



1.背景介绍
根据贝叶斯概率论从有噪图像Y恢复无噪图像X可以视为条件概率模型p(Y|X)与p(X)的建模问题,因此图像降噪作为一个典型的病态求解问题需要引入先验信息或者假设模型p(X)。
我们可以将降噪方法大体分为外部先验和内部先验方法:外部先验方法主要通过学习外部干净图像数据集的固有属性指导噪声图像降噪,如学习干净图像的字典或先验高斯混合模型,另外基于深度学习的方法也可以归纳于此。而内部先验方法主要依赖于如低秩、稀疏、自相似等图像内部特征,如KSVD、WNNM、BM3D、NLM等方法。
外部先验学习到的图像性质应用在噪声图像存在适应性不足问题,而内部先验如自相似方法随着噪声水平的升高效果也会下降,后续也有很多利用图像外部先验信息和内部自相似性质结合的内外先验结合方案去提升降噪质量如PCLR。整体上这类建立假设模型的算法通常会建立约束方程,并通过如梯度下降或者最小二乘的优化方法进行最优预测值的求解,算法存在较大的性能开销,通常这类方案很难具有实时性。
本文会基于时间线,从图像平滑性约束、稀疏性先验假设、低秩性先验假设以及多种先验假设混合的建模方案进行算法介绍。实际上会发现这几类算法的出发点或者理论上十分相通,只是通过数学游戏做了不同的变形,并且最终都会走向多个假设和约束结合的方式。
2.全变分降噪(TV)
参考论文:Nonlinear total variation based noise removal algorithms
推导和参考代码:https://blog.youkuaiyun.com/weixin_45682889/article/details/105310639
与以往的去噪算法不同,TV算法是一种图像复原算法,它是将干净的图像从噪声图像中复原出来,这有些类似维纳滤波。通过建立模型约束去噪图像 u 与噪声图像u0差异尽量小,边缘轮廓尽量保持,同时也要让图像内部尽量平滑达到降噪的目的。
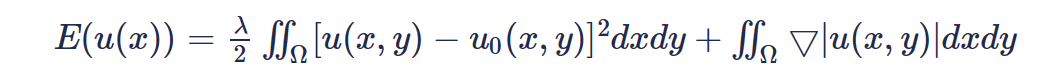
约束方程第一项视为保真项保持结构信息,降噪前后图像全局的结构、边缘等主要成分不能有太大变动。第二项视为正则项,图像大部分成分都是低频的,所以理论上无噪声图像应该梯度很小。因此实际上λ控制第一项结构约束的力度,越大代表保证项成分越高,希望保留图像的结构成分越完好;越小则增加了表达式正则项的含量相对增多,代表希望图像的平滑性更好。

20轮迭代结果对比
由于约束使用的L1范数存在非线性和计算复杂等问题,求解时需要通过不断迭代,使得复原出的图像无限逼近理想去噪后的图像。与深度学习十分类似,约束函数类比于损失函数,通过不断训练,使得两者的差距越来越接近,同样需要梯度下降法快速得到最优解。
针对泛函数 E(u(x)) ,经典的求解方式就是欧拉-拉格朗日方程:
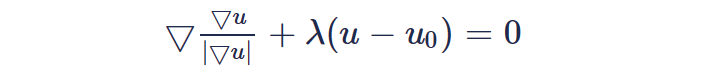
通过梯度下降结合有限差分的思想迭代求近似解:
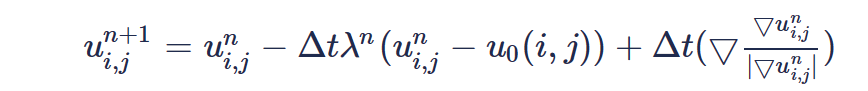

20轮迭代效果对比,此时基本迭代效果比较稳定
该算法优点是允许出现尖锐的不连续点,如边缘轮廓或运动的边界,这些边缘都代表重要的特征,采用此方法可以很好的保护边缘。TV方法在细节纹理的恢复以及低频区域的平滑较维纳滤波有着明显的效果提升。

但 TV 方法会产生阶梯效应,即平滑区域出现一些成分段常数区域,并且还是会丢掉纹理等细节特征。论文最后认为再去噪过程中如果能加入更多的约束(关于噪声和图像的先验信息),去噪结果中将产生更多的细节。
3.加权最小二乘滤波(WLS)
参考论文:Edge-Preserving Decompositions for Multi-Scale Tone and Detail Manipulation
参考代码:https://blog.youkuaiyun.com/u014230360/article/details/107639764
如第二节全变分降噪的思想,如果要设计一个保边的滤波器,我们即希望降噪后的图像 u 与原始图像 g 尽可能相似,另外边缘梯度变化大的地方也希望尽可能平滑:
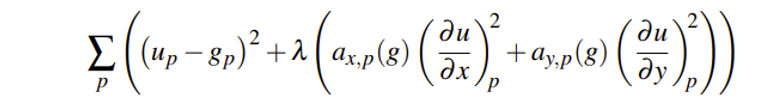
用矩阵的形式表达上述约束方程, Dx 和 Dy 是离散差分算子,Ax 和 Ay 是平滑对角矩阵:
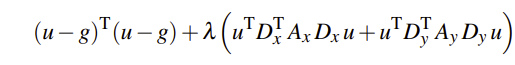
要求能使约束方程极小值时对应的降噪后图像,通过令求导结果为0即可:
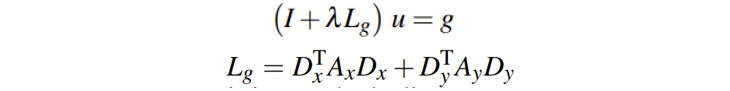
这里平滑对角矩阵和λ是一个外部控制降噪程度的变量,这篇文章将对角矩阵设计成:
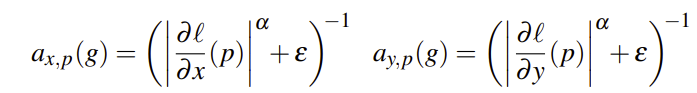
在论文中 l 是输入的log域表示形式,当图像梯度比较大的时候平滑项系数 Ax和 Ay就会做一定的衰减,避免边缘区域平滑的太严重。

加权最小二乘滤波的实时性会优于全变分,但在调试参数到相同的降噪力度下,看起来全变分的清晰度会优于加权最小二乘滤波:

除了图像去噪,WLS在HDR、图像增强、tonemapping等领域也有广泛应用。
4.K-SVD
参考论文:An Implementation and Detailed Analysis of the K-SVD Image Denoising Algorithm
参考代码:GitHub - nel215/ksvd: A ksvd implementation written in python.
在过去几十年内,去噪算法中主成分分析方法发展迅速。离散傅里叶和小波这样的方法获得的是一系列正交基,对于方差较小的噪声,因为无噪声图像本身的变换系数主要集中在低频区域,并且具有较大的幅度,而噪声在变换域中由于方差较小的缘故,通常只有较小的值(例如 95.4% 的值都在两个标准差的范围内),我们可以通过设定阈值的方法(一般为 2~3 个噪声标准差),只保留有噪声图像的变换系数中那些具有较大幅度的值,其他的则置零,绝大部分的噪声的变换系数就得以消除。
稀疏表达的思想和频域去噪的思想很接近:图像可以通过几个主要成分(字典原子)线性叠加而成,而随机噪声是不可稀疏的无法用一些基底构造出来。因此用稀疏成分分解并重构图像,前后过程残差就对应噪声成分并被抛弃。不过稀疏表达获得的“字典原子”是一些列非正交基,因为正交基往往只能表示图像的某一个特征而不能够同时表示其他特征,因此正交基的稀疏性不及非正交基。
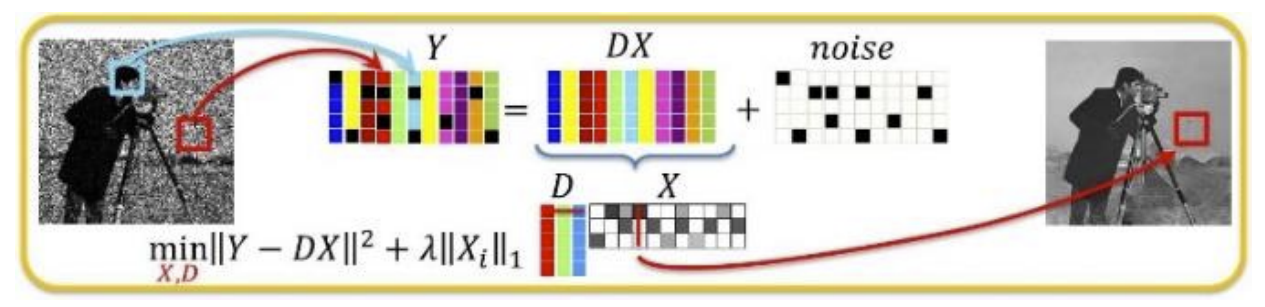
设噪声图像为y,我们希望在包含不同基底的字典D中,选择需要的成分通过系数x把基底加权,来尽可能还原噪声图像。同时我们也希望x中非零元素要尽可能的少,用更稀疏的系数x去做图像表达:
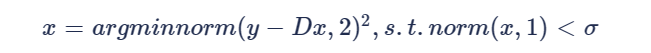
观察上式可以看到D和x都不知道,优化该方程属于NP难问题。不过可以知道的一点是x越稀疏求解将越精确,我们可以尝试利用OMP算法,计算得到字典D和稀疏编码矩阵x。
在进行优化前我们对y做一个变换,把图像拆分成n个块,将patch拉平成一列作为样本数据并组成样本集矩阵。这时图像变成了m*n的尺寸,m代表每个patch的像素数,n代表patch数量。图像的第j个patch(列)就可以看成是通过系数矩阵K*n的第j列系数,对m*K的字典矩阵的K个原子基进行加权得到的:
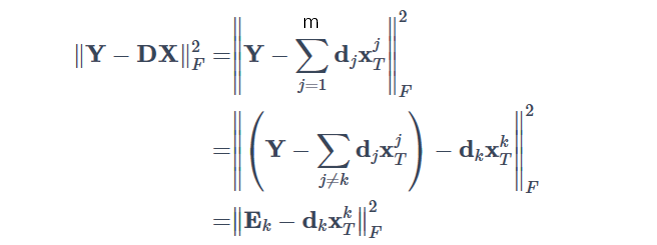
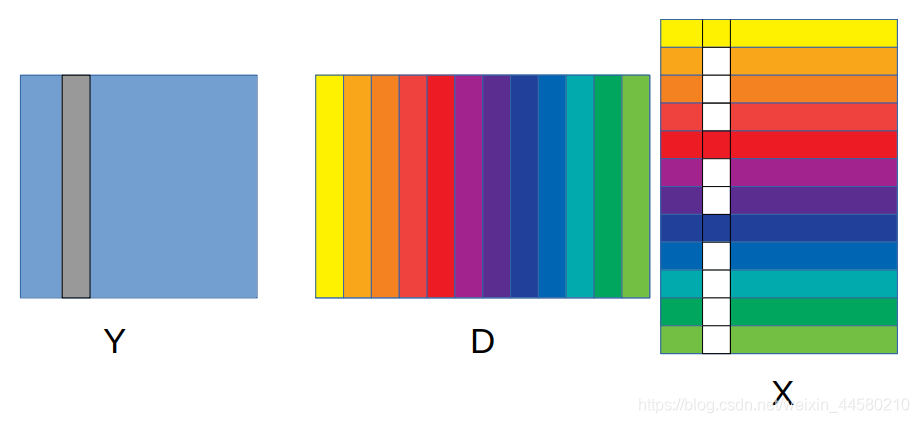
预先对D和x进行初始化给定初值,这里可以直接对噪声图像做个奇异值分解得到字典和系数的初值。首先把字典D的第k行提取出来,把最小化方程构造成了一个类似最小二乘求解的形式,通过迭代的方式逐行去更新字典。在每一轮迭代中通过对 Ek 进行SVD分解就可以得到第k行字典和更新一次稀疏矩阵x:
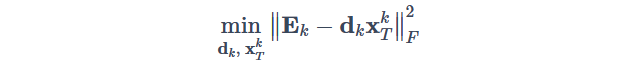
为了保持稀疏性,上一轮迭代中稀疏矩阵x中为0的系数就保持为0,这样每轮迭代中x中非零系数最起码不会再增加。实际做法会把当前x中为零的系数和Ek 中对应参与运算的向量都剔除掉,再进行SVD分解求解d和x。
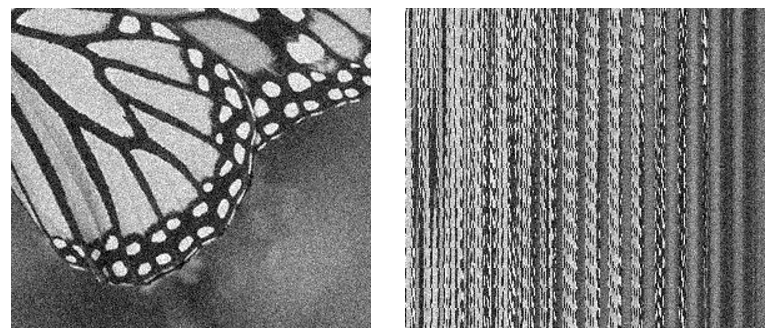
实验中把256*288的图片以16*16的patch进行拆分,重构得到原始尺寸256*258的列展开图像进行训练,分别设置字典原子个数90、60、30,进行100次迭代后效果如下:
可以看到随着表达图像的原子个数下降,表达基底的稀疏性越强,降噪力度也就越明显。但同时发现清晰度也明显下降,说明字典并没有把噪声和原始信号的特征区分出来,导致细节和噪声混在一起被保留或去除。猜测可能训练字典的数据仅依赖一张原始图像数据,并不能很好的表达图像的特征。
5.WNNM
参考论文:Weighted Nuclear Norm Minimization with Application to Image Denoising
参考代码:https://github.com/csjunxu/WNNM_CVPR2014/blob/master/Demo.m
从降噪的本质上来说,稀疏表达的稀疏性和低秩聚类是比较相关的,有学者证明了自然图像中非局部相似块形成的矩阵具有低秩性,并且具有稀疏的奇异值。因此对于噪声图像我们可以利用低秩性质求解近似的无噪图像。在低秩聚类相关算法中,图像中相似的patch组成而成的3D group具备低秩性,而噪声则不具备低秩性质,因此通过低秩聚类可以对图像进行去噪任务。
低秩矩阵近似方法一般可分为低秩矩阵分解LRMF方法和核范数最小化NNM方法:LRMF的目标是找到一个矩阵X在一定的数据保真度函数下尽可能接近Y,同时能够分解到两个低秩矩阵的乘积中,此方法是一个非凸优化问题。NNM是具有一定数据保真度项的非凸LRMF求解方案,它是严格的凸松弛。
接下来就是数学上如何求解,设观测矩阵为Y(噪声图像相似patch的3D group),λ是一个常数控制系数。对于低秩矩阵X通过NNM方法求解,第一项为保真项计算噪声样本和无噪声预测值的F范数(各元素平方和),而第二项核范数(奇异值之和)为低秩假设,保证图像的低秩性:
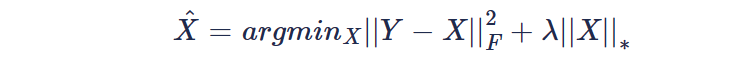
Y经过奇异值分解,那么X的最优解可以表示为:
![]()
通过奇异值软阈值对所有奇异值系数做衰减保证低秩性:
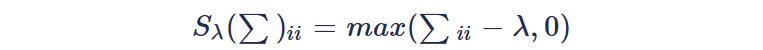
为了追求凸性方便求解,上面的标准核范数对每个奇异值进行同等处理,软阈值以相同的量λ收缩每个奇异值会导致较大的奇异值损失主成分。因此为了提高核范数的灵活性,论文提出了加权核范数,对不同的奇异值取不同的权重,并研究了其最小化求解问题:
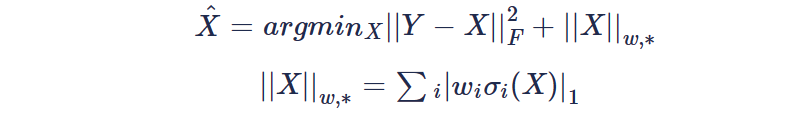
奇异值σ越大,w就会进行衰减
由于大部分情况上述方程并非一个凸优化问题,根据文中的数学推导,首先将Y和X分别进行奇异值分解,中心矩阵分别为Σ和B:
![]()
当权重为非升序排列可以由NNM方法的公式得到全局最优解,当权重为任意顺序排列时,B又被进行一次奇异值分解:
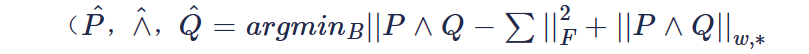
针对正交矩阵P和Q可以通过奇异值软阈值和奇异值分解迭代最终得到X,最后把两次奇异值分解的矩阵叠加回来就复原了预测无噪声图像X:
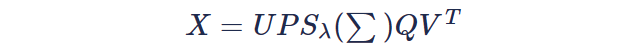
就指标来说WNNM在蝴蝶这组图上PSNR还要高于BM3D,但一次迭代的性能差不多就是BM3D一个初始估计的时间:

6.PCLR
参考论文:External Patch Prior Guided Internal Clustering for Image Denoising
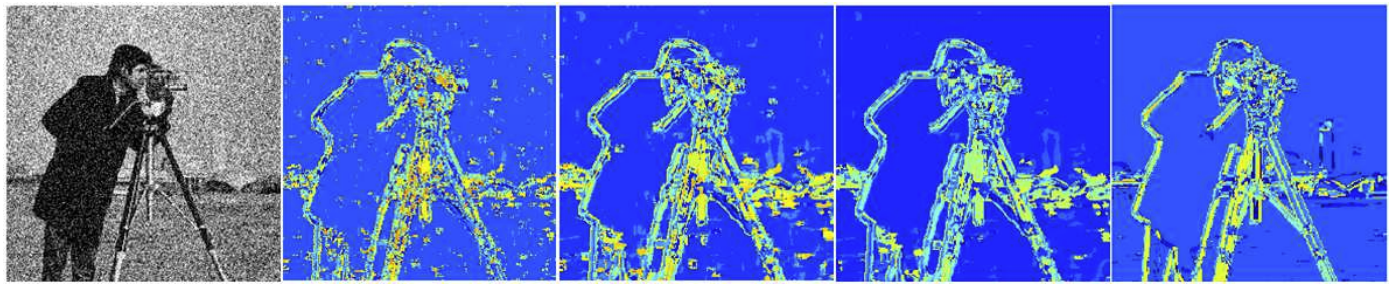
低秩方法如WNNM最小化能量函数,通过奇异值求解得到去噪后的图像。但是这种方法面临两个问题:首先以欧几里得距离作为测量相似块的依据存在漏洞(如下图),另外如何在全局图像高效的得到相似块也是一个问题(相似块越准确降噪效果会有质的飞跃)。
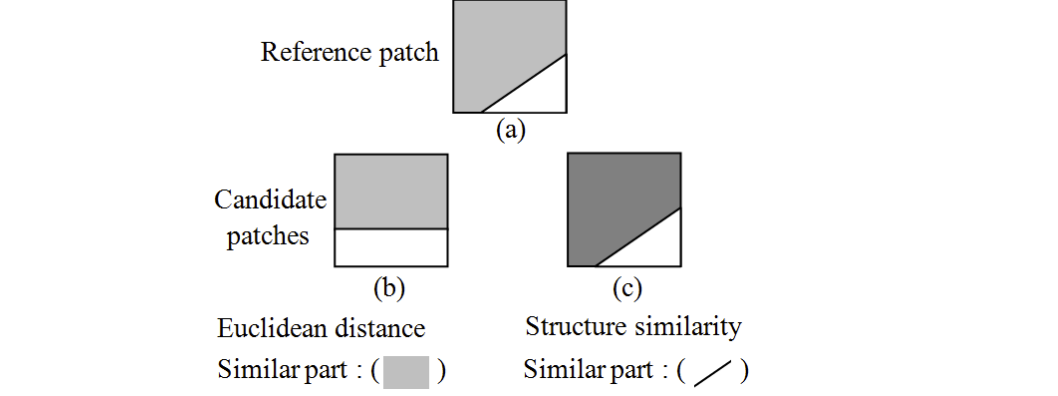
针对这两点作者提出了基于低秩的假设下patch聚类的方法,利用先验高斯混合模型学习外部信息指导内部图像的聚类,然后建立一个关于低秩空间的能量函数并对其约束,最终成功结合了内外先验信息进行图像降噪。
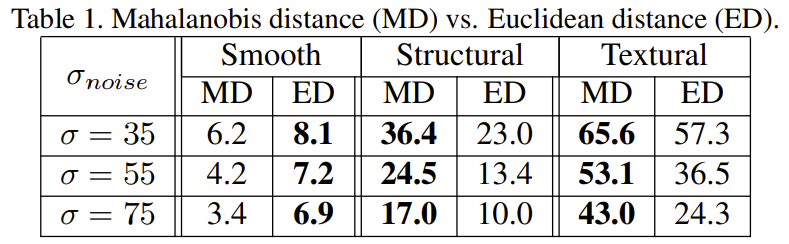
首先针对图像块的相似性,作者提出了用Mahalanobis distance(MD)代替Euclidean distance(ED),为了论证效果将299000个8X8的图像块分为平滑,结构和纹理区域,在不同噪声方差下计算正确的匹配率,结果发现Mahalanobis distance方法更好:
另外针对局部和全局匹配的相似块,同样用低秩去噪算法计算的结果表明全局匹配效果更好。随着匹配精度提高,图像块协方差矩阵的特征值的能量就更加集中在前面的序列:

因此作者基于以上发现提出了基于一系列先验高斯混合模型对图像全局相似块进行聚类的方法。如图所示,不同颜色代表不同聚类,随着迭代的进行无噪图像与有噪图像的聚类逐渐接近。
看到这里其实发现论文目前做的都是一些小的时间换效果的改进,如全局搜索、更复杂的匹配表达式。接下来介绍一下如何用先验信息去指导聚类,首先根据高斯噪声模型,给定噪声图像x预测到无噪声图像y的概率为(噪声值取某个值概率符合高斯分布函数,那么猜对一个值的概率就是高斯分布的概率):
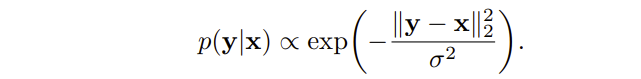
为了使用矩阵分解进行图像块聚类,一种直观方法是使用高斯混合模型(GMM)。假设图像块的潜在结构形成K个低维子空间,图像块 xi 的概率可以假设是K个高斯分布的加权和:
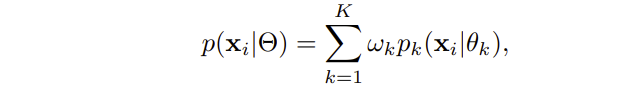
这里 Θ 定义为权重和每个高斯分布的方差均值等参数:
![]()
针对相似patch组成的3D group Rx ,这个聚类中每个patch的标签设为 Ci ,可以得到该聚类块的极大似然表达式,在一系列自然干净图像中可以学习到GMM的参数Θ,这样我们就有了一个无噪声图像的先验表达了:
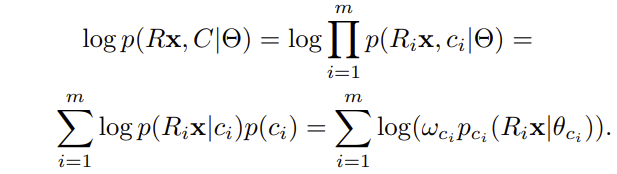
这里我们再结合一下低秩的思想,对要求的理想无噪声信号 Zk 求解。在学习到自然图像指导图像块的匹配,结合低秩降噪算法,就可以通过低秩表达式进行降噪图像求解:
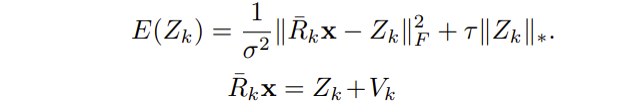
最后建立了一个庞大的拼装约束方程,第一项为保真项:
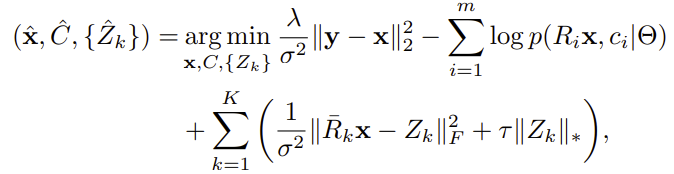


在计算时间上,计算k个聚类中的m patchs,每个patchs是n维的,时间复杂度为O(mkn^3)。 Intel Xeon E3 Cpu(3.40GHz)计算256X256的图像需要接近3分钟。
7.STROLL
参考论文:When Sparsity Meets Low-Rankness: Transform Learning With Non-Local Low-Rank Constraint for Image Restoration
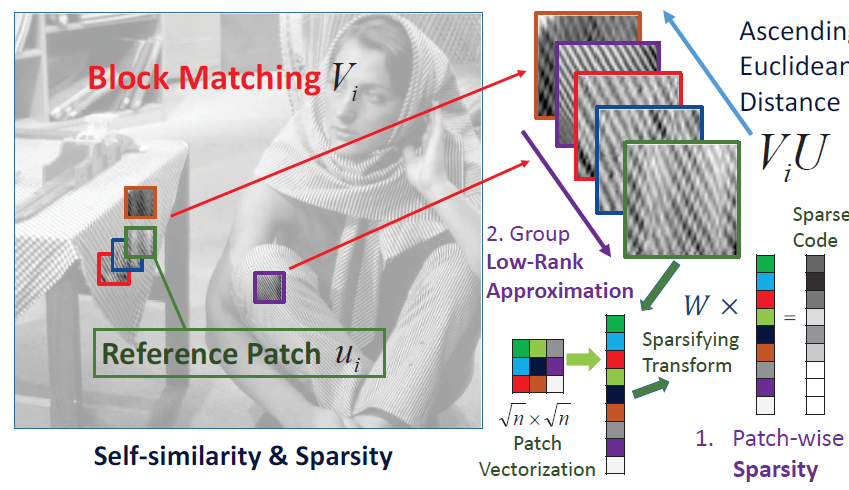
稀疏模型去噪算法中,字典学习的方法中稀疏编码以及迭代过程需要耗费大量时间,而变换域的学习计算时间低,但是这类局部块的稀疏算法都存在局限性。近年来局部稀疏先验和非局部低秩先验都展现着不错的效果,因此作者提出结合变换域图像局部稀疏性和非局部自相似块的低秩性进行图像去噪。
可以看到随着时间线的发展,CV任务想要提点最终都会走向拼装的结局...
如第4节所述,假设变换域的稀疏系数矩阵为W,字典为U,A为预测的降噪结果,E为噪声残差,那么:
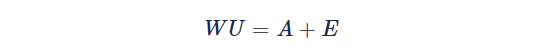
如第五节所述,定义噪声相似块group的稀疏矩阵为 Vi ,那么噪声相似块的预测结果为 Di ,因此可以利用矩阵A的稀疏性和矩阵D的低秩性得到约束方程:
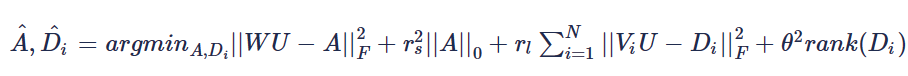
实际上论文还加入了一个保真约束:
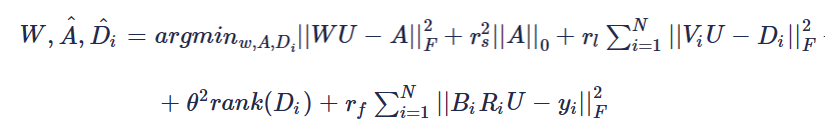
约束方程整体上为一个patch的稀疏表达约束加上一组patch的低秩约束
因此图像复原任务变为求解上述方程组,主要可以通过五步进行:
i)稀疏编码:针对稀疏矩阵的求解可以通过硬阈值进行:
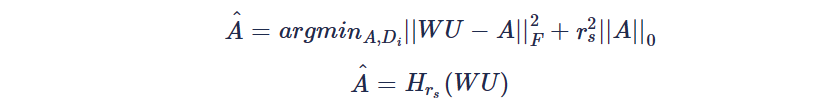
ii)变换矩阵更新:在得到了稀疏矩阵A后,通过SVD方法就能计算W:
iii)低秩矩阵拟合:针对约束方程的第二项,财通奇异值分解同样可以求解D:
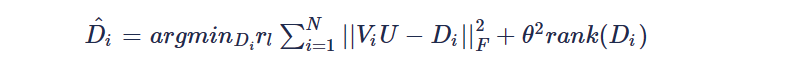
iv)patch恢复:在得到A,W,D后,图像的每个去噪后的patch数据就能得到。
v)聚合:在经过上述迭代后,通过权重分配得到最终去噪后的图像。
在图像复原的过程中,保真项系数B可以控制该算法实现不同功能,主要有图像去噪以及inpaint的效果。
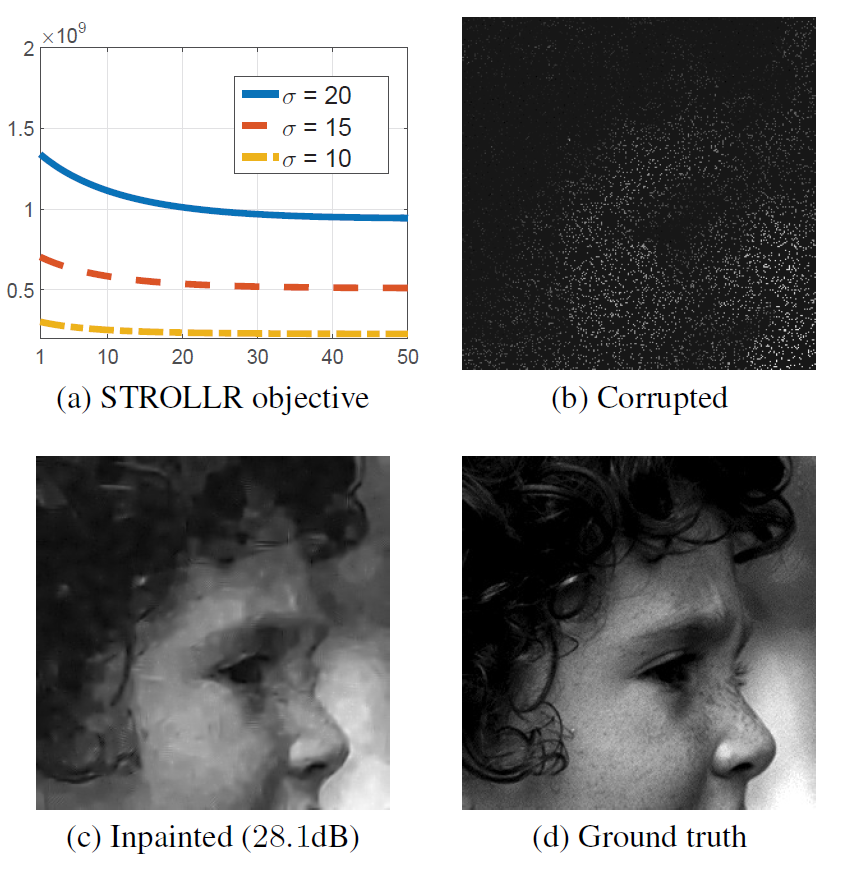
对于一张人脸的图片,在90%像素损失时,STROLLR完成了inpainting的效果:
(a)为一个迭代收敛表示(b)为在噪声方差为10时图像的衰退程度,(c)和(d)为算法结果和GT对比:

















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









