



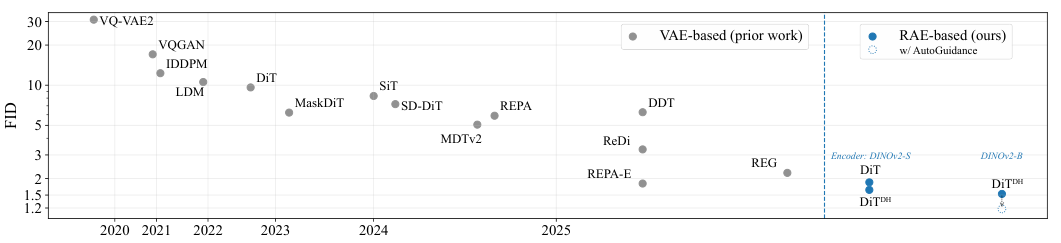
谢赛宁团队用一种RAE的新架构,将ImageNet图像生成FID(评估生成图像质量的指标)刷到了1.13,直接宣告了沿用多年的VAE组件的过时。
谢赛宁是谁?计算机视觉领域一位无法绕开的人物。他的名字和一系列如雷贯耳的工作联系在一起:ResNet(深度残差网络)、MAE(掩码自编码器),以及开启新时代的DiT(扩散Transformer)。从解决深度网络训练,到引领自监督学习范式,再到定义扩散模型的架构,他的研究一直在推动领域的前沿。
曾于AI教母李飞飞合作,进行 “空间思维”(Thinking in Space)的研究,探索了多模态大语言模型(MLLM)如何看见、记忆和回忆空间。

这篇关于RAE的论文,正是他研究脉络的延续。它将最先进的表征学习成果(MAE、DINO等)和最强大的生成模型框架(DiT)完美地结合在一起,解决了困扰后者许久的问题。
用了三年的老组件,该换了
生成模型的世界里,变分自动编码器(Variational Autoencoder,简称VAE)曾经是个明星。2013年,Diederik P. Kingma和Max Welling把它带到世人面前,整个无监督学习领域都为之一振。
传统的自动编码器,把一张图片压缩成一个点,再从这个点把图片复原出来。VAE不一样,它更像个艺术家,把图片压缩成一片充满可能性的“灵感云”,也就是一个概率分布。解码器从这片云里随便抓一个点,就能创作出一幅全新的、又符合原作风格的画。
这个“灵感云”就是潜在空间。因为是概率分布,所以这个空间是连续的、有结构的。你可以在空间里平滑地移动,看到图片丝滑地从一只猫变成一条狗,这就是插值。VAE的核心就是通过最大化一个叫“证据下界”(ELBO)的东西来训练,它既要保证复原的图片够清晰(重构项),又要保证“灵感云”的形状规整,接近标准正态分布(KL散度项)。
VAE的这个特性让它成了生成模型的宠儿。
后来,扩散模型(Diffusion Models)火了。人们发现,直接在像素空间里一步步加噪声、再一步步去噪声,生成图片的质量惊人。但这个过程太慢了,一张高分辨率图片动辄几百万个像素,计算量大得吓人。
于是,潜空间扩散模型(Latent Diffusion Models,简称LDM)应运而生。思路很简单:别在像素空间里折腾了,把它压缩到低维的潜空间里去搞扩散,最后再用解码器复原出来。这个负责压缩和复原的组件,大家不约而同地选了VAE。
再后来,扩散Transformer(Diffusion Transformers,简称DiT)出现了,用更强大的Transformer架构替代了U-Net。但里面的VAE组件却一直没怎么变。大家用的还是2021年提出的SD-VAE。
这就有点尴尬了。
SD-VAE的局限性越来越明显。
它的骨干网络是卷积神经网络,跟现在主流的视觉Transformer(ViT)架构比,效率有点跟不上了。
而且压缩太狠,一张256×256的图片,被压成了32×32×4的潜空间表示。信息损失严重,像把一本万言书硬是缩写成了一百字的摘要,很多细节都丢了,这直接限制了最终生成图片的质量上限。
最要命的是VAE的表征能力太弱。它训练的目标就是“重建”,只要能把图片原样画出来就行,至于图片里到底是什么,它并不真正在意。用一个叫“线性探测”的测试方法去评估它的语义理解能力,SD-VAE在ImageNet数据集上的准确率只有可怜的8%。作为对比,现在主流的自监督学习方法,这个数字能超过80%。
一个连猫和狗都分不清的编码器,你很难指望它能为生成模型提供多么高质量的语义信息。
整个领域都在一个过时、低效、能力孱弱的组件上构建着越来越复杂的摩天大楼。是时候把它换掉了。
RAE登场,直接釜底抽薪
一篇名为《Diffusion Transformers with Representation Autoencoders》的论文出现在arXiv上。

这篇论文没有在原有框架上修修补补,而是直接指出了问题的核心:别再用那个老掉牙的VAE了。
他们提出了一个新概念,叫表征自编码器(Representation Autoencoders,简称RAE)。
RAE的思路简单粗暴,却异常有效。
与其从零开始训练一个既要压缩又要保留语义的编码器,为什么不直接拿来主义?现在社区里有那么多强大的、预训练好的视觉表征模型,它们在海量数据上学习过,语义理解能力超强。我们只需要一个编码器,它的任务就是提取特征,那就用它们好了。
于是,研究团队选了三个当红的预训练模型作为RAE的编码器:
-
DINOv2-B:一个自监督学习的尖子生,不需要标签就能学到丰富的图像语义信息。
-
SigLIP2-B:一个语言监督模型,通过图文配对学习,对图像的理解更接近人类。
-
MAE-B:通过“完形填空”的方式(遮住图片一部分让模型去猜)来学习。
选好了编码器,事情就简单了。把这些预训练好的编码器直接冻结,不让它的参数变化,然后只训练一个解码器。解码器的任务,就是学会把这些强大的编码器提取出的特征(潜在表示)给重新画成图片。
训练解码器的目标函数也很直接,用了三种损失的组合:L1损失保证像素级别的相似,LPIPS损失保证感知上的一致性,对抗损失(GAN)则让生成的图片更真实、更具欺骗性。
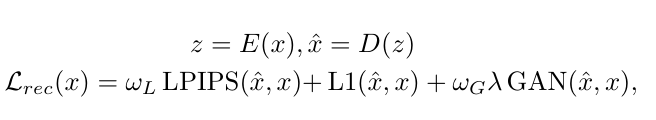
RAE的核心就是用一个顶级的、预训练好的“眼睛”(表征编码器)搭配一个后天训练的“画手”(解码器)。
效果怎么样?

SD-VAE与RAE(DINOv2-B)比较。VAE依赖于具有强烈下采样和上采样的卷积骨干网络,而RAE则使用无压缩的视觉Transformer(ViT)架构。SD-VAE的计算成本也更高,其编码器和解码器所需的GFLOPs分别约为RAE的6倍和3倍。

在ImageNet-1K数据集上,RAE在重建(rFID)和表征质量方面始终优于SD-VAE,同时效率更高。
最关键的表征质量,也就是语义理解能力。RAE因为直接用了预训练编码器,它的表征能力完全继承自这些强大的模型。DINOv2-B高达84.5%的准确率,意味着它对图片内容的理解,和SD-VAE的8%,完全不在一个次元。
RAE不仅画得更像,而且懂得更多。
新挑战与新架构
把VAE换成RAE,看似解决了所有问题。但事情没那么简单。
RAE的潜在空间和VAE有一个巨大的不同:维度。
VAE为了效率,把潜空间压得很小。而RAE用的这些预训练编码器,为了保留丰富的语义信息,生成的潜在表示维度非常高。比如DINOv2-B,输出的token维度是768。
当研究者兴冲冲地把标准的DiT模型直接架在RAE的高维潜空间上时,发现模型根本学不动了。高维空间带来的挑战是巨大的。
论文团队没有回避这个问题,而是深入分析并提出了三个关键的解决方案。
第一个方案:加宽DiT模型。
他们通过理论和实验发现一个残酷的事实:扩散模型的宽度,必须大于等于潜空间里单个token的维度。否则,模型容量就不够,无法有效学习。这颠覆了很多人“数据流形有低内在维度”的直觉。论文给出的解释是,扩散过程本身会给数据注入高斯噪声,这个操作会把原本可能很“窄”的数据流形“撑开”,使其充满整个高维空间。要想处理这个被撑开的流形,就需要一个足够“宽”的模型。
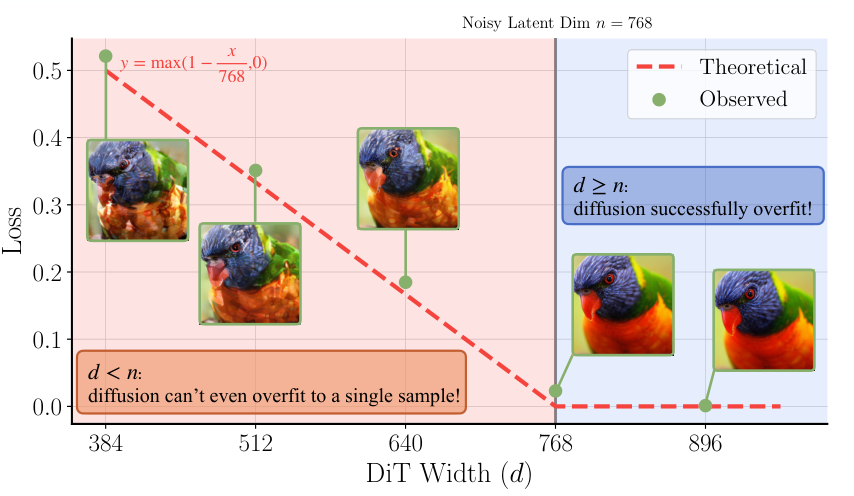
第二个方案:按维度调整噪声调度。
之前的研究发现,在扩散过程中,对分辨率越高的图片加同样程度的噪声,信息的损坏程度会越小。RAE的潜空间虽然空间分辨率(H×W)不大,但通道数(C)非常多。高斯噪声是同时作用于所有维度的,所以通道数的增加,也相当于变相增加了每个token的“有效分辨率”。因此,噪声的添加策略不能只看空间分辨率,而要看“有效数据维度”,也就是token数量乘以其维度。他们采用了一种移位策略,根据潜空间的维度来动态调整噪声的强度,效果显著提升。
第三个方案:给解码器也加点噪声。
RAE的解码器是在编码器处理过的、干净的训练集上训练的。但扩散模型在推理时,生成的是去噪后的结果,这个结果不可能完美,总会带有一些噪声,或者和训练集的分布有细微偏差。这对解码器来说,是个分布外(OOD)的挑战,很容易导致生成质量下降。
怎么办?
在训练解码器的时候,就主动给输入的潜空间表示加上一点高斯噪声。这样解码器就提前“见过世面”了,对带噪声的输入有了抵抗力,泛化能力变得更强。
解决了这三个问题,DiT是可以在RAE的高维潜空间里愉快地工作了。但新的问题又来了:为了匹配高维潜空间,把整个DiT模型都加宽,计算成本太高了,FLOPs(浮点运算次数)会呈二次方增长。
于是,研究人员借鉴了一篇名为DDT(Decoupled diffusion transformer)的论文。核心思想是,没必要把整个模型都搞得那么宽。DiT的主干部分可以保持原来的宽度,负责处理序列信息。而在最后负责去噪的那一步,给它加上一个又宽又浅的Transformer模块,专门用来处理高维度的去噪任务。
这个模块被称为“扩散头”(Diffusion Head)。
DiTDH架构就这样诞生了。DiTDH模型由一个基础的DiT模型M和一个宽头H组成。整个流程是:噪声输入先进M,得到一个初步处理的结果,然后再把这个结果和原始噪声输入一起喂给H,由H来预测最终的速度向量。

这种设计,用很小的计算量增长,就实现了模型有效宽度的极大增加。
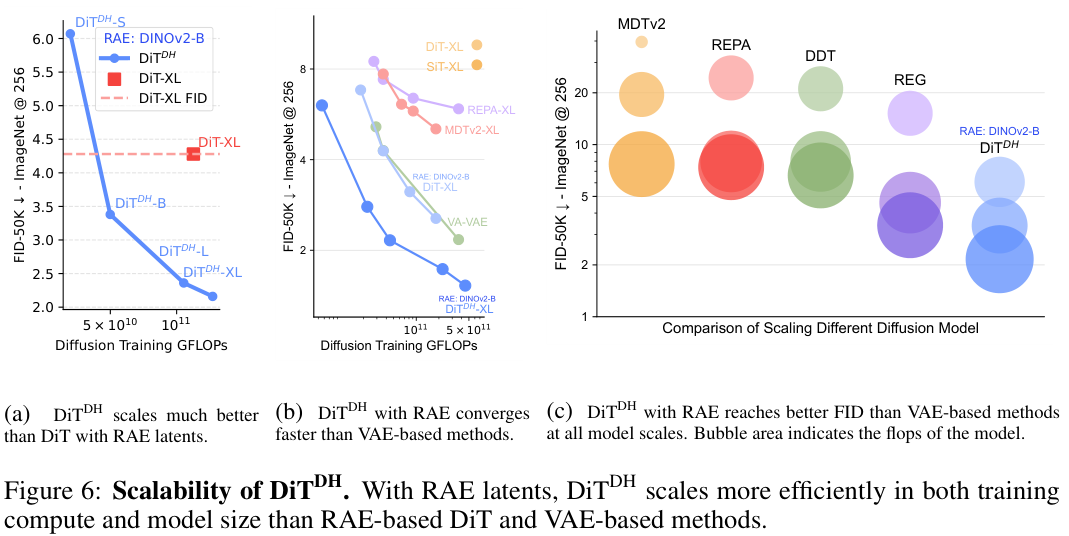
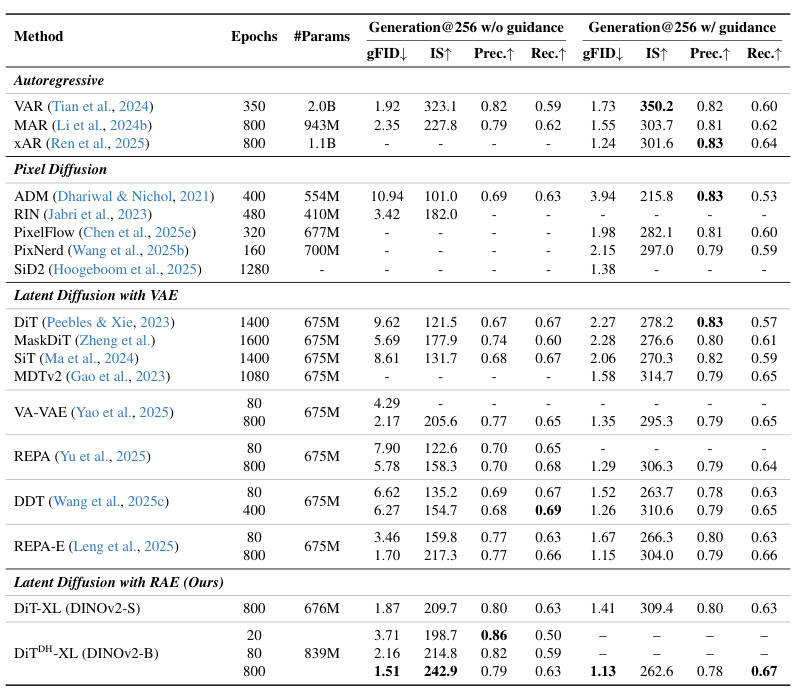
实验结果证明了DiTDH的恐怖效率。在RAE潜空间上,DiTDH-B只用了DiT-XL大约40%的训练计算量,效果却远超后者。当把DiTDH也扩展到XL规模时,它实现的FID(一种衡量生成图片质量的指标,越低越好)只有2.16,几乎是同等计算量下DiT-XL的一半。
就这样为RAE这样的高维潜空间量身定做了DiTDH架构。
性能桂冠与未来展望
有了RAE和DiTDH,谢赛宁团队开始在标准的ImageNet生成任务上验证他们的成果。
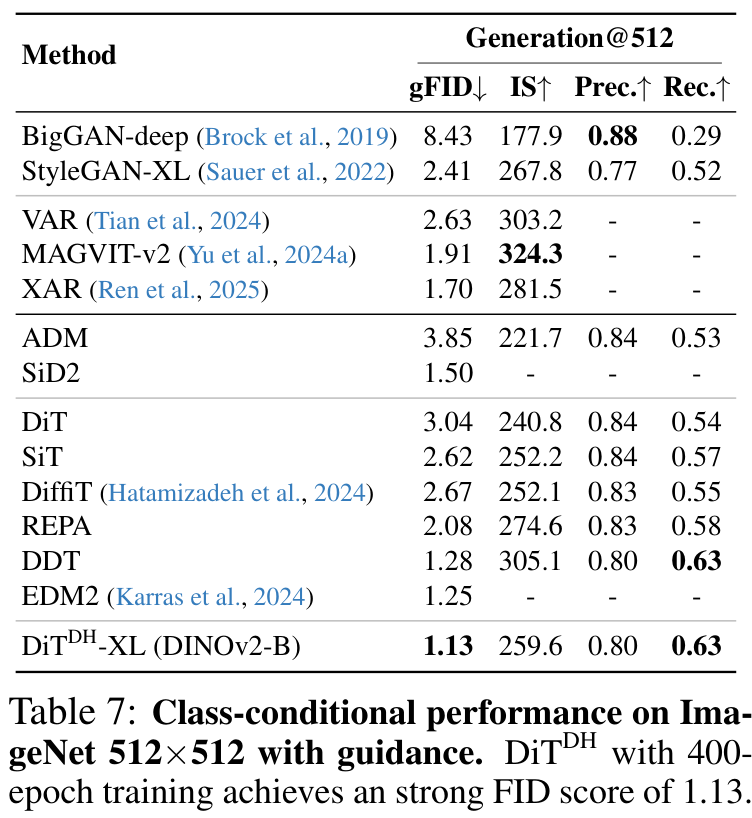
DiTDH-XL模型与目前最先进扩散模型进行了定量比较。大幅优于所有先前的扩散模型,在256×256的情况下,创下了无引导时1.51、有引导时1.13的新的最先进FID分数。
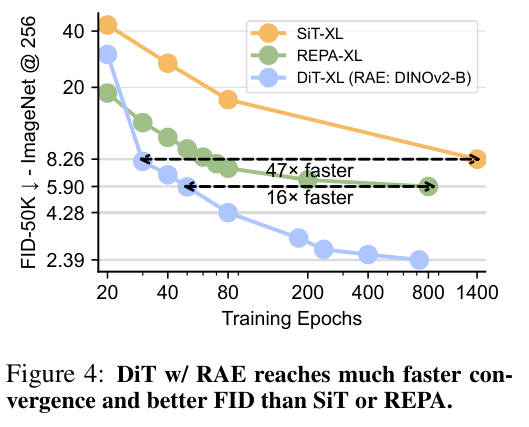
除了最终效果好,收敛速度也快得惊人。在同等模型大小下,基于RAE的DiT不仅比基于VAE的基线(如SiT-XL)训练速度快了47倍,甚至比最近的一些基于表征对齐的方法(如REPA-XL)也快了16倍。
使用AutoGuidance在512×512分辨率下训练的模型所生成的定性图像,展现出强大的多样性、精细的细节和较高的视觉质量。

这篇论文还做了一些有趣的探索。
比如高分辨率合成。他们发现,由于RAE的解码器和扩散过程是解耦的,可以训练一个256×256的扩散模型,然后在推理时,直接换上一个具备上采样功能的解码器,就能生成512×512的图片,而不需要重新训练扩散模型。这大大提高了生成高分辨率图像的效率。
一直以来,人们致力于在VAE的框架内进行各种对齐、蒸馏,试图提升其表征能力。而RAE则釜底抽薪,直接用现成的、更强大的表征编码器取而代之。
思路一下打开了。
参考资料:
https://www.sainingxie.com
https://scholar.google.com/citations?user=Y2GtJkAAAAAJ&hl=en
https://arxiv.org/abs/2510.11690
https://arxiv.org/abs/2212.09748
https://arxiv.org/abs/2104.14294
https://arxiv.org/abs/2111.06377
https://arxiv.org/abs/2502.14786
END

















 4119
4119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









