



AI处理长文本的尽头,或许是把文本变成图或视频。
DeepSeek-OCR刚发布,马斯克说:从长远来看,人工智能模型的输入和输出中 99% 以上都将是光子。直到不能缩放。
第二天,智谱就发布论文《Glyph: Scaling Context Windows via Visual-Text Compression》(通过可视文本压缩缩放上下文窗口),核心思想简直一模一样。

GitHub的开源链接也同一时间放出来了,可能模型训练慢了点(猜的😄),不然应该与DeepSekk-OCR同时发布并开源。
大型语言模型的能力越来越强,但在处理长篇文档,复杂的代码库或多步骤推理任务时,总会撞上一堵名为上下文长度的墙。
如果将上下文窗口暴力扩展到百万Token级别,会带来难以承受的计算和内存成本,这极大地限制了长上下文模型的实际应用。
清华大学交叉信息研究院CoAI团队,智谱AI,清华大学知识工程研究室(KEG),提出了一个名为Glyph的全新框架。
Glyph不再执着于扩展基于Token的文本序列,而是先将长篇文字渲染成一张紧凑的图片,然后让一个视觉-语言模型(VLM)去阅读这张图片。
这个简单的思路,带来了革命性的效果。
以小说《简·爱》为例,全书约有24万个文本Token。一个拥有128K上下文窗口的传统大模型,连一半都装不下,自然无法回答简离开桑菲尔德后,是谁帮助了她?这类需要通览全文的问题。
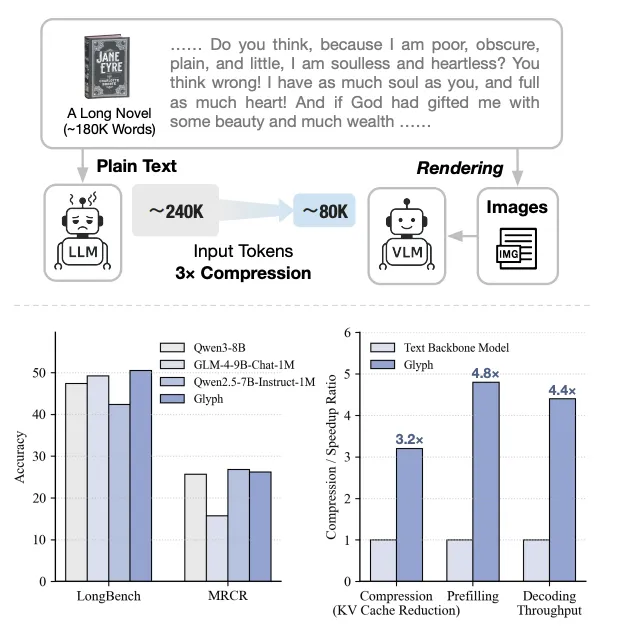
Glyph将整本书渲染成一系列紧凑的图像后,总共只占用了约80K个视觉Token。一个128K上下文的VLM就能轻松看完整本书,并准确回答上述问题。
这种视觉-文本压缩技术,在保持与Qwen3-8B等顶尖模型相当准确率的同时,实现了3到4倍的Token压缩,带来了约4倍的推理速度提升和约2倍的监督微调(SFT)训练加速。
它为长上下文建模,打开了一扇全新的大门。
AI被困在了序列长度的牢笼里
模型处理的文本越长,注意力机制所需要的计算量就呈二次方增长。这意味着上下文长度增加一倍,计算和内存成本会增加四倍。这道指数级的墙,让百万级上下文的处理变得异常昂贵。
为了拆掉这堵墙,研究者们探索了许多路径。
一种是改造位置编码,比如YaRN技术,它让预训练好的模型能够外推,接受比训练时更长的输入。但这种方法治标不治本,它既不能加速推理,在处理超长序列时准确性也会下降。
另一种是修改注意力机制本身,比如使用稀疏注意力或线性注意力。这些方法通过让每个Token只关注一部分相关的Token,将二次方的计算复杂度降低。这在一定程度上提升了效率,但Token的总数并没有减少。当上下文长度增长到几十万时,总体开销依然巨大。
还有一种是检索增强生成(RAG),它通过从外部知识库中检索相关片段来缩短输入。这种方法很实用,但它依赖检索器的准确性,可能会遗漏关键信息,并引入额外的系统延迟。
这些方法都在同一个框架内打转:如何更高效地处理一个超长的文本Token序列。
Glyph则跳出了这个框架,它提出的问题是:为什么我们一定要处理文本Token序列?
Glyph让AI学会了看图读书
Glyph的核心洞察在于,图像承载信息的方式,比线性文本要密集得多。
一个视觉Token(图像的一个小块),可以包含多个单词甚至一整行文字,而这些文字原本需要几十个文本Token来表示。
Glyph利用视觉-语言模型(VLM)的能力,直接在文本的字形(glyph)上进行操作,将每个视觉Token都视为多个文本Token的紧凑载体。
通过这种方式,一个上下文窗口固定的VLM,能够处理比同等窗口大小的纯文本LLM长得多的文本内容。
这个过程,Glyph通过一个系统性的三阶段框架来实现。
第一阶段是持续预训练。

这个阶段的目标,是把模型强大的长上下文理解能力,从它熟悉的文本世界,迁移到全新的视觉世界。
研究团队收集了包括书籍,文章,代码在内的大量长文本数据,然后将它们渲染成各种风格的图像,构成了一个庞大的视觉文本数据集。
渲染时,他们故意引入了各种变化,比如不同的字体大小(9-14pt),不同的字体样式(SourceSans3,Verdana),不同的页面布局(960×540),不同的背景颜色和行高。
这样做的目的,是让模型学会适应各种视觉化的文本,而不是只认识某一种特定的印刷品。
训练时,模型被要求完成两项任务。一项是类似完形填空的掩码语言建模,即随机遮盖图像中的一部分文字,让模型根据上下文猜出被盖住的内容。这能迫使模型学习如何从视觉信号中重建文本信息。
另一项是更直接的长上下文理解任务,即向模型展示完整的渲染文本图像,然后就全文内容进行提问。
通过这个阶段的特训,VLM初步具备了看图读书的能力。
第二阶段是LLM驱动的渲染搜索。
如何将文本渲染成图片,这里面大有学问。
字体大一点,AI可能看得更清楚,但一张图能装下的内容就少了,压缩率就低了。
页面布局紧凑一点,压缩率高了,但如果文字挤成一团,AI可能就看不懂了。
字体大小,页面布局,图像分辨率,背景颜色……这些渲染参数的任意组合,都会直接影响最终的压缩率和模型性能。
这个参数组合构成的搜索空间极其庞大,手动去试显然不现实。
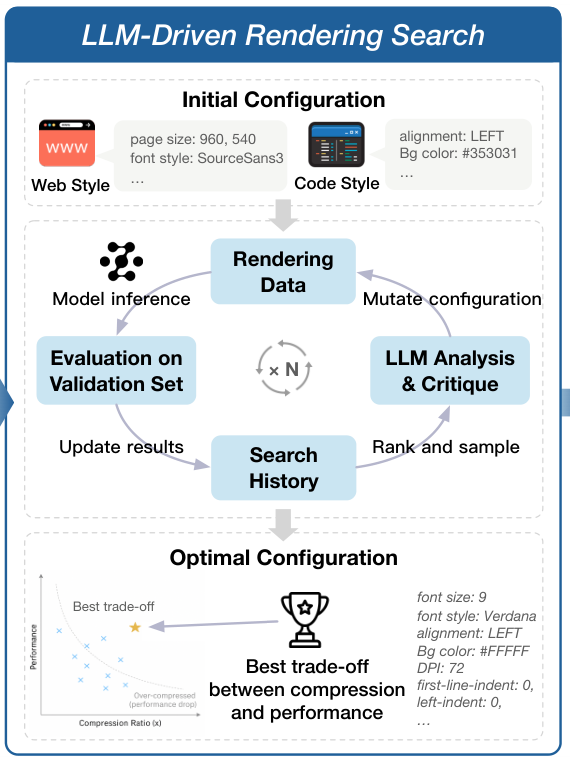
Glyph设计了一种由LLM驱动的遗传搜索算法,来自动寻找最优的渲染配置。
遗传算法的流程,模仿了生物进化。
它首先会随机生成一批初始的渲染配置方案,作为初始种群。
然后,它会用每一种方案去渲染文本,并让一个作为裁判的LLM来评估效果,给出适应度评分。这个评分会综合考虑压缩率,光学字符识别(OCR)的准确率,以及模型在下游任务上的初步表现。
得分高的方案会被保留下来,进入繁殖阶段。它们会像生物遗传一样,进行交叉和变异,组合出新的,可能更优秀的配置方案。
这个评估-选择-繁殖的过程会不断迭代,直到找到一组在压缩率和性能之间取得最佳平衡的帕累托最优配置。
这套由LLM驱动的自动化搜索机制,是Glyph的关键创新之一,它用AI的智慧,为AI找到了最高效的学习材料。
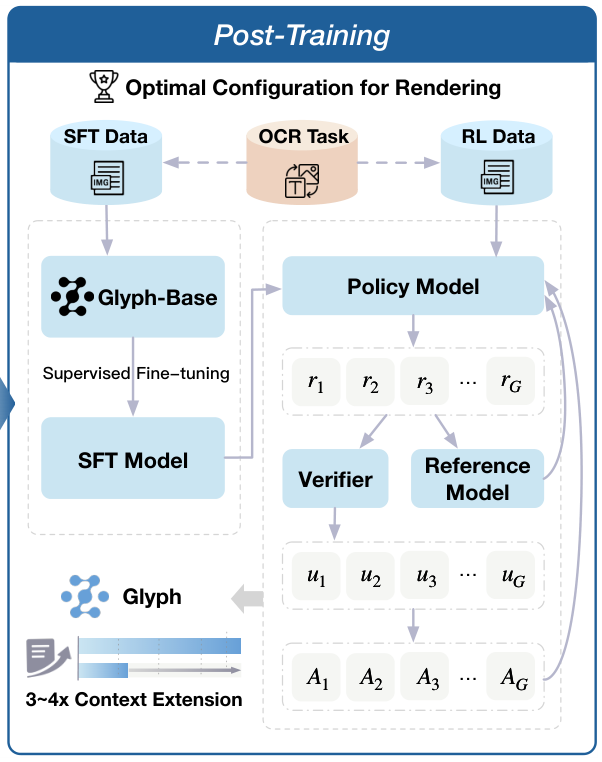
第三阶段是后训练。
找到了最佳的渲染菜谱后,就需要对模型进行精细化的烹饪了。
后训练阶段包含监督微调(SFT)和强化学习(RL)。
在监督微调阶段,研究团队使用大量高质量的图文对数据,比如渲染后的文档和对应的问题答案,对模型进行训练。这让模型学会在视觉压缩的设定下,完成问答,摘要等具体任务。
为了让模型的回答更符合人类的偏好和逻辑,研究团队还引入了基于人类反馈的强化学习(RLHF)。人类对模型的不同回答进行排序打分,这些反馈信号会指导模型优化自己,生成更高质量的响应。
值得一提的是,在整个后训练过程中,Glyph还加入了一个辅助的OCR(光学字符识别)任务。
这个任务要求模型不仅要理解图片里文字的意思,还要能精准地读出每一个字。这就像让学生在做阅读理解的同时,也练习朗读和抄写。
这个简单的辅助任务,极大地增强了模型对图像内文本细节的识别能力,更好地对齐了它的视觉和文本表征,让最终的Glyph模型既能看懂,也能读准。
实验结果证明了新范式的威力
Glyph在一系列长上下文基准测试中,证明了其方法的有效性。
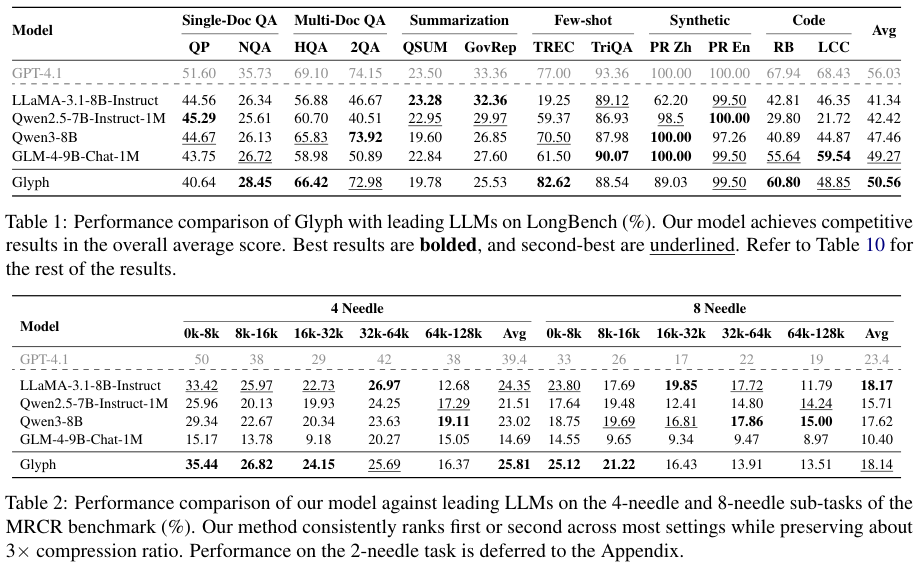
首先是压缩效率。
3到4倍的Token压缩率,意味着原本需要一个拥有400K上下文窗口的LLM才能处理的任务,现在一个128K上下文的Glyph模型就能胜任。
在一次极限测试中,一个128K上下文的VLM,通过Glyph的视觉压缩,成功处理了百万Token级别的文本任务。
其次是性能保持。
压缩了这么多,性能会下降吗?实验结果给出了否定的答案。
在LongBench和MRCR等多个权威的长上下文基准测试中,Glyph的准确率与强大的开源模型Qwen3-8B不相上下。
这证明了Glyph的视觉压缩是一种无损压缩,它在显著减少Token数量的同时,几乎没有牺牲模型的语义理解能力。
最后是速度的巨大提升。
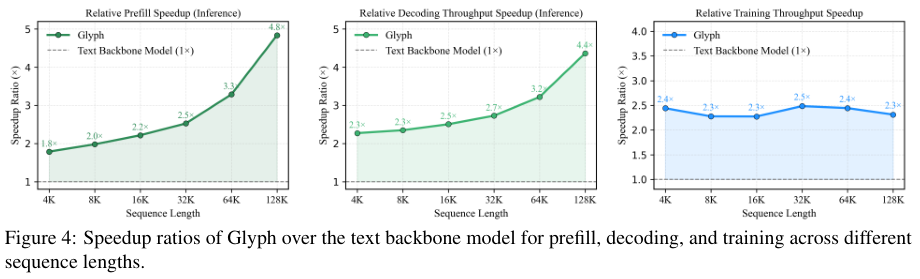
Token数量的减少,直接带来了计算量的下降,最终体现为训练和推理速度的提升。
Prefill阶段是模型处理输入提示的过程,解码阶段是模型生成回答的过程。在这两个核心环节,Glyph都实现了超过4倍的速度提升。在训练阶段,监督微调的速度也翻了一倍。
这种全方位的效率提升,让Glyph在处理海量长文本的实际应用场景中,具备了无可比拟的优势。
案例研究也展示了Glyph在真实世界任务中的能力。
在处理长篇小说《简·爱》(约240K文本Token)时,Glyph能通览全局,回答跨越多个章节的复杂问题。
在分析一个包含180K文本Token的大型代码库时,Glyph能够准确识别跨文件的函数调用和依赖关系,这是传统上下文受限模型无法做到的。
有趣的是,尽管Glyph是为文本压缩而设计的,但它在处理图文混排的真实多模态任务时,也表现出了优异的性能。
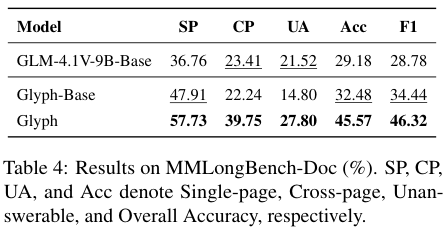
Glygph的准确率比传统的VLM高出许多,证明了这种方法的强大泛化潜力。
视觉压缩可能成为AI的新语言
Glyph的成功,为长上下文建模指出了一条全新的,可能更具前景的道路。
它不再纠结于如何优化注意力机制去处理更长的序列,而是从根本上改变了信息的表示方式,从一维的文本序列,变成了二维的视觉信息。
这种范式转移,带来了计算效率和信息密度的双重提升。
它也存在一些待解决的挑战。比如渲染过程本身需要额外的计算开销,渲染的质量直接影响模型性能,以及在某些高度结构化的特殊文档格式上,可能还需要进一步的优化。
未来的研究可以探索自适应渲染,即让系统根据文本内容的特点,自动调整渲染参数。也可以将这一框架扩展到更广泛的多模态应用中。
Glyph的探索证明,视觉-文本压缩更有可能成为下一代AI系统处理信息的基本方式。
AI将不再逐字阅读,而是学会了一目十行。
参考资料:
https://arxiv.org/abs/2510.17800
https://arxiv.org/abs/2401.01567
https://github.com/thu-coai/Glyph
END

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









