







Link of paper: https://arxiv.org/abs/2203.07814
Competition-Level Code Generation with AlphaCode
Introduction
The problem in HumanEval is relatively simple and that the docstring detailly describes steps to do rather than describing a real and ambiguous problems that usually appears in programming competition, like CodeForces. To address this challenge, DeepMind published AlphaCode, which gains a median (or even better) performance in competition.
Problem Setup
Competitive programming
In competitive programming, the format of problems is similar to problems in leetcode but usually more complicated with much longer and more ambiguous problem description.
Evaluation
The metric used is called n@k, which means “percentage of problems solved using n n n submissions from k k k samples per problem, n ≤ k n\le k n≤k”. The problem is considered solved if any of these n n n submissions passes all tests.
Dataset
Pre-training
Similar to Codex, AlphaCode is also trained on dataset collected from GitHub, but containing multiple popular programming languages. After filering, they gained 715GB of Code.
CodeContests fine-tuning dataset
A dataset with higher quality is used to fine-tune the model. It is mainly collected from codeforces and other online programming competition websites, containing problem description, solutions and test cases. We can see that for each problem there are a lot of solutions for different language, but they are not always correct.
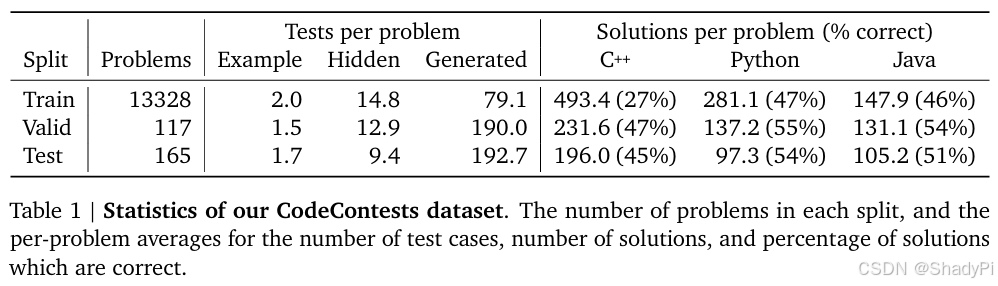
To prevent data leakage, the train, valid and test dataset is split based on publicly released time.
To do more strict and comprehensive evaluation, the authors generated more test cases. Because the public test cases may be not “strong” enough to find the mistake in code, which is called “false positive”. And they found that there exists a lot of false positive in previous dataset and CodeContests without generated test cases.

In summary, the authors created a larger pre-training dataset with multiple programming language and a fine-tuning dataset with much higher quality.
Approach
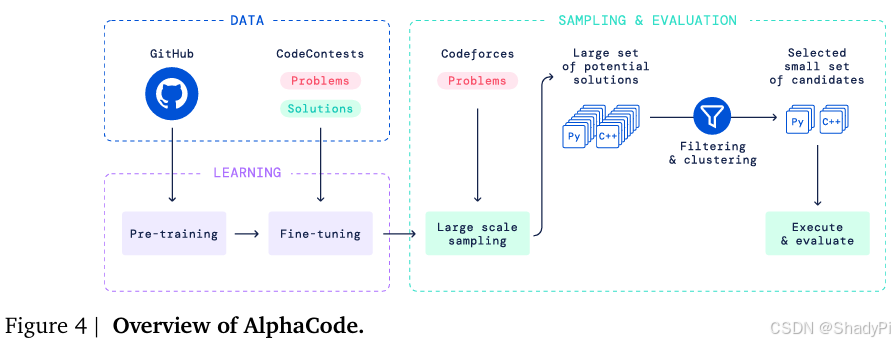
Model architecture
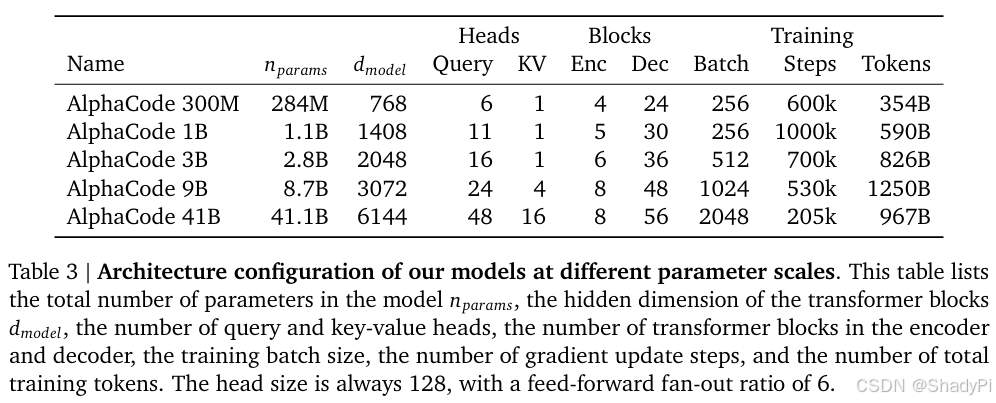
The authors take the programming problem as a kind of “translation” from problem description to code, which naturally motivates the choice of encoder-decoder Transformer architecture. The encoder architecture allows bidirectional description representation and is more flexible to adjust for input encoding, e.g., the token length of encoder is 1536 and token length of decoder is 768 because problem descriptions are on average twice as long as corresponding solutions. Also, AlphaCode has shallow encoder and deep decoder, which makes the model more efficient. Another detail is that AlphaCode applied a special model parallelism, with 1 key, value head per shard.
Pre-training
Because this is a Transformer, the authors uniformly sampled pivot locations and used the content before pivot as input for encoder, content after pivot as input/target for decoder.
Fine-tuning
Tempering
They used a relatively low temperature 0.2 to make the logits distribution “sharper”. They said this could “helps avoid overfitting to fine-tuning dataset”. By sharpen the logits, the model will focus on top candidates and only update them, like a dropout layer. Additionally, in softmax activation function with low temperature, the gradient in large magnitude area will be larger, prohibiting gradient vanishing. Low temperature works better may also because the generated content is quite long, it is better to choose more confident candidate.
Value conditioning & prediction
Notice that there are a lot of incorrect solutions in the dataset. To take the advantage of them, the authors added value conditioning to explicitly mark a solution’s correctness in training.

Additionally, they added an auxiliary classification task to predict whether the generated code is correct from the last layer token representations before project to logits. (Actually, I am quite confused that as the input has already include the conditioning information, is it data leakage? From an end-to-end angel, does this auxiliary task really work? Because the small transformer for classification is not used in inference)
GOLD
There might be multiple plausible solutions for one problem. However, the model only needs to generate one of them instead of fitting all different solutions. So, the authors applied GOLD, an offline RL algorithm to let the model learn more from tokens that it already assigns high likelihood and ignore others, acting like focusing on one correct solution rather than learn all correct solutions.
∇
L
G
O
L
D
(
θ
)
=
−
∑
s
∈
Solution tokens
P
θ
(
s
)
∇
log
P
θ
(
s
)
\nabla \mathcal{L}_{GOLD}(\theta) = - \sum_{s\in \text{Solution tokens}}P_\theta (s)\nabla\log P_\theta(s)
∇LGOLD(θ)=−s∈Solution tokens∑Pθ(s)∇logPθ(s)
The additional
P
θ
(
s
)
P_\theta(s)
Pθ(s) multiplicative importance weight allows the model to both learn from tokens it already assigns high likelihood to,and to ignore tokens that are not in its distribution. This way, the model can concentrate on precision rather than recall and increase its chance of getting at least one correct sample. To mitigate instabilities during training,
P
θ
(
s
)
P_\theta(s)
Pθ(s) in the importance weight with
max
(
P
θ
(
s
)
α
,
β
)
,
α
=
1
2
,
β
=
0.05
\max(P_\theta(s)^\alpha, \beta), \alpha=\frac{1}{2},\beta=0.05
max(Pθ(s)α,β),α=21,β=0.05.
P.S. Actually, the equation can be simplified further
P
θ
(
s
)
∇
log
P
θ
(
s
)
=
P
θ
(
s
)
∇
P
θ
(
s
)
P
θ
(
s
)
=
∇
P
θ
(
s
)
.
P_\theta (s)\nabla\log P_\theta (s) = P_\theta (s)\frac{\nabla P_\theta (s)}{P_\theta (s)} = \nabla P_\theta (s).
Pθ(s)∇logPθ(s)=Pθ(s)Pθ(s)∇Pθ(s)=∇Pθ(s).
So, to be more straightforward, GOLD is trying to use gradient of likelihood function to update parameters and minimize log likelihood?
Large scale sampling
Codex only generates 100 samples and rerank them. In contrast, AlphaCode generates millions of samples. To enhance diversity, they will randomly set the metadata, e.g., rating, tags and language and do inference with a little bit higher temperature (0.25).
No significant improvement is observed with different sampling method.
Filtering
Filter solutions with given examples in problem description. The authors said 99% of samples will be filtered out and 10% of problems cannot find a sample passing all examples. I think this indicates that the quality of generated code is actually very low that 99% of generations cannot even pass the example, the simplest case of the problem. Usually, it won’t happen on human programmers, it is rare even for beginners! And with millions of samples, there are still 10% of problems that cannot find a passing-example level solution!
Clustering
After filtering, there might still remain thousands of samples. AlphaCode applies a behavior-based clustering. The authors trained another model to produce test cases based on problem description (the generated test cases are not required to be valid) and these test cases are input to the generated program. Then they applied clustering based on the programs’ output. They will pick sample from every cluster from biggest to smallest as the final candidates.
Results
Codeforces competition
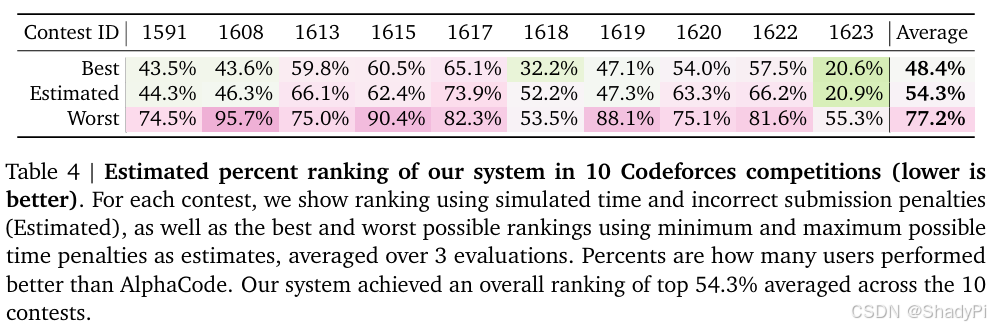
CodeContests
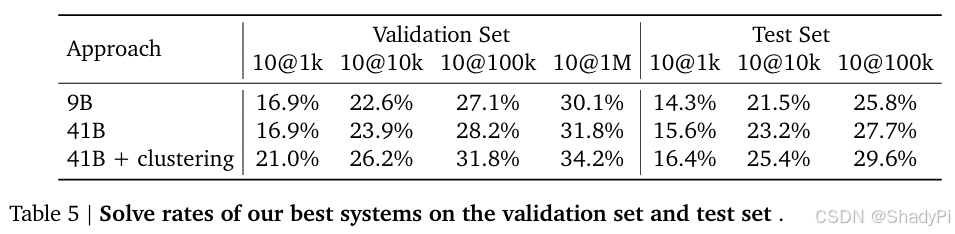
We can see that to reach the highest performance, it requires a huge amount of sampling, which is quite expensive.
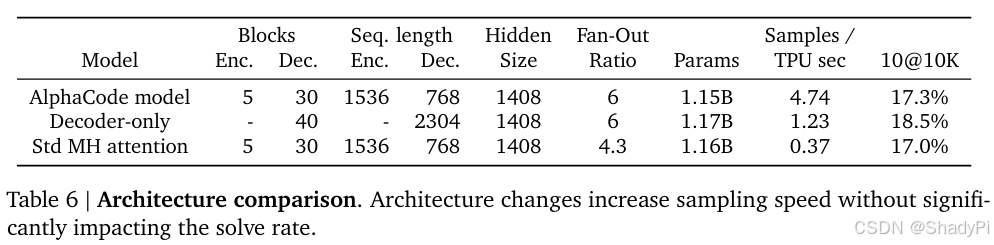
The architecture of AlphaCode does improves the efficiency. Decoder-only architecture requires longer token length to involve the problem description. So, we can say that for long context, it is cheaper to use an encoder-decoder rather than decoder-only.



















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











