




✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
本文所有资源均可在该地址处获取。
概述
相关背景
语言模型:语言模型是指对于任意的词序列,它能够计算出这个序列是一句话的概率。
预训练:预训练是一种迁移学习的概念,指的是用海量的数据来训练一个泛化能力很强的模型
微调:微调(Fine-tuning)是指在预训练模型的基础上,针对特定任务或数据领域,对部分或全部模型参数进行进一步的训练和调整
Transformer:
BERT是基于Transformer实现的,BERT中包含很多Transformer模块,其取得成功的一个关键因素是Transformer的强大作用。BERT仅有Encoder部分,因为它并不是生成式模型。Transformer个模块通过自注意力机制实现快速并行,改进了RNN最被人诟病的训练慢的缺点,并且可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
Transformer首先对每个句子进行词向量化,进行编码,再添加某个词蕴含的位置信息,生成一个向量。而后通过Attention算法,生成一个新向量,这个新向量不仅包含了词的含义,词中句子中的位置信息,也包含了该词和句子中的每个单词含义之间的关系和价值信息。这种方法突破了时序序列的屏障,使得Transformer得到了广泛的应用。
BERT的优势
1、作为一种预训练模型,在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效,泛化能力较强。
2、Bert是一种端到端(end-to-end)的模型,不需要我们调整网络结构,只需要在最后加上特定于下游任务的输出层。
3、基于Transformer,可以实现快速并行,也可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
4、和ELMO,GPT等其他预训练模型相比,BERT是一种双向的模型,结合上下文来进行训练,具有更好的性能。
BERT和传统nlp相比的特点
1.更好的语义理解能力
传统的自然语言处理工具只能从字面意义上进行文本分析,无法理解句子的含义和上下文。而BERT模型是双向的,可以同时考虑句子左右两侧的上下文信息,从而更好地理解句子的含义和语境。因此,在对话系统、文本分类等领域中BERT模型的表现更加优秀
2.更好的文本预训练能力
BERT是基于预训练的模型,使用了大型无标注语料库进行训练。由于BERT训练时使用了大量的语料库。因此具有更好的泛化能力和适应性,可以适应不同的自然语言处理任务。
3.可拓展性强
BERT采用Transformer结构,使得模型可以轻松地进行拓展。可以通过增加层数、增加训练数据等方式来提高模型的性能。因此,BERT模型在对新领域的应用中具有很大的潜力。
4.更好的效果
针对一些自然语言处理领域的任务,BERT模型的表现要优于其他传统的自然语言处理模型。例如,BERT在文本分类任务中表现出的效果比传统的卷积网络和循环神经网络要好,在当前的文本分类领域中有着广泛的应用。
BERT的应用领域
BERT作为一个预训练模型,能够通过适当的数据集进行微调,使得它能够胜任自然语言处理领域的多种任务,比如情感分析、摘要、对话等任务。
模型架构
BERT的模型架构是基于多层双向Transformer编码器。具体的,Google提供了一大一小两个BERT模型:
BERT_Small(L=12,H=768,A=12,总参数=110M)
BERT_Large(L=24,H=1024,A=16,总参数=340M)
输入输出表示
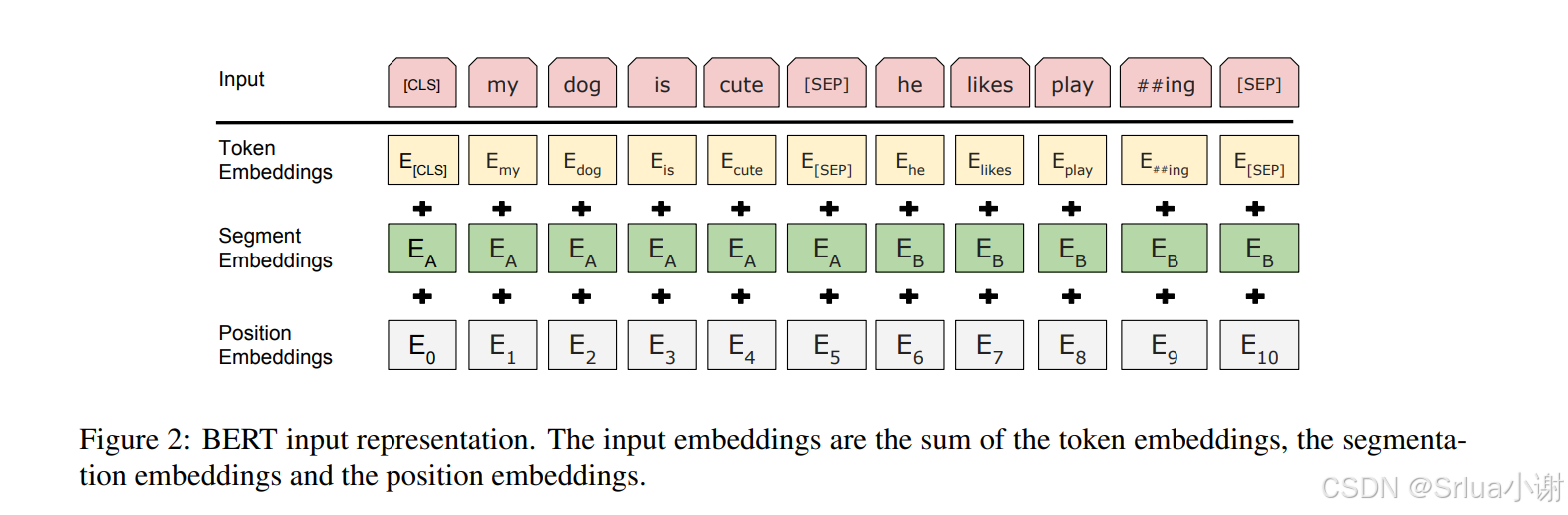
为了使BERT能够处理各种下游任务,输入表示能够明确表示单个句子和一对句子(例如,〈question,answer〉)在一个标记序列中。
BERT的输入由三部分组成:
Token Embeddings:使用具有30,000个标记词汇表的WordPiece嵌入。每个序列的第一个标记始终是一个特殊的分类标记([CLS])。对应于此标记的最终隐藏状态用作分类任务的聚合序列表示。
Segment Embeddings:用于区分两个句子。通过两种方式区分句子:1.用一个特殊标记([SEP])将它们分开。2.为每个标记添加一个学习的嵌入,指示它属于句子A还是句子B。
Position Embeddings:位置编码,transformer没有捕捉位置信息的能力,所以需要额外的位置编码,这里没有使用transformer论文中的正弦位置编码, 而是采用了learned positional embeddings。
将BERT的输入表示可视化如下:
BERT预训练任务
使用两个无监督任务来预训练BERT,包括MLM和NSP。
MLM掩码语言模型
直观来看,深度双向语言模型当然比单向的从左到右或者从右到左模型更有效。但不幸的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件将允许每个单词在多层上下文中间接 “看到自己”。
为了训练一个深度双向表示,Google学者简单地随机掩盖一定比例的输入标记,然后预测这些被掩盖的标记,这个过程称为“掩码语言模型”(MLM),也就是类似于完形填空任务。
但这种办法存在两个问题:
1.在预训练和微调之间导致了不匹配,因为[MASK]标记在微
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









