







Link of paper: https://arxiv.org/abs/2107.03374.
Evaluating Large Language Models Trained on Code
Introduction
Codex is a GPT-based model fine-tuned on public code from GitHub, to write Python code. (But copilot, a distinct version of Codex, support multiple programming languages.) Because GPT-3 is not trained on datasets containing too much code, the coding performance of GPT-3 is not so good. To gain a LLM that is “more proficient” on coding. The authors tried to fine-tune GPT solely on code. So, codex might be considered as a procedure to produce a set of parameters of GPT for coding, instead of a “brand new” model.
The main function of Codex is, given docstring (can be seen as the notation or natural language description) of the function, Codex will generate the function in Python. OpenAI collected a dataset of 164 programming problems with unit tests, containing language comprehension, algorithm and simple mathematics. The difficulty is “some comparable to simple software interview questions”. The dataset called HumanEval can be found at https://github.com/openai/human-eval.
The performance (pass rate) along with model scale is shown below:
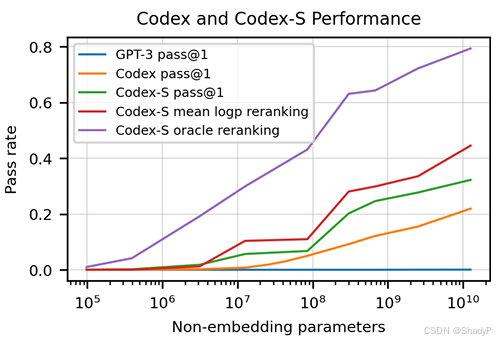
where Codex-S is a further fine-tuned model on from-docstring-to-code generation task. “mean logp reranking” means generate 100 code candidates and pick the one with the highest mean log-probability, and “oracle reranking” means optimal pick up, which is equivalent to pass@100.
Evaluation Framework
Metric
Usually, we will use metrics based on substring match to evaluate generated content, like BLUE and RONGE. However, apparently, they won’t work well on evaluating generated code because code has very low tolerance of mistakes and “similar” is not acceptable. In fact, we have a more straightforward way to evaluate generated code compared with other natural language generations. By simply running the generated function on unit tests, we will know whether it is correct. The quantitative metric is pass@k, the formula is
pass
@
k
:
=
E
Problems
[
1
−
(
n
−
c
k
)
(
n
k
)
]
\text{pass}@k:=\mathbb{E}_{\text{Problems}}\left[1-\frac{\binom{n-c}{k}}{\binom{n}{k}}\right]
pass@k:=EProblems[1−(kn)(kn−c)]
where for each problem Codex will generate
n
,
n
≥
k
n, n\ge k
n,n≥k generations, in which
c
c
c of generations are correct. The fraction is calculating the probability that among all
n
n
n generations, pick
k
k
k and none of the
k
k
k picked generations is correct. This is more stable compared with just generate
k
k
k generations. Notice that directly computing the combination may lead to overflow, a trick is to compute the product of fractions step by step.
Hand-Written Evaluation Set
All problems in HumanEval, including function signature, docstring, body, and several unit tests and all hand-written to avoid data leakage.
Sandbox for Execution
Execute generated function in sandbox to avoid harmful snippet.
Code Fine-Tuning
Data Collection
159GB Python code from GitHub. Notice that the authors did not clarify the license of these code, which implies that they may collect some code regardless of requiring for authorization.
Methods
Compared with training from scratch, fine-tuning from GPT-3 did not gain more performance improvement, but converge more quickly.
By adding special tokens representing whitespaces of different length, it reduces 30% tokens to represent code.
Supervised Fine-Tuning
Methods
Python code dataset collected from GitHub is really massive and contains a lot of different tasks, which places a gap between the training dataset and HumanEval evaluation set (generate function from docstring). To collect training dataset that aligns better with HumanEval, the authors collected problems from Competitive Programming and Continuous Integration and filtered out ambiguous/too difficult problems if Codex cannot generate a correct answer in 100 times. Utilizing this dataset, they applied further fine-tuneing and gained Codex-S.
Results
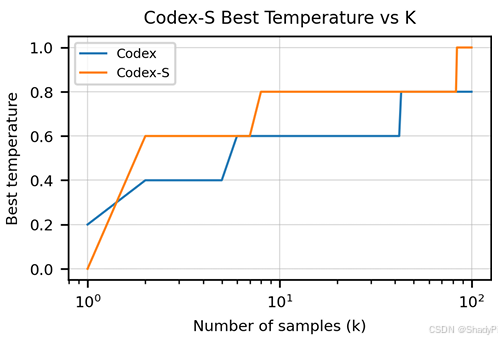
To gain best performance, the larger the number of samples (
k
k
k), the higher the temperature.
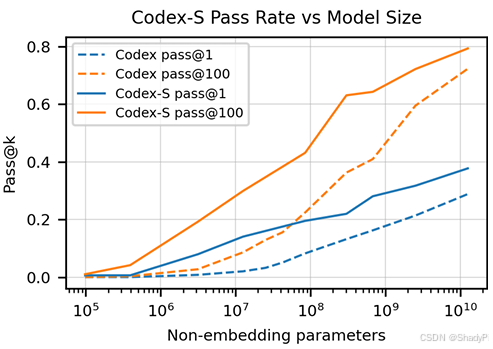
Codex-S shows significantly better performance than Codex.
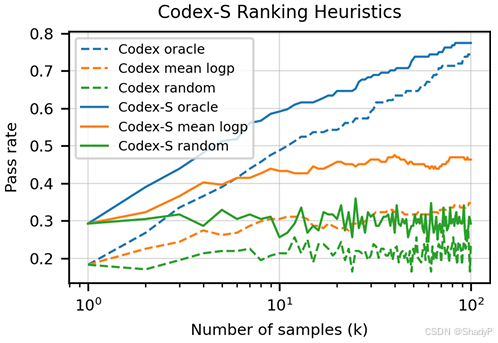
Docstring Generation
By reorganize the order of dataset from “function signature - docstring - implementation” to “function signature - implementation - docstring” to let the model learn how to generate docstring according to function implementation. The model fine-tuned on this dataset is called Codex-D. Due to the lack of ground-truth, the generated docstring is evaluated by hand-grading.
Limitations
- Not sample efficient. With 159GB python code in training dataset, the performance of Codex is not satisfactory.
- It is hard for Codex to handle long docstring or implement function with many operations/variables.
Broader Impacts and Hazard Analysis
Over-reliance, Misalignment (model is able to do, but don’t), Bias, Labor market, Security, Environment, Law (sometimes model generate the same code as its training data, despite the use license).


















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











