




计算机视觉,即 Computer Vision,简称 CV,是指用计算机实现人的视觉功能—对客观世界的三维场景的感知、识别和理解。目前,计算机视觉仍然是深度学习中最热门的研究领域之一,其主要包含以下四个任务:图像分类、目标检测、语义分割、实例分割。首先我们将介绍以下四种任务分别有什么特点,以及分别在解决什么问题。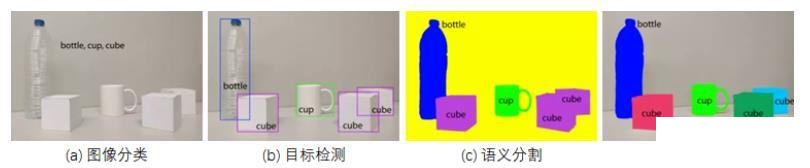
图像分类 - Image Classification:解决的是“是什么”的问题。图像分类的任务便是要找出图中包含着哪些目标,如图(a)所示,图中包含 bottle、cup 和 cube 三种目标。与此任务相关的挑战包括视点变化、尺度变化、类内变化、图像变形、图像遮挡、光照条件、背景杂乱等。
目标检测 - Object Detection:解决的是“是什么+在哪里”的问题。在图像分类中,我们可以知道当前图片中包含了哪些目标物体。进一步地,我们更希望知道这个目标具体在哪个位置,这便是目标检测的任务。如图(b)所示,我们为图中的每一个目标物体都给定一个矩形框标识着当前目标所在的位置。
语义分割 - Semantic Segmentation:解决的是“每个像素点是什么”的问题。语义分割是对目标物体进行一个像素级分割,即对图像中的每一个像素点都进行分类。但是同一物体的不同实例不需要单独分割出来,如图(c)中所示的 cube,都归属于同一个语义类别。
实例分割 - Instance Segmentation:在语义分割的基础上,进一步区分属于同一个类别的不同实例。如图(d)中所示的 cube,我们还需要将其具体的区分为不同的 cube。
目前,计算机视觉仍然是深度学习中最热门的研究领域之一,它主要涵盖了以下应用:
(1)光学字符识别 OCR
OCR 包含了:手写数字识别、中文字符识别、英文字符识别等等。这个任务算是计算机视觉领域中最早落地的方向,早在 1989 年,LeCun 等人在贝尔实验室提出了 LeNet 用于解决邮政编码识别,并成功落地应用。
(2)人脸相关
人脸相关的算法主要有:人脸检测、人脸验证、人脸关键点检测、表情识别等等。其中最常见的任务便是人脸检测以及人脸验证了。其中,检测是验证的前置要求,而人脸验证是将候选人脸与另一个人脸进行比较,并验证其是否匹配的任务。
(3)姿态估计 Pose Estimation
姿态估计方向主要包含:人体姿态估计(2D/3D)、人体姿态预测(视频)、手势姿态估计、头部姿态估计、动物姿态估计等等。其中人体姿态估计为比较热门的研究方向,主要可以用于人体行为判断、AR 试衣、自动驾驶(预测路人行动)等领域。其主要实现的方式是通过检测人体关键点来完成人体的动作、行为识别。
(4)超分辨率 Super Resolution
超分辨率方向主要包含:单帧图像超分辨率、视频超分辨率、点云超分辨率等等。简单地来说,超分辨率的目的是为了提升图像/点云的分辨率。尽管传统图像变换采用的线性插值、最邻近插值等方式可以提高图像的分辨率,但是图像中的信息并没有增加,细节信息也并没有得到恢复,因此只是简单的放大操作。而超分辨率可以通过对训练样本的学习,通过学习不同的模式并将其添加到图像当中从而恢复图像缺失的细节信息。
(5)图像生成 Image Generation
图像生成方向主要包含:风格迁移、图像到图像转换、人脸生成、人体姿态生成、面部修复等等。其主要使用的是生成网络来分离出两者共有的结构分布,和独有风格分布,从而进行进一步的融合以生成目的图像。
(6)自动驾驶 Autonomous Driving
自动驾驶方向包含的视觉任务主要有:车道线检测、交通信号灯检测、全景分割、行人检测等等。当然,完成自动驾驶还需要有诸如定位、导航、控制等算法,我们这里只列举了其中与视觉相关的算法。
(7)即时定位与地图构建
SLAM近年来,由于无法使用 GPS 或 GNSS 的室内制图技术,机器人技术和自动驾驶汽车技术的使用引起了广泛的关注,该技术被称为 SLAM。SLAM 是一种即时定位与地图构建任务,在此过程中,机器人会构建代表其空间环境的地图,同时跟踪其在构建的地图中的位置。
(8)图像去噪 Image Denoising
去噪方向主要包含:去噪、图片去噪。由于数字设备常受到相机抖动、运动的物体、暗光和噪声等影响而导致捕获的照片“不干净”。因此去噪技术具有很大的应用价值。传统去噪方法有:利用非局部相似性、字典学习、MRF、WNNM 等;现代方法主要是基于深度学习技术:栈式稀疏去噪自编码器、多层感知机、卷积编解码网络、深层神经网络等。相对于前者,后者是一种端对端的训练方式,无需手动调整参数,拥有更强的学习能力。
(9)图像去雾 Image Dehazing
图像去雾的目的是消除雾霾环境对图像质量的影响,增加图像的可视度。传统的图像去雾方法主要有暗通道先验(DCP) 方法,最大对比度(MC)方法,颜色衰减先验(CAP)方法,色度不一致方法,其中以何凯明的暗通道先验方法最为著名;现代深度学习图像去雾方法主要分为两种:一种是基于大气退化模型,另一种则是训练一种端到端的图像去雾模型!其中端到端方式已成为深度学习中的主流去雾模型。
(10)图像去雨 Image Deraining
图像去雨是从包含雨水的图像生成去除雨水的图像。早期的去雨方法主要包含稀疏编码和 GMM 方法。现代基于深度学习的去雨方法绝大部分使用:全监督方法,其采用多阶段的方式或 encoder-decoder 的架构,用全卷积学习雨图到无雨图的映射或残差来训练模型。
(11)行人重识别 Person Re-ID
行人重识别研究研究不同于目标识别,它能够实现跨越时间和空间对目标人体(人群)进行跟踪、匹配与身份鉴定,这是近年来计算机视觉的研究热点之一。因此,行人重识别技术需要分析目标的空间依赖关系,还需要分析目标变化的历史信息。行为识别涉及到技术主要包含兴趣点提取,密集轨迹,光流和表观并举,3D 卷积网络,LSTM 和 GCN 等。
(12)缺陷检测 Defect Detection
缺陷检测,在工业上应用非常广泛,如电路板表面缺陷检测、金属零部件表面缺陷检测、布匹检测、固件缺陷检测、混凝土裂缝检测、公路裂缝检测等。传统的基于机器视觉的算法很难对缺陷特征进行完整的识别,而且通常会耗费大量精力,得不偿失。由于卷积神经网络在特征提取业的强大能力以及目标检测算法日趋成熟的背景下,使得业界普遍将度学习技技术应用到陷检测领域当中。
(13)视频理解 Video Understanding
视频理解,主要是基于视频中的时序信息来进行视频分析。相对于图像而言,视频多了一维时序信息,其应用场景相对也比较广泛,比如在智能安防领域中我们可以使用视频理解技术来取代人工进行相应的视频监控。
(14)图像融合 Image Fusion
图像融合是用特定的算法将两幅或多幅图像综合成一幅新的图像。融合后得到的图像可以对场景有更全面、清晰的描述,从而更有利于人眼的识别和机器的自动探测!图像融合技术在遥感探测、安全导航、医学图像分析、反恐检查、环境保护、交通监测、清晰图像重建、灾情检测与预报尤其在计算机视觉等领域都有着重大的应用价值,一般图像融合方法主要包含空间域融合和变换域融合方法;其中空间域融合方法主要包含:简单组合式图像融合方法,逻辑滤波器法,数学形态法和图像代数法。而变换域融合方法主要包含:HIS 变换法,PCA 变换法,高通滤波法 HPF,金字塔分解法和小波变换法。
(15)图像检索 Image Retrieval
图像检索是一种用于从大型数字图像数据库中浏览,搜索和检索图像的一种技术。常规的图像检索有基于文本的检索、基于内容的检索以及基于语义的检索。其中基于语义的检索由于其需要对海量的图片进行语义级别的标注,不仅主观性强而且费时费力,同时其语义也很难全面的表达图像中所包含的所有信息,因此实际中很少实现。而基于内容的检索,也称为 CBIR 技术,常见的应用场景有 “以图搜图”,在实际中被广泛使用。
(16)全景分割 Panoptic Segmentation
图像全景分割是语义分割与实例分割的结合,在全景分割中,图像中每个像素点都必须被分配一个语义标签和实例 ID,其中语义标签指的是物体类别,而实例 ID 则对应同类物体的不同编号。
(17)医学图像 Medical Image
医学图像任务主要包括:病变检测、图像分割、图像配准。类似于自然图像领域,卷积神经网络比传统算法能更有效地作用于医学图像,然而医学图像还存在着以下难点
1.样本数据量少且无法人工生成;
2.噪声大,关键信息占比小;
3.标注成本高。
鉴于这些困难,一些基于深度学习的技术如:迁移学习和微调能有效地解决以上问题。
(18)遥图图像 Remote Sensing Image
遥感图像能够精确的描述各种地理空间物体,如车辆、船舶和飞机等。遥感图像一般都是高空间分辨率,从遥感团行中自动提取感兴趣的对象对城市管理计划和检测非常有帮助。地理空间对象分割作为对象提取中的重要角色,可以为感兴趣的对象提供语义和位置信息,该信息属于特定的语义分割任务,目的是将图像像素分为前景对象和背景区域的两个子集 。同时,它还需要为前景对象区域中的每个像素进一步分配唯一的语义标签。

















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









