



📖 原文论文:3D-LLM: Injecting the 3D World into Large Language Models
🔗 论文地址:https://arxiv.org/abs/2307.12981
✍️ 作者:Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, Chuang Gan
🎉 发布时间:2023年7月 (收录于CVPR 2024)
🎯 关键词:大语言模型、3D视觉、多模态学习、具身智能、点云理解
一、研究背景与意义
当前的大语言模型(如GPT-4)和视觉语言模型(如BLIP-2、Flamingo)在文本理解和2D图像推理方面表现出色,但它们存在一个根本性局限:缺乏对三维物理世界的 grounding( grounding)。这些模型无法理解真实世界中的空间关系、物体功能属性、物理规律和场景布局,从而限制了它们在机器人、自动驾驶、VR/AR等需要3D空间理解领域的应用。
3D-LLM的提出旨在解决这一核心问题。它将大语言模型的能力扩展到3D领域,使模型能够直接处理3D点云及其特征,并执行一系列需要3D空间理解的任务,如3D问答、场景描述、任务分解、物体定位和导航规划等。
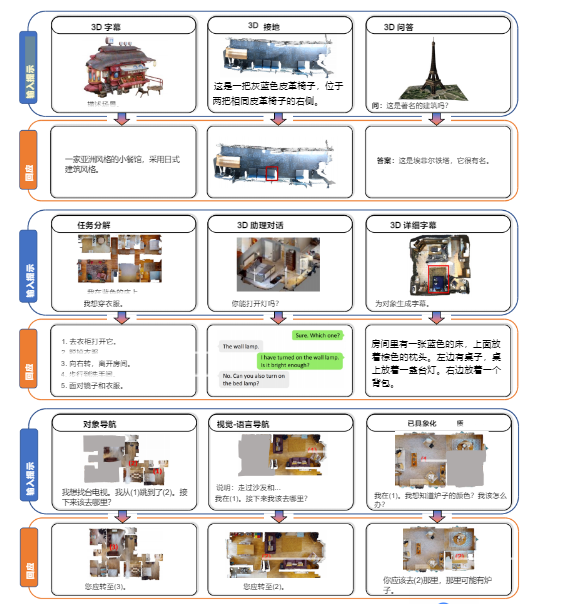
图1:论文所做任务覆盖
二、论文整体结构与主要贡献
论文采用经典的研究范式:动机阐述 → 数据构建 → 方法设计 → 实验验证 → 总结展望。
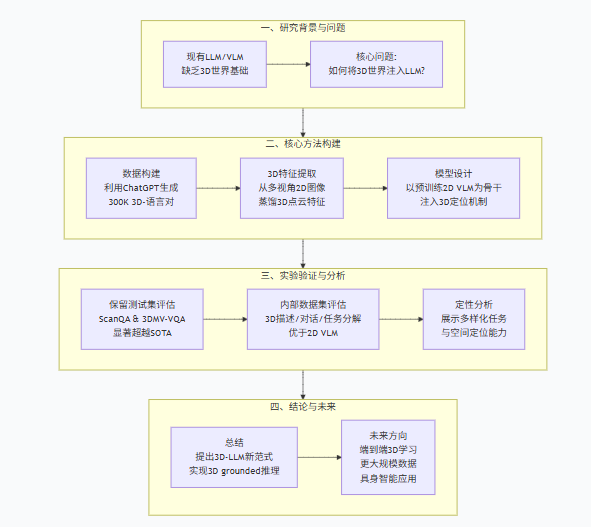
图2:论文组织结构图
主要贡献可总结为四点:
模型创新:首次提出“3D-LLM”这一新模型家族,使LLM能够直接理解和推理3D世界。
数据构建:设计了创新的数据生成流程,利用ChatGPT构建了大规模3D-语言数据集(超过30万条),覆盖多种3D任务。
技术整合:提出了高效的3D特征提取方法,并利用预训练的2D VLM作为主干网络进行快速训练;引入了3D定位机制,使模型具备空间感知能力。
全面验证:在多个标准数据集上验证了3D-LLM的优越性,其在3D问答等任务上显著超越现有SOTA方法。
三、3D-LLM核心方法详解
1.大规模3D-语言数据生成
为了解决3D-语言配对数据稀缺的核心瓶颈,论文设计了三种创新的提示策略,利用ChatGPT自动生成数据:
边界框演示提示:输入场景和物体的3D边界框信息,引导GPT生成多样化的任务数据。
ChatCaptioner式提示:让ChatGPT对多视角图像进行提问,BLIP-2回答,最终合成全局的3D场景描述。
修订式提示:将现有类型的3D数据转换为其他任务所需的数据格式。
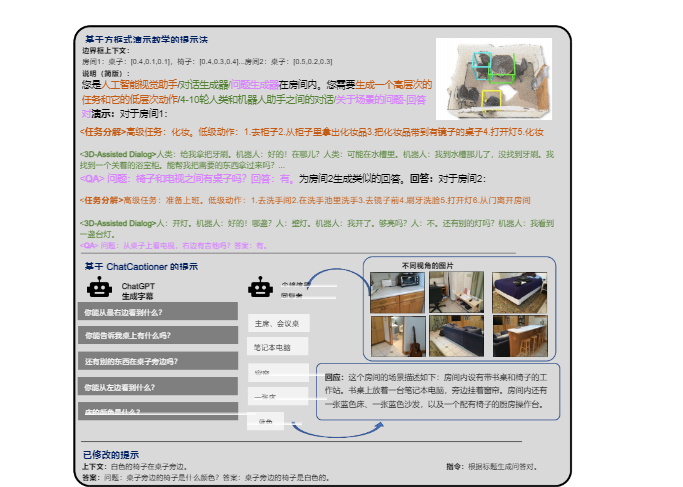
图3:三维语音数据生成流程
2. 3D特征提取器
论文提出了三种基函数,每种都有明确的数学定义和参数控制:
论文没有从头训练3D编码器,而是巧妙地利用多视角渲染技术,从2D预训练模型中“蒸馏”出3D特征:
从3D场景渲染多个视角的2D图像。
使用强大的2D视觉编码器(如CLIP)提取密集的2D图像特征。
通过三种方法(直接重建、特征融合、神经场)将2D特征聚合、反投影到3D空间,形成3D点云特征。
• 直接重建法。通过使用真实相机矩阵,直接从3D数据渲染的rgbd图像中重建点云。特征直接映射到重建的3D点上。该方法适用于渲染的rgbd数据具有完美相机姿态和内部参数的情况。
• 特征融合。我们使用gradslam将2D特征融合到3D地图中。与密集映射方法不同,该方法除了融合深度和颜色外,还融合了其他特征。该方法适用于深度图渲染或相机姿态和内参存在噪声的3D数据。
• 神经场。通过神经体素场构建三维紧凑表示具体来说,该领域中的每个体素除了密度和颜色外还具有其他特征。随后,我们使用 MSE 损失函数将射线中的3D特征与像素中的2D特征进行对齐。该方法适用于具有RGB渲染图像但缺乏深度数据,且相机姿态和内参存在噪声的3D数据
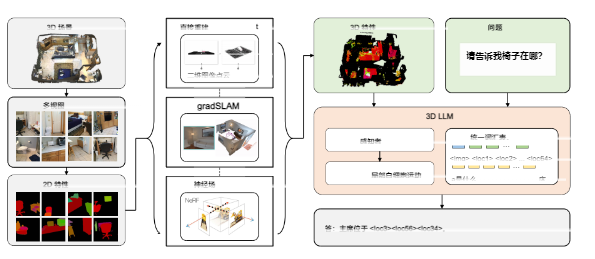
图4:3D-LLM框架的架构示意图。前两列展示了3D特征提取模块
3. 以2D VLM为主干网络
这是一个关键的设计,实现了高效训练:
3D特征被映射到与2D图像特征相同的空间。
直接加载预训练的2D VLM(如Flamingo, BLIP-2)权重作为主干。
这些VLM中的感知器(Perceiver/Q-Former)模块能够处理任意长度的3D点云特征序列。
在训练时,只需微调VLM中的跨模态连接模块和新增的定位令牌,大部分LLM参数保持冻结。
4. 3D定位机制
为了让模型具备空间感知能力,论文提出了双重定位增强:
特征增强:将3D坐标的位置编码与点云特征拼接。
词汇表增强:在LLM的词表中引入位置令牌,用于直接输出物体在3D空间中的边界框坐标(例如<x_min, y_min, z_min, x_max, y_max, z_max>)。
四、实验验证与性能评估
1. 主要实验结果
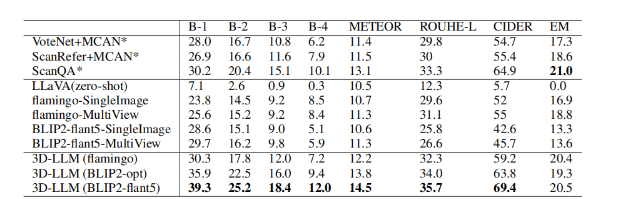
为验证3D-LLM在具体任务上的泛化能力,我们在ScanQA数据集上对其进行了微调,并与一系列强基线模型进行了系统对比。如表1(验证集)与表2(测试集)共同所示,3D-LLM取得了全面性的性能突破。在测试集上,其BLEU-1和CIDEr指标分别显著超越依赖显式物体检测的之前最优化模型ScanQA约7%与5%,这充分证明了将3D全局特征注入大语言模型后,其在答案生成准确性与丰富度上的巨大优势。
更为关键的是,表中所揭示的对比结果指向了一个范式性的突破:传统最优方法(如ScanQA)严重依赖于VoteNet等检测器来提供显式的物体表征,而我们的模型仅需输入全局的3D点云特征,无需任何中间检测步骤,便在物体与关系推理上超越了它们。这揭示了3D-LLM具备了直接从原始几何数据中学习并推理语义的强大能力。此外,表1中“多视图图像”基线的显著性能落差,进一步反衬出经过我们方法所融合的三维全局表征,在信息整合与推理上远比多张离散的2D图像更为有效,从根本上确立了3D信息在场景理解中的不可替代性。
 <p
<p
表一:ScanQA验证集实验结果

表二:ScanQA测试集的实验结果
**2. 多样化任务能力** 定性实验展示了3D-LLM处理多种任务的能力:3D场景描述:生成对整个房间的准确文字描述。
3D问答:“这个场景里有多少把椅子?”
任务分解:“我想打扫房间,应该怎么做?” -> 模型能输出一步步的合理步骤。
3D物体定位:根据语言描述(如“靠近窗户的椅子”)预测物体的3D边界框。
具身导航:在模拟环境中,根据指令规划路径走向目标物体。

图五:定性实例
五、性能评估与深入分析
1. 消融实验
消融研究验证了各个组件的必要性:
3D定位机制:移除位置编码和位置令牌后,模型在定位任务上的性能显著下降。
感知器模块:在Flamingo backbone中移除感知器后,模型性能全面下降,证明了其处理长序列3D特征的有效性。
2. 优势总结
强大的3D推理能力:首次让LLM具备了系统的3D世界理解和推理能力。
任务通用性:一个模型即可处理多种3D任务,突破了传统任务特定模型的限制。
高效训练:利用预训练2D VLM,避免了从头训练的巨大成本。
空间定位能力:创新的定位机制使模型不仅能“说”,还能“指”。
六、应用、挑战与未来趋势
应用场景
3D-LLM为多个领域打开了新局面:
具身智能与机器人:使机器人能真正理解所处的环境,进行规划和人机对话。
自动驾驶:增强车辆对复杂3D场景的语义理解和推理能力。
智能家居与VR/AR:实现与虚拟/增强现实环境的自然语言交互。
3D内容生成与检索:通过语言指令搜索或生成3D场景和物体。
技术优势
统一架构:统一处理多种3D任务,简化了部署流程。
继承LLM强项:继承了大型语言模型的强大推理、泛化和对话能力。
数据效率:通过巧妙的数据生成和方法设计,克服了3D数据稀缺的难题。
七、局限性与未来方向
当前局限
对2D渲染的依赖:3D特征提取依赖于多视角2D渲染,并非端到端的3D处理,引入了额外步骤。
计算资源:尽管训练高效,但推理时处理大量3D点云特征仍需可观的计算资源。
泛化能力:在极端复杂或与训练数据分布差异过大的3D场景中的表现有待进一步验证。
未来研究方向
端到端3D学习:探索不依赖2D渲染的、真正的端到端3D-语言预训练。
更大规模的3D数据:构建更大、更多样化的3D-语言数据集。
与具体行动结合:更深入地与机器人控制、导航策略等低层行动模块结合。
动态3D场景理解:扩展到理解和推理动态变化的3D环境。
多模态融合:结合触觉、音频等多模态信息,构建更全面的世界模型。
八、总结
《3D-LLM: Injecting the 3D World into Large Language Models》是一项里程碑式的工作,它成功地将大语言模型的强大认知能力与3D物理世界连接起来。
核心启示:
grounding 是方向:让AI理解物理世界是实现通用人工智能的关键一步。
数据可以创造:在数据稀缺的领域,利用现有大模型(如GPT)自动生成数据是一条行之有效的路径。
继承与微调是捷径:充分利用现有预训练模型(2D VLM)的能力,通过巧妙的适配实现新模态的快速突破。
空间感知是核心:对于3D任务,显式地建模空间信息至关重要。
这项工作不仅推动了3D视觉与语言的融合,更为具身智能的发展奠定了坚实的基础,预示着AI正在从“文本世界”和“图片世界”大步迈向“物理世界”。


















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









