




本文来源公众号“极市平台”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/8wl-0bTE1kebvB7BOZ45bQ
极市导读
RAE 用冻结的 DINOv2 等预训练编码器+轻量可训解码器,替代传统 VAE,为高维潜空间提供丰富语义;配合加宽 DiT 与噪声增强训练,在 ImageNet 256/512 上实现 SOTA FID,并显著加速收敛。
本文目录
Representation Autoencoder:语义丰富的预训练 Encoder + 训练 Decoder
(来自 NYU,Saining Xie 团队)
1 RAE 论文解读
1.1 RAE 做了什么事?
1.2 RAE 的 Autoencoder 是怎么训练的?
1.3 用 RAE 可以直接就把 DiT 训练好吗?
1.4 怎么用 RAE 训练 DiT?
1.5 用一个宽的 DDT Head
1.6 与 state-of-the-art 扩散模型对比
1.7 讨论部分
太长不看版
NYU 谢赛宁团队最近的工作提出 RAE:用一个语义信息丰富的,预训练好的 Encoder。训一个用于生成任务的,作为辅助的 Decoder。
如今的生成式模型一般需要一个预训练的 Autoencoder (AE) 将 Pixel 映射到扩散过程的 Latent Space,然后 Diffusion Transformer (DiT) 在这个 Latent Space 上进行去噪任务。完事之后,再给 Decoder 生成最终图片结果。这也成为现在训练扩散模型的标准做法之一。
RAE 这个工作觉得目前的 AE 模型有点过时了,比如说很多还在延续过去的 SD-VAE 模型。相对之下,本文提出了一个新的 Representation Autoencoder。怎么做的呢?
-
语义丰富度上:Encoder 使用预训练的模型,比如 DINO,MAE。这类模型语义信息丰富。
-
适配生成任务:Decoder 训练一下 (论文叫做 DDT head),为了满足生成任务的需求。
RAE 搭配上 DiT 变体的实验结果证明,可以在 ImageNet 256 × 256 以及 512 × 512 上实现很好的 FID 指标。
下面是对本文的详细介绍。
Representation Autoencoder:语义丰富的预训练 Encoder + 训练 Decoder
论文名称:Diffusion Transformers with Representation Autoencoders
论文地址:https://arxiv.org/pdf/2510.11690
项目主页:https://rae-dit.github.io/
01 RAE 论文解读
1.1 RAE 做了什么事?
关于生成式模型一直都有两个常见的观点:
其一是用于理解的 Encoder,比如 DINOv2,不适合用于重建,因为太过于关注语义信息了。
其二是 Diffusion Model 其实更偏好低维度的 Latents,在高维 Latents 的情况下表现不佳。
本文反驳了这两个论点,反驳的理由就是提出:使用预训练的 Encoder (比如 DINOv2),冻结参数,然后训练 Decoder。用这样得到的 Encoder + Decoder 替代 VAE,配合 Diffusion Model 完成图像生成任务,如下图 1 所示。
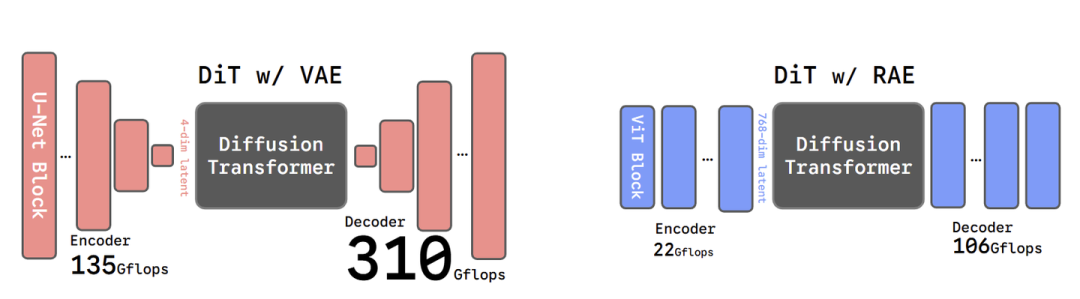
图1:(左) SD-VAE。(右) RAE。图示的 RAE 使用 DINOv2-B 编码特征。VAE 使用卷积架构,而 RAE 使用 ViT 的架构
RAE 证明:
-
尽管 Encoder 是冻结参数的,依然可以实现比 SD-VAE 更好的重建性能。
-
RAE 编码的表征维度很高 (比如 768),相比于 VAE 编码的维度 (比如 4) 而言。尽管如此,DiT 的训练仍可以很高效且稳定。
RAE 解决的核心问题是:当 Latents 维度比较高的时候 (比如 768),DiT 要怎么设计架构或者训练才能够 work?本文的答案是:
-
DiT 宽度
-
Noise Schedule
-
Noise-augmented Decoder Training
1.2 RAE 的 Autoencoder 是怎么训练的?
RAE 挑战了一个观点:
预训练的 Representation Encoder (比如 DINOv2 或者 SigLIP2),不适合重建任务,因其 "重高级语义信息,轻底层细节信息"。
RAE 挑战的方法也很直观,即:固定 Representation Encoder,然后以重建目标训练 Decoder。
具体如下。

可以看得出来,hidden size 都很高。
Decoder 使用 ViT-XL。
评价指标:ImageNet 的 rFID。
那么这样训出来的 Decoder,配合预训练的 Encoder,的重建效果到底如何呢?
下图2的这几个图:
(a):不同 Representation Encoder 的重建效果对比 (以 rFID 衡量)。
(b):不同尺寸 Decoder 的重建效果对比 (以 rFID 衡量)。
(c):不同尺寸 Encoder 的重建效果对比 (以 rFID 衡量)。
(d):不同 Representation Encoder 的表征质量对比 (以 linear probing 精度衡量)。

图2:RAE 无论在重建能力以及表征质量上都强于 SD-VAE
从重建能力来看,不同模型的 RAE 都比 SD-VAE 强点,也挑战了 "Representation Encoder 不能恢复像素级细节" 的假设。
从表征质量来看,对比了 ImageNet 的 linear probing 精度,RAE 用的就是冻结的 Representation Encoder 的表征,因此,就直接继承这个表征。RAE 因为是继承 Representation Encoder 的表征,因此展示出很强的表征。相比之下,SD-VAE 精度仅仅只有约 8%。
1.3 用 RAE 可以直接就把 DiT 训练好吗?
要评价一个 AE,主要看两个东西:
其一是**重建能力 (Reconstruction capability),即其恢复精细的图像细节的本领。
其二是生成质量 (Generation capability)**,也可以称为 Diffusability,即:用了你这 AE 之后,中间的 Diffusion Model 有多容易建模?生成能力又能够达到多少?
重建能力上一节中已经做了实验对比,这里作者继续研究生成能力。
-
训练目标:Flow Matching。
-
Sampler:Euler Sampler,50 steps。
-
评价指标:ImageNet 256×256,50K samples 的 FID 结果。
用 RAE 直接训练 DiT 的结果怎样呢?
答案是:不 work。
结果如下图 3 所示,小一点的模型 DiT-S 失败地很彻底,而大一点的模型 DiT-XL 的性能也大大落后于竞争对手 SD-VAE 的 latents。
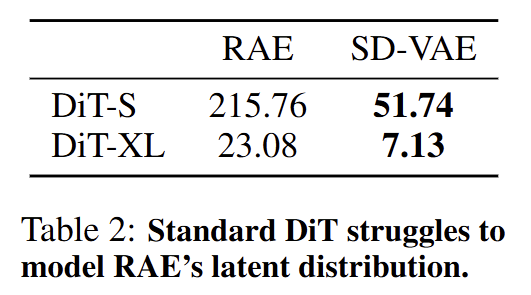
图3:RAE 直接来训 DiT 不 work
作者把训练失败的原因归结为下面3点:
-
DiT 的设计不行:标准 DiT 是为 low-dimensional VAE token;但是现在建模的是 high-dimensional RAE token。那这个设计可能要改改。
-
噪声调度算法不行:之前的噪声调度算法是为 VAE token 设计的,可能不适用于现在的语义信息丰富的 RAE token。
-
RAE Decoder 是在干净的 latent 上训练,没噪声。在面对去噪任务的时候可能还要考虑一个泛化性的问题。
1.4 怎么用 RAE 训练 DiT?
针对于上面的这几个思考,作者逐一进行分析:
结论一:DiT 的宽度要大于等于 RAE token 的维度。
首先,作者只随机选了一张图片,使用 RAE 编码,然后过拟合这个图片。结果令人出乎意料:
如图 4 所示,固定模型深度,当模型宽度比较低时,采样质量就不行。但是当宽度增加时,采样质量在上升,直到增加到 768 (token dimension)。
固定模型宽度,当模型深度增加时,没用。
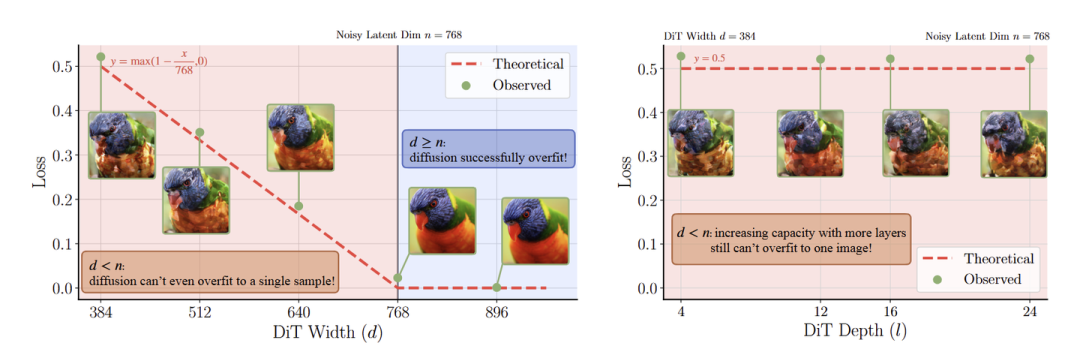
图4:过拟合单张图片实验。左:增加模型宽度可以有效降低 Loss,并提升采样质量;右:增加模型深度没用
这个结果说明,要想在 RAE 的 Latent Space 做生成,那么扩散模型的宽度至少需要达到 RAE 的 token dimension (比如图 3 的 768)。
这个结论乍一看上去,与我们常见的认知是相反的。常见的认知是:数据一般分布在高维空间的低维流形上面。所以呢,生成模型只需要在一个相对较低的维度上进行建模即可。
但是本文作者认为:
一旦数据中加了噪声,那么数据的分布就改变了,就从原来的低维流形 "扩散" 到了整个的高维空间中。因此,就需要我们的扩散模型的 capacity 随之增加,也就是变得更宽。
关于这里,给了个理论指导:

作者又继续做了个过拟合实验,使用 \{DiT-S,DiT-B,DiT-L} 三种不同宽度模型, 分别过拟合到 \{DINOv2-S,DINOv2-B,DINOv2-L} 提取的单图片特征。结果如下图 5 所示。只有当模型宽度大于等于 token dimension 时候,训练才可以收敛。反之,则不会收敛(比如 DiT-S +DINOv2-B)。

图5:过拟合的损失
结论二:噪音调度的范式:依赖于有效数据维度。
本文认为 SD3 的 timestep shifting schedule 应该与有效数据维度(token number token dimension)相关:
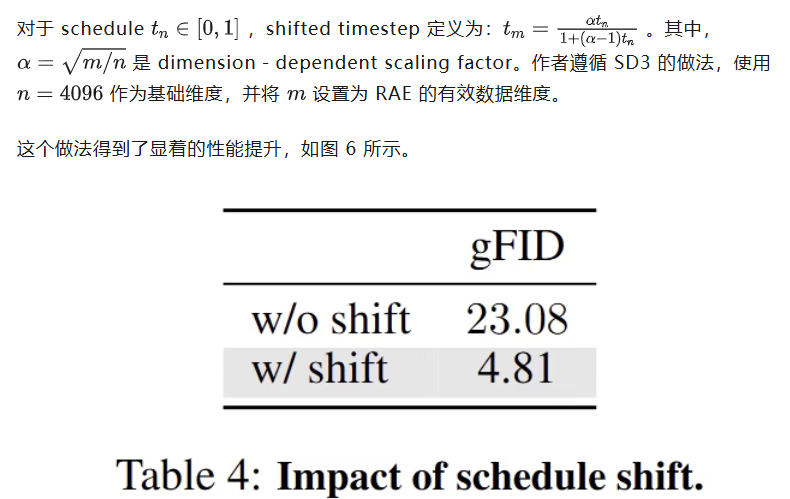
图6:schedule shift 的影响
结论三:使用噪音增强解码。

这个结果也比较符合预期:加点噪声会一定程度解决 Out-of-distribution 问题,但也会削弱细节,弱化重建。
然后,把以上所有的技术整合起来,在 RAE 的 Latents 上训练 DiT-XL。如下图所示,gFID 达到了 4.28 (80 epochs) 和 2.39 (720 epochs)。这个结果超过了在 VAE Latents 上训练的 SiT-XL,也超过了表征对齐方法训练的 REPA-XL。
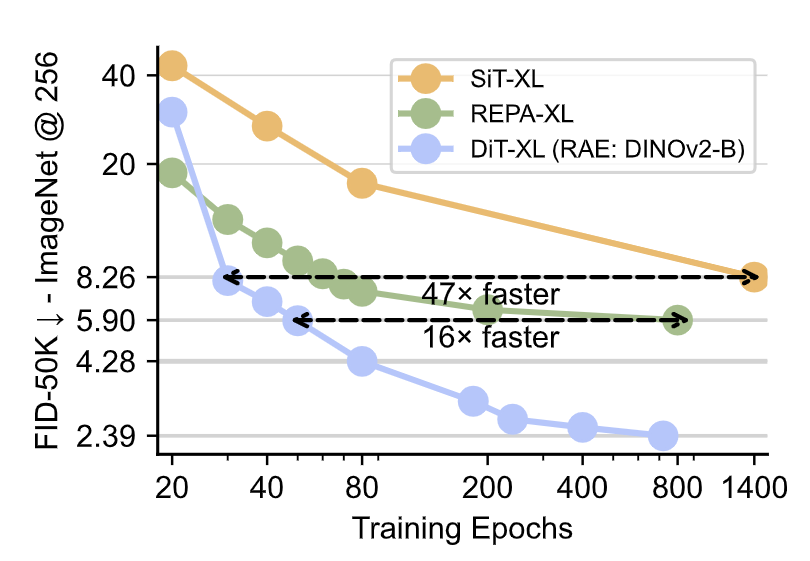
图8:RAE 实验结果,比 SiT 或者 REPA 收敛速度更快
1.5 用一个宽的 DDT Head
根据结论一,当 RAE 的 token dimension 很大的时候,那么 Backbone 的宽度也要增加。因此,计算量也上去了。为了解决这问题,RAE 模仿 DDT 的做法,使用一个比较窄的 DiT ,串联一个层数不多但比较宽的 Head (2层, 2048 dimension)。示意图如下图 9 所示。
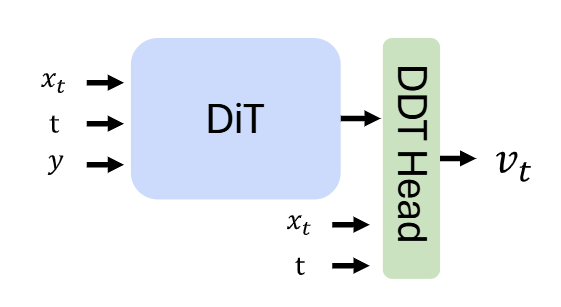
图9:宽的 DDT Head
实验结果如下图 10 所示:
(a):使用宽 DDT Head,相比不使用,收敛更快。
(b):使用宽 DDT Head,相比基于 VAE 的方法,收敛更快。
(c):使用宽 DDT Head,相比基于 VAE 的方法,在不同的 model scales 实现了更好的 FID。
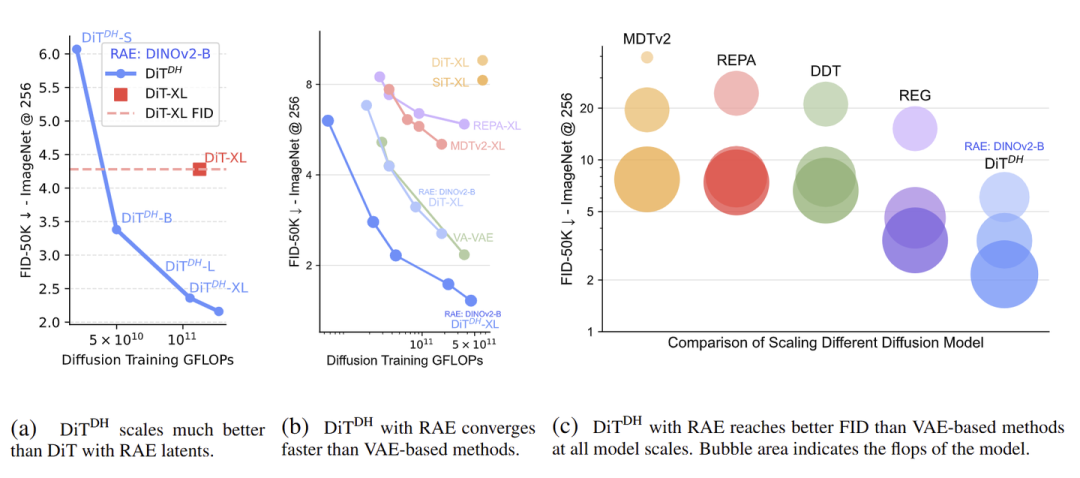
图10:使用宽的 DDT Head 的 Scalability
1.6 与 state-of-the-art 扩散模型对比
作为一种提出新的生成范式的文章,一个重要的实验结果应该是 ImageNet Class-conditional 图像生成的实验。老规矩,RAE 也在 ImageNet 256×256 和 512×512 上对比了其他类似的方法。
DiT (DH)-XL 使用 DINOv2-B 作为 Encoder,训练 80 epochs,不使用任何 guidance,FID 能够达到 2.16;训练 800 epochs,不使用任何 guidance,FID 能够达到 1.51;训练 800 epochs,用了 guidance,FID 达到了 1.13。
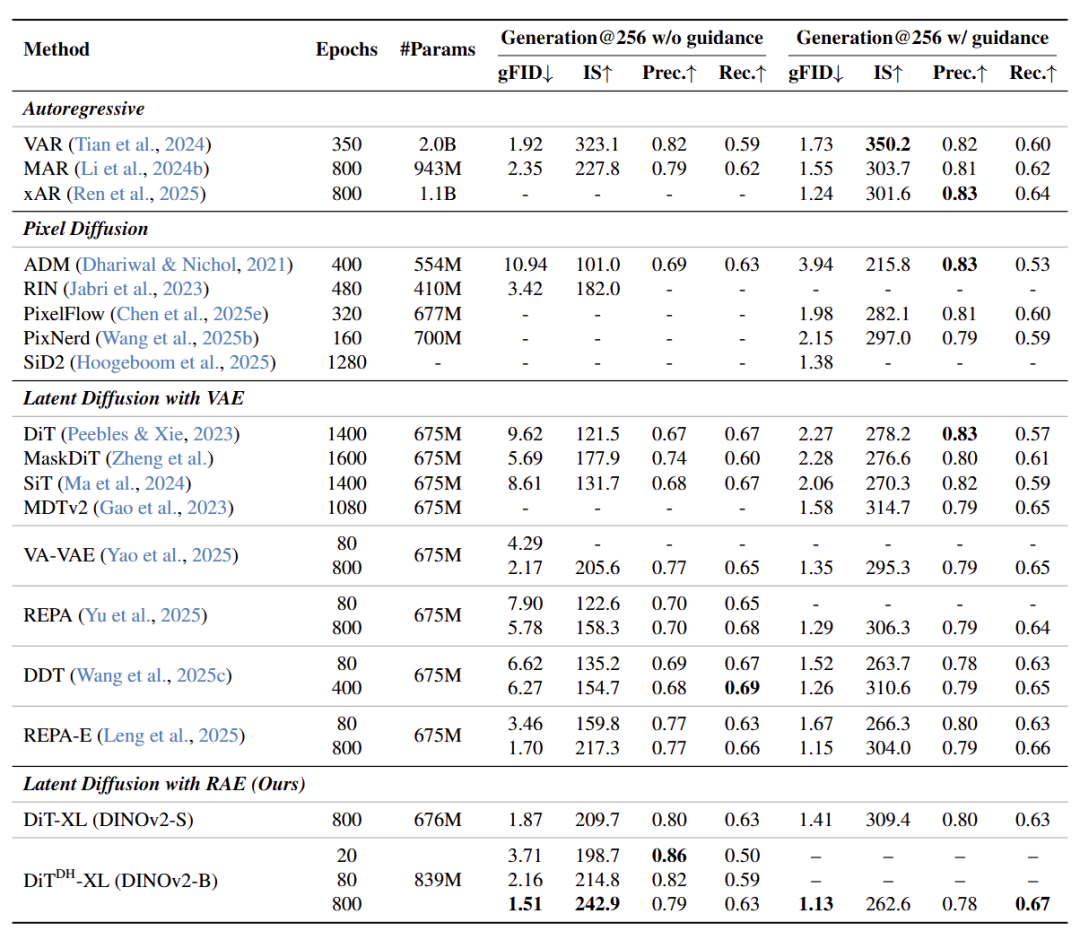
图11:ImageNet 256×256 Class-conditional 图像生成实验结果
512×512 的结果也很棒。DiT (DH)-XL 使用 DINOv2-B 作为 Encoder,训练 400 epochs,使用 guidance,FID 能够达到 1.13。
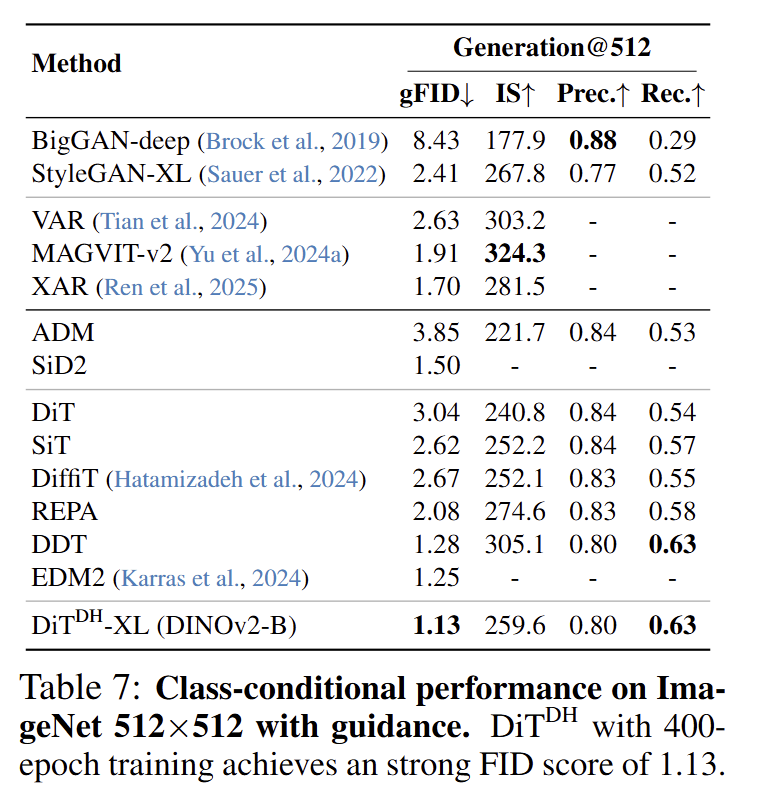
图12:ImageNet 512×512 Class-conditional 图像生成实验结果
采样结果如图 13 所示。

图13:定性的采样结果,来自 512×512 模型,使用了 AutoGuidance
1.7 讨论部分
接下来,作者关于 3 个问题做了一些讨论。
首先是如何把 RAE 高效迁移到高分辨率。token 数目与分辨率有关。作者的做法是,让 。这样假如说是 256 token,输入分辨率 ,那么输出分辨率就是 。就相当于是上采样 2 倍。
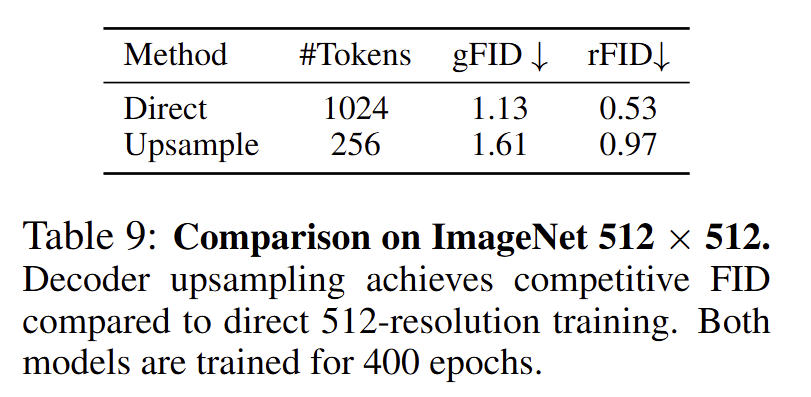
图14:ImageNet 512×512 结果
一种简单的做法是,重用 256×256 训练的 DiT,然后通过一个上采样 Decoder 得到 512×512 的输出,结果如上图。这种做法 gFID 差不多可以保持,但是 token 数只是原来直接训练的 1/4,比较高效。
其次是如果不使用 RAE,那使用了宽 DDT Head 的 DiT (DH) 是不是还 work?为此,作者做了下面这个实验:在 SD-VAE latents 上训练 DiT-XL 和 DiT (DH)-XL。结果显示如果使用 SD-VAE latents,使用了宽 DDT Head 的 DiT (DH) 还不如原始的 DiT。这说明如果 Latents 的维度比较低,那么宽的 Head 不起作用。只有在 Latents 维度比较高的时候 (比如 RAE 的情况),才起作用的。
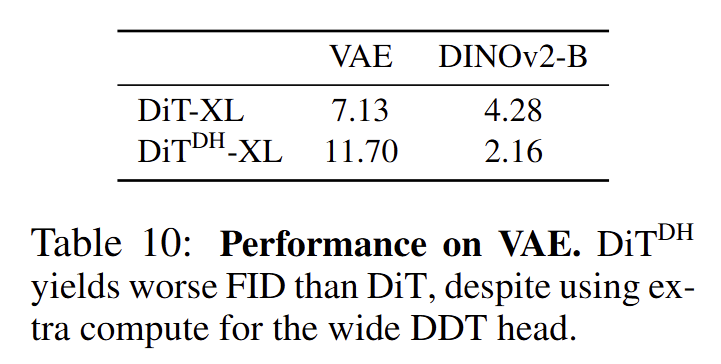
图15:VAE 性能
最后一个问题是:DiT (DH) 在高维度特征上很 work,那这个性能是由于 RAE 本身带来的,还是随便一个高维特征 (比如 raw pixels) 都可以?为此,作者直接在 raw pixels 上训练 DiT-XL 和 DiT (DH)-XL。
假设图是 256×256,patch size 是 16,那么刚好 DiT 的输入 token dimension 也是 16×16×3=768。DiT (DH) 表现稍微好一点。但是 Pixel 的结果都是不如 DINOv2-B 的结果的。这说明仅仅高维度特征是不够的,RAE latents 同样重要。
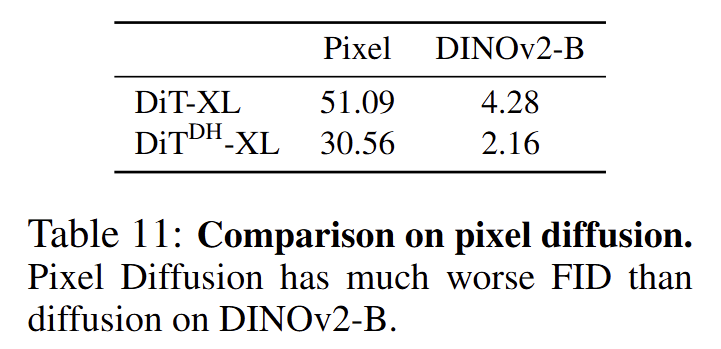
图16:raw pixel 结果对比
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









