




✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙


目录
论文 BM3:Bootstrap Latent Representations for Multi-modal Recommendation 复现与解析
多模态推荐系统 (Multi-modal Recommendation System)
自监督学习 (Self-supervised Learning)
本文所有资源均可在该地址处获取。
论文 BM3:Bootstrap Latent Representations for Multi-modal Recommendation 复现与解析
论文链接
此论文由WWW在2023年发表———BM3:Bootstrap Latent Representations for Multi-modal Recommendation
多模态推荐系统 (Multi-modal Recommendation System)
什么是多模态推荐系统?
多模态推荐系统是一种利用多种不同类型的数据源(例如文本、图像、视频、音频等)来进行推荐的系统。传统的推荐系统通常只依赖于单一模态的数据,例如用户的评分或点击行为,而多模态推荐系统则结合了来自多个模态的信息,从而可以提供更准确和个性化的推荐。
优点
- 提高推荐准确性:通过结合多种数据源,可以更全面地了解用户的偏好。
- 丰富的用户体验:多模态数据可以为用户提供更多样化的推荐内容。
- 处理冷启动问题:在用户数据不足的情况下,可以利用其他模态的数据进行推荐。
示例
假设我们有一个电商平台,用户在平台上浏览和购买商品。我们可以使用以下多模态数据来构建推荐系统:
- 文本:商品的描述和用户的评论。
- 图像:商品的图片。
- 行为:用户的点击和购买记录。
对比学习 (Contrastive Learning)
什么是对比学习?
对比学习是一种自监督学习的方法,通过学习样本之间的相似性和差异性来学习数据的有用表示。目标是使得相似的样本在表示空间中更接近,不相似的样本更远离。
关键思想
- 正样本对 (Positive Pairs):具有相似特征的样本对。
- 负样本对 (Negative Pairs):具有不同特征的样本对。
- 损失函数:通过最小化正样本对之间的距离,最大化负样本对之间的距离来训练模型。
优点
- 无需大量标注数据:对比学习可以在无监督环境中工作。
- 提升特征表达能力:通过对比学习,模型可以学习到更有辨别力的特征。
自监督学习 (Self-supervised Learning)
什么是自监督学习?
自监督学习是一种无监督学习的方法,通过生成伪标签来进行训练。模型利用自身的数据生成训练信号,而不是依赖外部的标签数据。自监督学习的目标是通过设计预训练任务,使模型能够学习到数据的有用表示。
优点
- 减少对标签数据的依赖:不需要大量的人工标注数据。
- 学习到通用特征:通过预训练任务,模型可以学习到适用于多个下游任务的通用特征。
实现自监督学习的方法
常见的自监督学习方法包括:
- 图像领域:通过图像旋转、遮挡、拼图等任务来生成伪标签。
- 文本领域:通过词汇预测、句子排序等任务来生成伪标签。
论文问题提出
- 除了用户-项目交互图之外,现有的最先进的方法通常使用辅助图(例如,用户-用户或项目-项目关系图),以增强所学习的用户和/或项目的表示。这些表示通常使用图卷积网络在辅助图上传播和聚合,这在计算和存储器方面可能非常昂贵,特别是对于大型图。
- 现有的多模态推荐方法通常利用贝叶斯个性化排名(BPR)损失中随机抽样的否定示例来指导用户/项目表示的学习,这增加了大型图上的计算成本,并且还可能将噪声监督信号带入训练过程。
解决方案
自监督学习的应用:
BM3 提出了一个新的自监督学习模型,不需要使用负样本或复杂的图增强技术。这简化了现有的自监督学习框架,减少了模型参数。
Dropout 增强机制:
通过 dropout 增强生成用户和项目的对比视图,而不是通过图或图像增强。这种设计减少了内存和计算成本。
多模态对比损失函数:
设计了一个专门用于多模态推荐的对比损失函数,该函数在重建用户-项目交互图的同时对齐不同模态之间的特征,并减少来自同一模态的不同增强视图之间的差异。
框架图
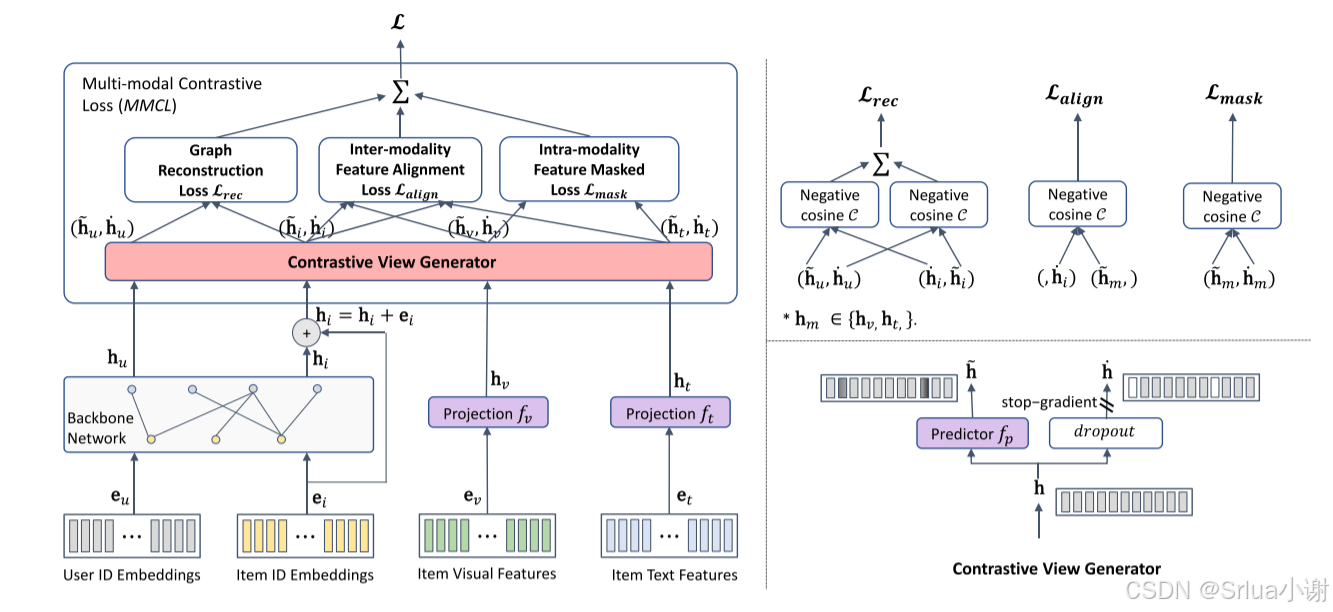
该框架图展示了BM3模型的结构,包括几个关键部分。首先是"Backbone Network"(骨干网络),它接收用户和物品的ID嵌入,并生成初始嵌入表示 huhu 和 hihi。然后,这些嵌入与物品的视觉特征和文本特征通过投影网络 fvfv 和 ftft 进行处理,生成图像和文本的嵌入表示 hvhv 和 htht。接下来,“Contrastive View Generator”(对比视图生成器)通过增强技术生成这些嵌入的对比视图(例如 h~uh~u、 h~ih~i、 h~vh~v、 h~th~t),并应用于三个损失函数。“Graph Reconstruction Loss” LrecLrec 通过对比用户和物品嵌入及其对比视图来增强嵌入表示的鲁棒性和泛化能力;“Inter-modality Feature Alignment Loss” LalignLalign 通过对比不同模态(例如图像和文本)的嵌入和对比视图,促进跨模态的一致性;“Intra-modality Feature Masked Loss” LmaskLmask 通过对比同一模态内部的嵌入和对比视图,进一步增强单模态的鲁棒性。最终,这些损失函数的加权和形成了整体的多模态对比损失 LL,优化模型以提升推荐系统的性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1153
1153



 到【灌水乐园】发言
到【灌水乐园】发言








