块。另一路人马则致力于改进优化算法,比如调整模型参数更新的规则。
这两条路径几乎是独立发展的,人们习惯性地将模型的结构和训练方法视为两个独立的组件。
这种碎片化的视角,虽然取得了一些进展,但始终未能从根本上解决问题。模型依然像一个静态的知识库,一旦定型,便难以生长。
Nested Learning(嵌套学习)的提出,旨在彻底打破这种认知框架。它认为,模型的架构和优化算法并非两个独立的东西,而是一个统一的、相互嵌套的系统。它们只是在不同层级上运行的优化问题而已。
这个想法,为构建一个能真正持续学习的AI,铺设了全新的理论基石。
Nested Learning的核心思想极其精炼:一个复杂的机器学习模型,本质上是一组相互嵌套或并行运行的优化问题。
想象一下人脑是如何学习的。
我们对眼前事物的瞬时记忆,更新速度极快。为了应付考试而进行的短期记忆,更新速度次之。而那些构成我们世界观、价值观的长期知识,则更新得非常缓慢,需要长时间的巩固。
人脑中并不存在一个统一的学习开关,而是无数个学习过程在以不同的速度同时进行。
Nested Learning将这个洞察应用到了AI上。它引入了一个关键概念:更新频率(Update Frequency)。

模型中的任何一个组件,无论是权重参数,还是优化器中的动量项,都有自己的更新频率。有些组件变得快,有些变得慢。这种快慢之分,自然形成了一种层级结构。
比如,一个最简单的梯度下降优化过程,在Nested Learning的视角下,可以被重新理解为一个嵌套结构。
外层,是模型参数W的学习。它的目标是找到最优的W,以最小化在训练数据上的损失。这是一个慢过程。
内层,是权重更新规则本身。每一步更新,都可以看作一个微型的、独立的优化问题。它的目标是根据当前的梯度信息,最有效地调整W。这是一个快过程。
就连Adam这类高级优化器里的动量项,也可以被看作是一个微型的关联记忆模块。它的任务只有一个:用梯度下降的方式,将过去一系列的梯度信息压缩并存储起来,供外层的参数学习使用。
所以,优化器本身就是一个学习模块。架构与优化,在这一刻实现了统一。
这个看似简单的视角转换,打开了一个全新的维度。如果优化器本身就是个学习器,我们为什么不能让它变得更强大、更深呢?
三大创造:从理论到可触摸的AI实体
基于Nested Learning的统一框架,研究者们顺理成章地提出了三大核心贡献,将这一理论转化为了具体的技术路径。
首先是深度优化器(Deep Optimizers)。
既然标准优化器可以被看作是简单的关联记忆模块,那么我们完全可以用一个更复杂的模型,比如一个小型神经网络(MLP),来替代它。这就诞生了所谓的深度动量梯度下降(DMGD)。这个深度的优化器,拥有更强的表达能力,能更智能地学习如何利用历史梯度信息来指导模型的训练。
其次是自修改架构(Self-Modifying Titans)。
研究者们将这一思想应用于序列模型,对Google先前发布的Titans架构进行了扩展。新的架构不仅学习外部世界的知识,还学习如何学习。它能根据任务动态地调整自身的学习算法,包括注意力机制中的键、值、查询投影等关键部分。这让模型拥有了某种程度的自我意识,能够在使用过程中不断优化自己的学习策略。
最后是连续记忆系统(Continuum Memory System, CMS)。
这彻底颠覆了传统AI模型中短期记忆(如注意力)和长期记忆(如前馈网络)的二元划分。CMS将记忆视为一个连续的光谱。
它由一系列神经网络块(MLP blocks)链接而成,每个块都关联着一个特定的更新频率。
更新最频繁的块,负责处理瞬息万变的上下文信息,如同我们的工作记忆。
更新频率稍慢的块,负责整合一个阶段内的知识,形成中期记忆。
而更新最慢的块,则负责将长期、稳定、抽象的知识沉淀到参数中,形成模型的世界观。
这种多速率的记忆系统,使得模型可以在不干扰核心知识的情况下,灵活地吸收新信息,从而在根本上解决了灾难性遗忘问题。
HOPE架构:一个会呼吸的生命体
理论的价值,最终要由实践来检验。
研究团队将上述三大贡献融为一体,构建了一个全新的、基于Nested Learning原则的自引用学习模块,并将其命名为HOPE(Hybrid Optimizer with Persistent Embedding)。
下图清晰地展示了HOPE架构与传统Transformer架构主干的差异。
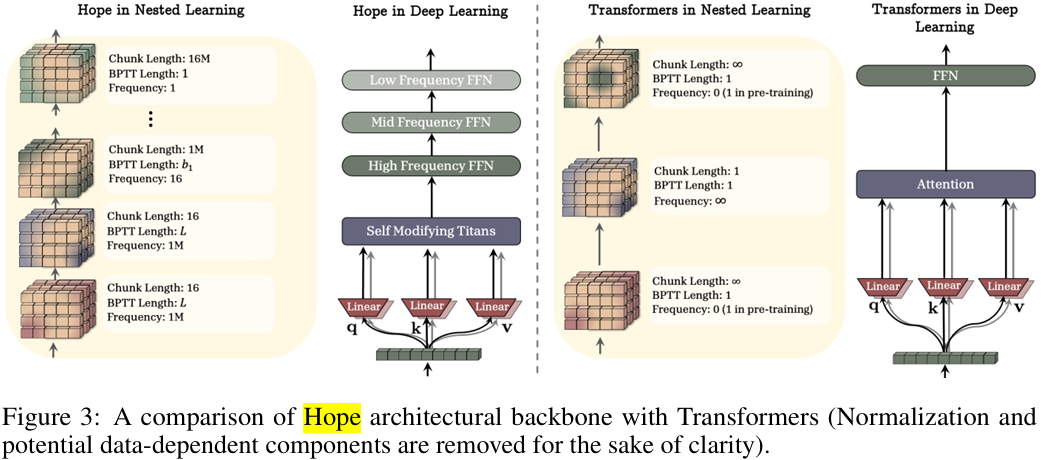
传统的Transformer,其前馈网络层在训练后基本是静态的,负责存储持久化的知识。而HOPE则为每一个记忆层级(对应不同的更新频率)都配备了专属的前馈网络,形成了一个多层次、动态更新的知识存储系统。
这让HOPE架构看起来更像一个有生命的组织,拥有不同节律的呼吸和心跳。
性能测试数据证明了这种设计的优越性。
研究者们在语言建模和常识推理任务上,对340M、760M和1.3B三种参数规模的HOPE模型进行了全面测试。
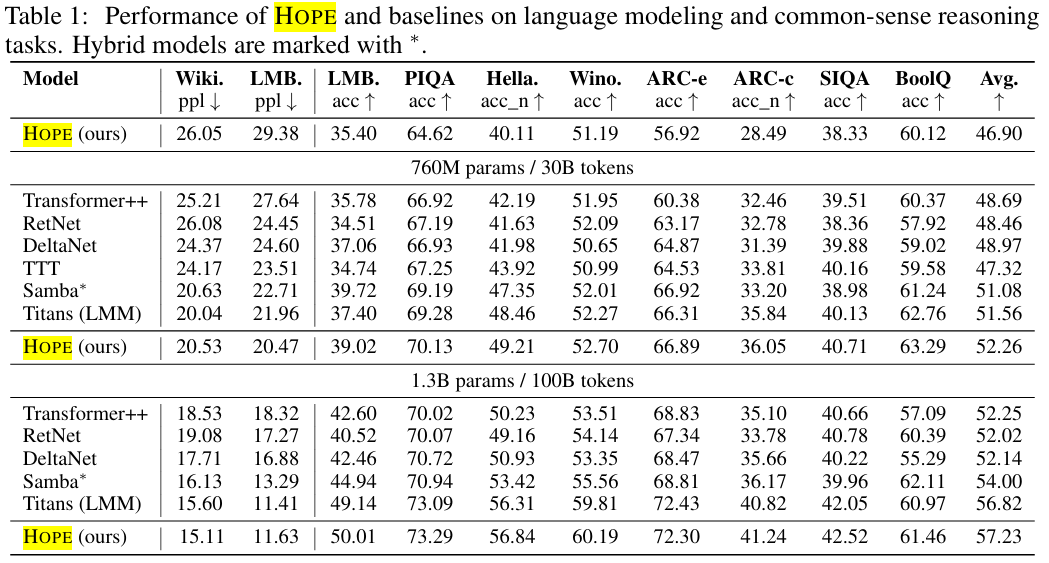
HOPE的平均分,超越了所有对比模型。
HOPE表现出更低的困惑度,更高的准确率。
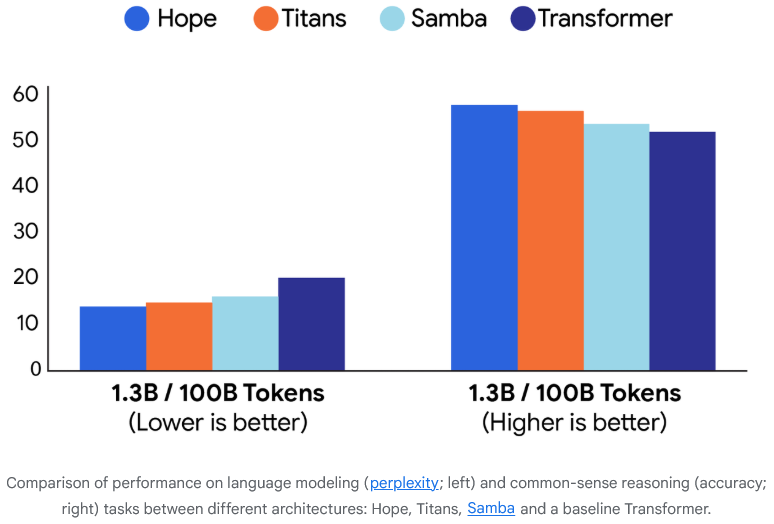
Hope在长上下文的Needle in Haystack(NIAH)下游任务中展示了卓越的内存管理,证明CMS提供了一种更高效、更有效的方法来处理扩展的信息序列。
Nested Learning将从根本上改变需要终身学习的应用领域,比如机器人、自动驾驶、个性化AI助手等。
这些系统将不再需要昂贵的、从头开始的再训练,而是能够像我们一样,在保留已有知识的基础上,不断学习和成长。
研究者们也坦诚,目前的研究主要聚焦于记忆的在线巩固过程,而对类似人脑睡眠时的离线重放和整理机制涉猎不多。
但无论如何,它让我们距离那个能像人类一样持续学习、不断进化的通用人工智能,又近了一步。
参考资料:
https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/
https://abehrouz.github.io/files/NL.pdf
END

















 3995
3995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









