



一、 简介
Qwen-2-5-VL 是阿里巴巴通义千问团队推出的多模态大语言模型(MLLM),属于 Qwen-2 系列模型的一部分,支持视觉(Vision)与语言(Language)的多模态交互。
1、特性
- 动态分辨率处理:自适应调整图像分辨率以平衡精度与计算效率。
- 跨模态对齐:通过对比学习对齐视觉-语言特征空间,提升模态交互能力。
- 低资源适配:支持量化、LoRA微调等轻量化部署方案。
2、工程目录
Qwen2-5-VL
├── datasets
│ ├──images # 默认为一张panda.jpg的图片
│ └──videos # 默认为一段carvana_video.mp4的视频
├── models
│ └── BM1684X
│ └── qwen2.5-vl-3b_bm1684x_w4bf16_seq2048.bmodel # BM1684X qwen2.5-vl-3b模型
├── python
│ ├── __pycache__
│ ├── configs # 配置文件
│ ├── qwen2_5_vl.py # 启动程序
│ ├── README.md # 说明文档
│ ├── vision_process.py # 视觉数据预处理文件
│ └── requirements.txt # python依赖
├── scripts
│ ├── compile.sh
│ ├── datasets.zip
│ ├── download_bm1684x_bmodel.sh # 1684X盒子模型下载脚本
│ ├── download_bm1688_bmodel.sh # 1688盒子模型下载脚本
│ └── download_datasets.sh # 数据集下载脚本
└── tools # 工具包二、运行步骤
1、准备Python环境、数据与模型
1.1 首先升级python版本为3.10
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.10 python3.10-dev
# 创建虚拟环境(不含pip包),以后每次运行都要按照步骤切换虚拟环境
cd /data
# 创建虚拟环境(不包含 pip)
python3.10 -m venv --without-pip myenv
# 进入虚拟环境
source myenv/bin/activate
# 手动安装 pip
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.py
rm get-pip.py
# 安装依赖库
pip3 install torchvision pillow qwen_vl_utils transformers --upgrade1.2 复制算能官方的Qwen2-5-VL工程目录(或者复制后将Qwen2_5-VL上传到盒子中的/data下)
git clone https://github.com/sophgo/sophon-demo.git
cd sophon-demo/sample/Qwen2_5-VL
cd /data/Qwen2_5-VL ##如果只上传了LLM_api_server,则只需进入此目录下操作1.3 准备运行环境
在PCIe上无需修改内存,以下为soc模式相关:
对于1684X系列设备(如SE7/SM7),都可以通过这种方式完成环境准备,使其满足Qwen2.5-VL运行条件。
首先,确保使用V24.04.01 SDK,可以通过bm_version命令检查SDK版本,如需要升级,可从sophgo.com获取v24.04.01版本SDK,刷机包位于sophon-img-xxx/sdcard.tgz中,参考对应的产品手册进行刷机。
确保SDK版本后,在1684x SoC环境上,参考如下命令修改设备内存
cd /data/
mkdir memedit && cd memedit
wget -nd https://sophon-file.sophon.cn/sophon-prod-s3/drive/23/09/11/13/DeviceMemoryModificationKit.tgz
tar xvf DeviceMemoryModificationKit.tgz
cd DeviceMemoryModificationKit
tar xvf memory_edit_{vx.x}.tar.xz #vx.x是版本号
cd memory_edit
./memory_edit.sh -p #这个命令会打印当前的内存布局信息
./memory_edit.sh -c -npu 7615 -vpu 2048 -vpp 2048 #如果是在1688平台上请修改为:./memory_edit.sh -c -npu 10240 -vpu 0 -vpp 3072
sudo cp /data/memedit/DeviceMemoryModificationKit/memory_edit/emmcboot.itb /boot/emmcboot.itb && sync
sudo reboot1.4 安装unzip以及测试数据集准备
sudo apt install unzip
chmod -R +x scripts/
./scripts/download_bm1684x_bmodel.sh ##下载模型文件
./scripts/download_datasets.sh ##下载数据集2、python例程
2.1 环境准备
# 此外您可能还需要安装其他库
cd /data/Qwen2_5-VL/python
pip3 install dfss -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 您需要安装SILK2.Tools.logger
python3 -m dfss --url=open@sophgo.com:tools/silk2/silk2.tools.logger-1.0.2-py3-none-any.whl
pip3 install silk2.tools.logger-1.0.2-py3-none-any.whl --force-reinstall
rm -f silk2.tools.logger-1.0.2-py3-none-any.whl
# 本例程依赖sophon-sail,可直接安装sophon-sail,执行如下命令:
pip3 install dfss --upgrade
python3 -m dfss --install sail
# 需要下载运行配置文件,执行如下命令
python3 -m dfss --url=open@sophgo.com:sophon-demo/Qwen2_5_VL/configs.zip
unzip configs.zip
rm configs.zip2.2 启动测试
参数说明
可以通过修改qwen2_5_vl.py中的内容进行测试运行。内容如图:
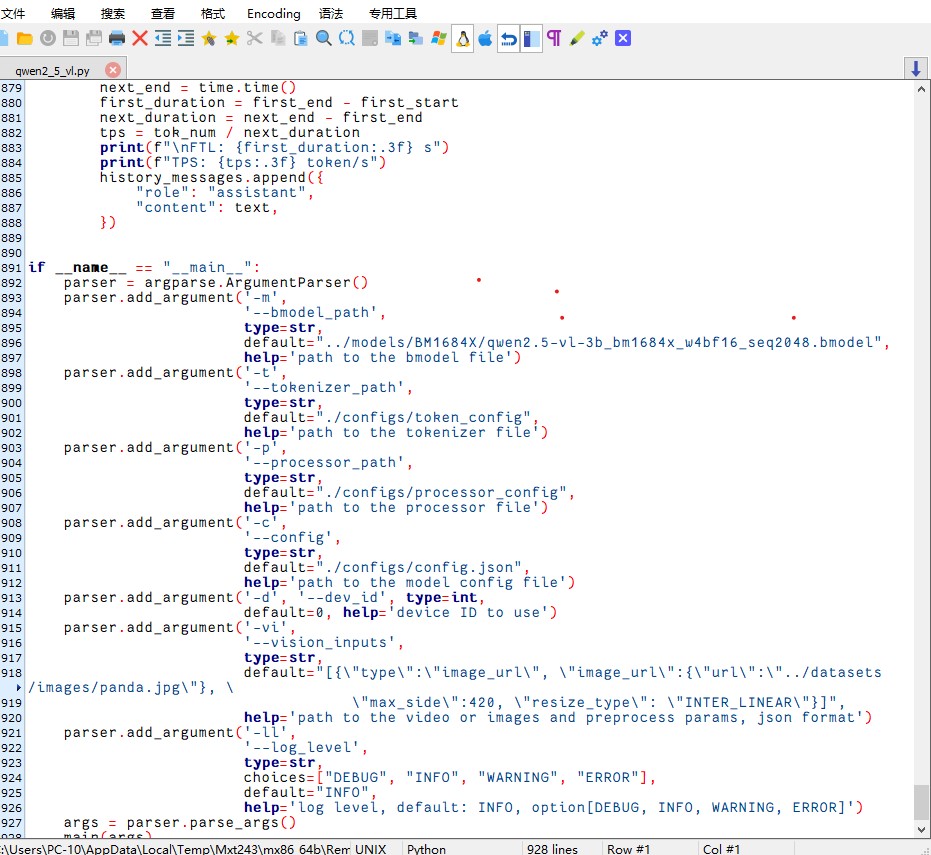
需要将其中896行的bmodel默认路径改为:../models/BM1684X/qwen2.5-vl-3b_bm1684x_w4bf16_seq2048.bmodel
使用方式
# 视频识别
python3 qwen2_5_vl.py --vision_inputs="[{\"type\":\"video_url\",\"video_url\":{\"url\": \"../datasets/videos/carvana_video.mp4\"},\"resized_height\":420,\"resized_width\":630,\"nframes\":2}]"
# 图片识别
python3 qwen2_5_vl.py --vision_inputs="[{\"type\":\"image_url\",\"image_url\":{\"url\": \"../datasets/images/panda.jpg\"}, \"max_side\":420}]"
# 同时
python3 qwen2_5_vl.py --vision_inputs="[{\"type\":\"video_url\",\"video_url\":{\"url\": \"../datasets/videos/carvana_video.mp4\"},\"resized_height\":420,\"resized_width\":630,\"nframes\":2},{\"type\":\"image_url\",\"image_url\":{\"url\": \"../datasets/images/panda.jpg\"}, \"max_side\":840}]"
# 纯文本对话
python3 qwen2_5_vl.py --vision_inputs=""使用效果


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









