








论文网址:Learning Transferable Visual Models From Natural Language Supervision
论文代码:GitHub - openai/CLIP:CLIP(对比语言-图像预训练),在给定图像的情况下预测最相关的文本片段
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.2. Introduction and Motivating Work
2.3.1. Natural Language Supervision
2.3.2. Creating a Sufficiently Large Dataset
2.3.3. Selecting an Efficient Pre-Training Method
2.3.4. Choosing and Scaling a Model
1. 心得
(1)看的arxiv长一点的版本,会议本体会更短一点
(2)一不小心读到经典调参/疯狂训练文章了吗!!反正是单个人不太能实现的操作,推荐只看模型架构
2. 论文逐段精读
2.1. Abstract
①Limitation for existing pre-trained works: large number of labelled data needed
②CLIP learned image and text by zero-shot way
2.2. Introduction and Motivating Work
①Dataset: includes 400 million (image, text) pairs
②Framework of CLIP:
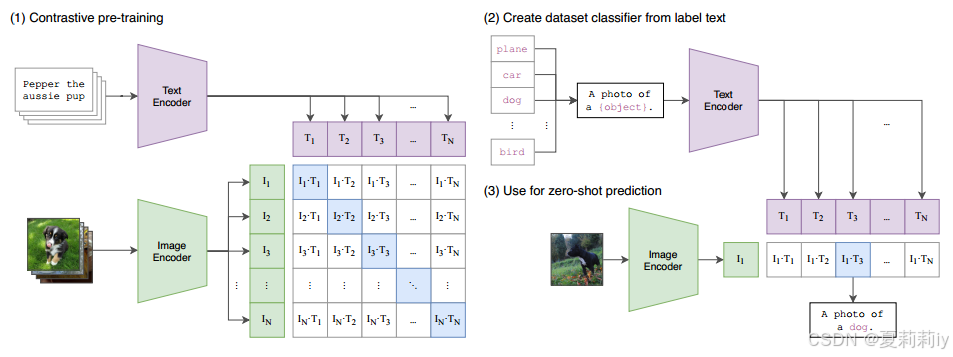
(在这里简介一下,只想了解模型框架的话不用往后翻了。(1)训练:输入是配对的词组文本和图像,分别通过不同的编码器将他们变成文本嵌入和
,对每个嵌入算相关矩阵。损失是交叉熵,盲猜是让相关矩阵对角线(成功匹配)的值变高,
,然后让白色块不相关的值变低
。损失简化为
。损失越小越好,被训练的东西是俩编码器。(2)测试集标签:把标签加上提示然后送入训练好的文本编码器,把没见过的东西变成预测的嵌入集合。(3)把测试集图片通过训练好的图片编码器变成嵌入,去和所有文本嵌入算相关性,取最相关的可能)
2.3. Approach
2.3.1. Natural Language Supervision
①Learning multi-representations from natural language
2.3.2. Creating a Sufficiently Large Dataset
①They used relevant small datasets, MS-COCO, Visual Genome, and YFCC100M
②Moreover, they create a new dataset WebImageText (WIT)
2.3.3. Selecting an Efficient Pre-Training Method
①For plenty of data and training time, they aim to improve training efficiency
②Learning efficiency of different methods:
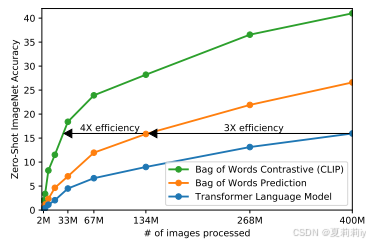
③They fucos on match image and text rather than predict the text word by word through increasing the cosine similarity of matching pairs and reduce the similarity of non matching pairs
④Pseudo code of CLIP:

2.3.4. Choosing and Scaling a Model
①Base architecture for the image encoder: ResNet-50, revised by ResNet-D and antialiased rect-2 blur pooling. They replace global average pooling layer by attention
②Text encoder: 12 layer 512-wide Transformer with 8 head
③Text mark: [SOS] and [EOS](比如“I eat burger”→“[SOS] I eat burger [EOS]”)
2.3.5. Training
①这个建议看原文,就是超参数设置
2.4. Experiments
2.4.1. Zero-Shot Transfer
(1)Motivation
①Motivation: zero-shot transfer(鼓励归鼓励,为什么这样就能保证效果啊)(作者:许多流行的计算机视觉数据集是由研究界创建的,主要是作为指导通用图像分类方法开发的基准,而不是衡量特定任务的性能。)
(2)Using CLIP for Zeto-Shot Transfer
①Class in training set: 32,768
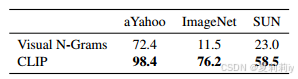
(3)Initial Comparison to Visual N-Grams
①Performance:
(4)Prompt Engnieering and Ensembling
①Single word of image description might cause ambiguity (polysemy)
②For aligning training text and test text, they add prompt "a photo of {}" to increase the length of test text
(5)Analysis of Zero-Shot CLIP Performance
①Zero-Shot CLIP vs. Linear Probe on ResNet50 on different dataset:
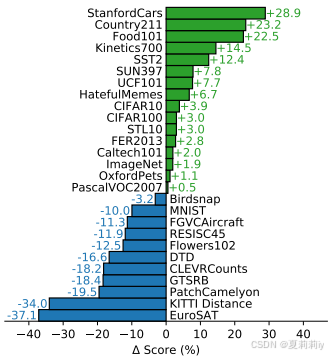
②Few-shot comparison:
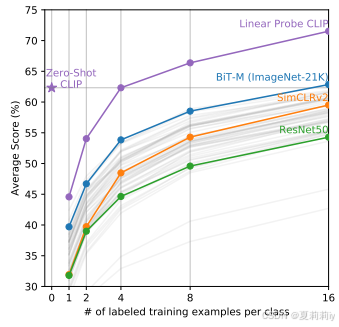
后面不记录了都是一些实验感兴趣自己看,就是CLIP表现。扫了一遍应该没有可解释性的图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









