








英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.2. fMRI Captioning Evaluation
2.4.4. Adapting BrainChat without Image Data
1. 心得
(1)你就是我命定的paper吗?先不能如此下结论,很怀疑代码“key code”到底有没有我想要的东西
2. 论文逐段精读
2.1. Abstract
①Task: encode the semantic information of fMRI
2.2. Introduction
①Task of BrainChat:

②Integrated techniques: Contrastive Captioner (CoCa) and Masked Brain Modeling (MBM)
③Training mode: encoder/decoder pretraning and regression decoding
aphasia n.失语症;失语(症)
2.3. Method
①Framework of BrainChat:

②Pre-training stage: pretraining encoder and decoder by MBM. Patchify fMRI data and set masked patches to 0. Reconstruct masked data by mean squared error (MSE).
③The encodered fMRI data is project to align with image/text embedding extracted by frozen image encoder and text encoder
from CoCa
④fMRI-image contrastive loss , fMRI-text contrastive loss
:
where denotes paired fMRI-images-text data,
and
is the embeddings of the fMRI, image and text in the
-th pair,
is batch size and
is temperature parameter
⑤Caption loss :
where represents the probability of generating text
conditioned on text from previous time steps
and the fMRI data
⑥Total loss:
where s are weights
⑦fMRI captioning task: input the first text words in caption and predict text word at time
⑧fQA task: the question is set as text encoder, e.g. "Question: What color is the water? Answer:"
⑨Caption generation (ignores image encoder and corresponding loss):

where greens are generated caption and reds are gramma error
2.4. Experiment
2.4.1. Implementation
①Dataset 1: subject 1 of Natural Scenes Dataset (NSD), including 15,724 voxel and captions from COCO for fMRI captioning. NSD and VQA datasets are combined to achieve fQA task
②Dataset 2: HCP for predict masked fMRI in pre-training stage
③Encder and decoder: ViT
④Mask ratio: 0.75
⑤Hyper parameters during pre-training: 5e-10 learning rate with 0.05 weight decay, AdamW with and
with NativeScaler gradient scaling
⑥Hyper parameters during brain decoder: 1e-4 learning rate with 0.1 weight decay
⑦Loss weight: 20 and 1 for caption loss and constractive loss
2.4.2. fMRI Captioning Evaluation
①Captioning performance:
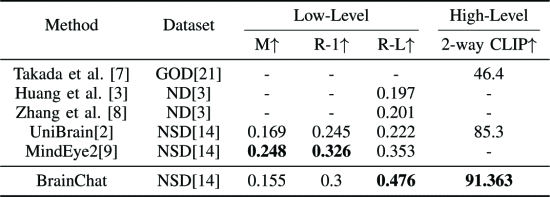
②Quantity measurement of fMRI captioning:

2.4.3. fQA Evaluation
①fQA performance:

②Results of fQA:

where greens are answers
2.4.4. Adapting BrainChat without Image Data
①没图像表现也ok
2.5. Conclusion
~
3. Reference
@INPROCEEDINGS{10889434,
author={Huang, Wanqiu and Ma, Ke and Xie, Tingyu and Wang, Hongwei},
booktitle={ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={BrainChat: Interactive Semantic Information Decoding from fMRI Using Large-Scale Vision-Language Pretrained Models},
year={2025},
volume={},
number={},
pages={1-5},
keywords={Training;Semantics;Functional magnetic resonance imaging;Signal processing;Brain modeling;Question answering (information retrieval);Decoding;Data mining;Speech processing;Software development management;fMRI question answering;fMRI captioning;fMRI decoding;large-scale vision-language model;human-computer interaction},
doi={10.1109/ICASSP49660.2025.10889434}}

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









