




CLIP
使用网络上爬取得到的大量图文对进行对比学习,图文匹配的是正样本,图文不匹配的是负样本,使匹配样本的embedding之间的距离尽可能小,不匹配样本间的距离尽可能大。
缺点:网上爬的数据质量差,不能进行生成式任务。
BLIP
CLIP只有ITC(Image Text Contrastive)任务,但不能做生成式的任务,而BLIP则提出了一个新的框架将ITM(Image Text Match)和LM(Language Model,即生成文本)的任务融合在一个框架里,称为Mutimodal mixture of Encoder-Decoder (MED)。
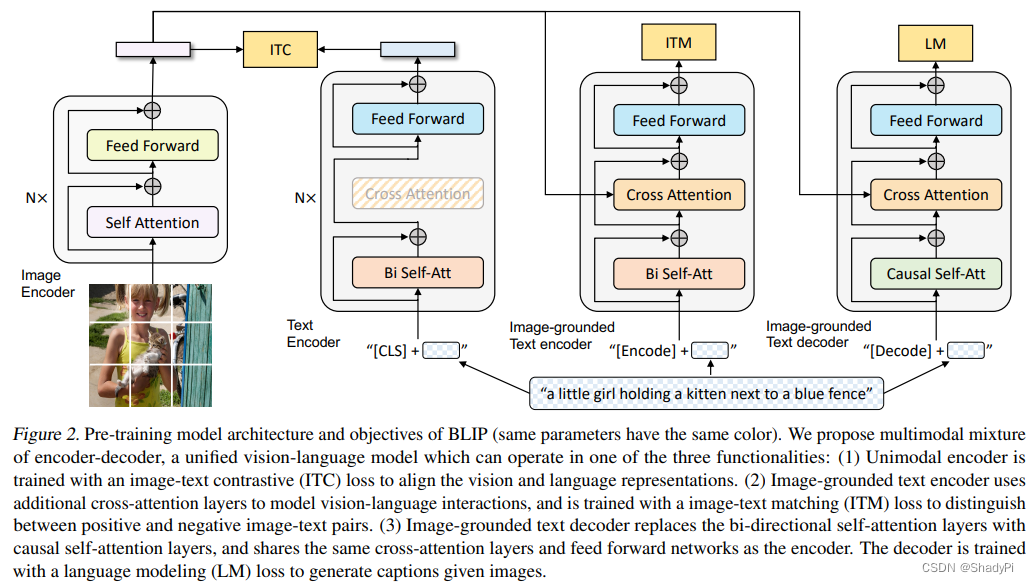
ITC做的任务跟CLIP几乎一致;而ITM的任务是一个二分类,输出图文是否匹配;LM任务就是根据图片输出对应文本。这三个任务将在同一框架下一起训练。
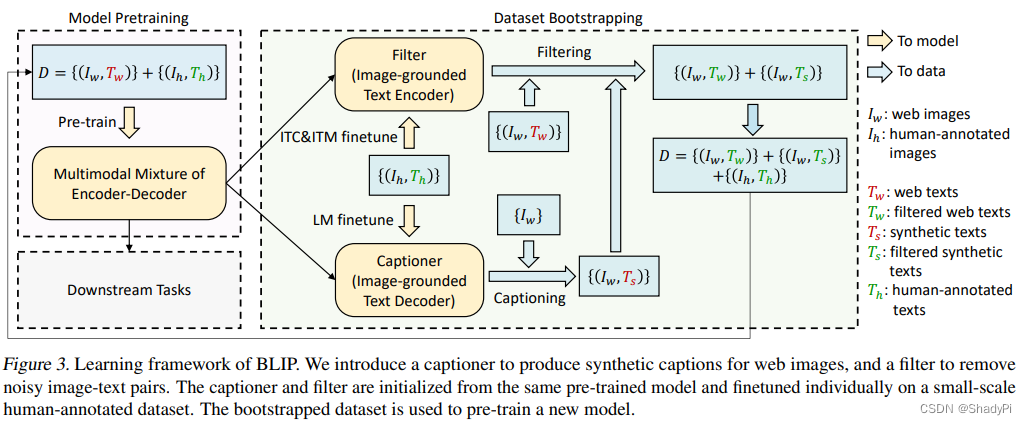
对于CLIP中爬取的数据噪声太多的问题,BLIP也提出了一个全新框架,Captioner-Filter框架,类似一个数据增强训练框架。左侧浅紫色的部分对应上图的整个训练框架,TwT_wTw和TsT_sTs分别表示网上爬取的文本和LM生成的文本,绿色为较干净的数据,而红色是包含噪声较多的数据,ThT_hTh为人工标注的高质量数据,但是数据量非常少。
如下图,我们先用红TwT_wTw和ThT_hTh对MED做一个预训练。然后对于Filter(ITM任务部分)和Captioner(LM任务部分)我们使用人工标注的高质量数据集ThT_hTh进行微调。紧接着开始数据增强进程,由于Filter和Captioner都是用高质量数据集微调过的,因此其都更倾向于低噪声、高匹配度数据。此时有两个增强路线,路线1是将网上爬取的低质量TwT_wTw通过Filter,筛选出高质量的部分,即绿色TwT_wTw;路线2是给Captioner输入图片,使其生成对应的描述,这个描述同样过一遍Filter得到高质量部分,记作绿色TsT_sTs,三个绿色的数据共同组成了增强版高质量数据集,用这个数据集我们可以继续训练整个MED。
BLIP2
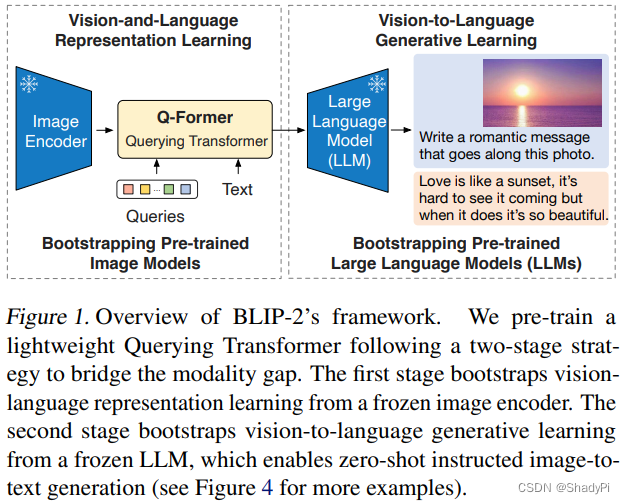
在BLIP的基础上,BLIP2主要专注于如何增大模型的规模,因为BLIP肉眼可见是一个非常庞大的框架,里面包含非常多的需要训练的参数,限制了模型规模的进一步扩大。BLIP2的思路是首先冻结住参数量最多的Text/Image Encoder。但不训练编码器的话,图文编码之间会有巨大的gap,为了解决这个问题,BLIP2引入了Q-Former(Querying Transformer)一个轻量级的Transformer来弥合两个冻结的编码器之间的gap。
Q-Former的输入是图片编码、一个可学习的Queries向量以及对应的文本,输出则是要求提取出图片中与文本相关的信息。
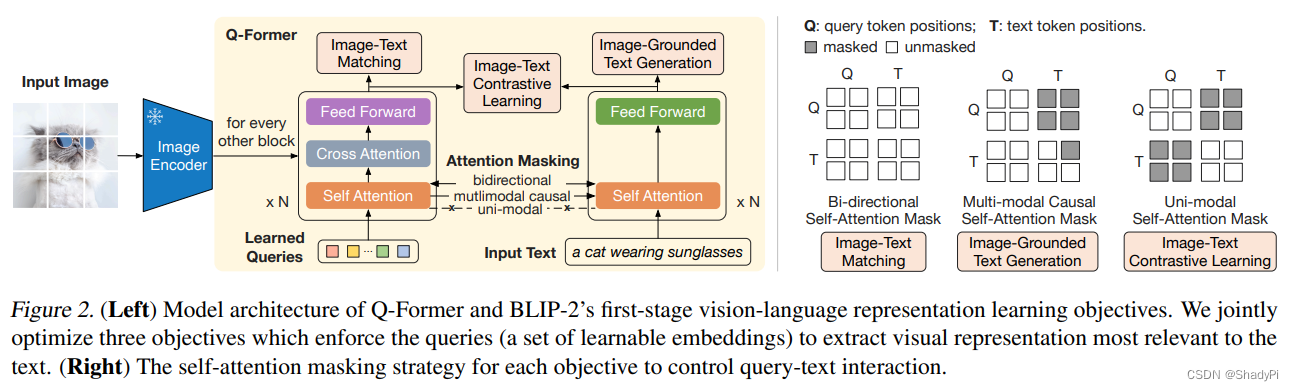
上图对应BLIP第一阶段的学习过程,有三个任务,训练三个loss。其一是ITM,这个任务图片和文本都是可以相互看到的,因此没有元素被mask;其二是ITG,根据图像生成文本,在这个时候Queries提取到的信息会通过attention层传递过来,Q要能自主地提取图像中的关键信息,因此Q是不能看见T地,而由于这个是生成式任务,T也只能看到Q和当前位置之前地T;其三是ITC,这个任务就是Q和文本分别编码,期望得到的特征尽可能接近,因此QT之间都不能看到对方。在经过训练后,第一阶段就能输出一个图像中与文本最相关的信息的编码,在没有文本的时候也会尽力将图片中有价值的信息编码到与文本相近的空间中。
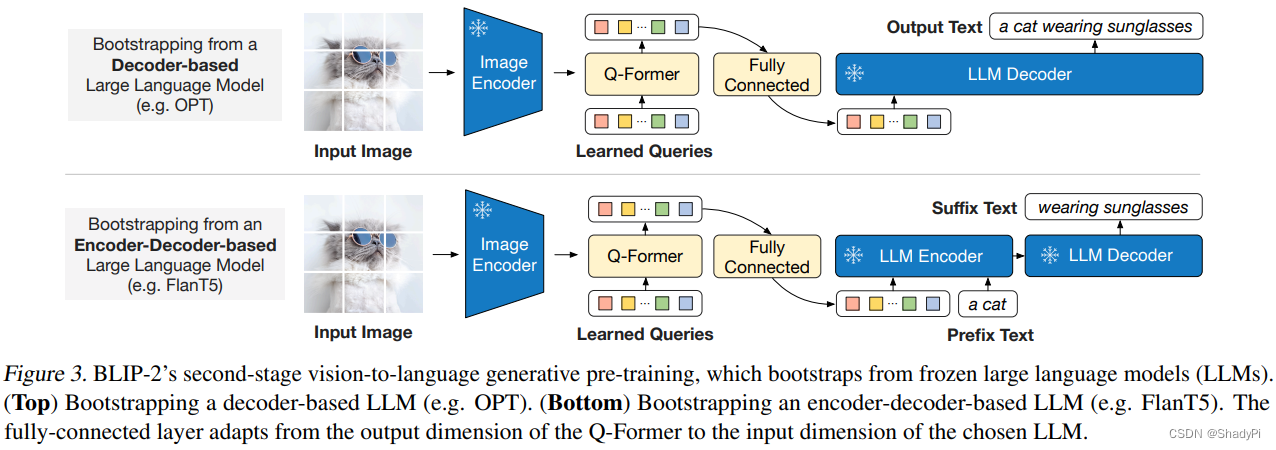
在第二阶段的训练中,我们把Q-Former输出的编码再接一个全连接层,直接给到冻结的语言大模型中。有两种模式,一种是完全不给文本,让LLM自行生成;另一种则是给一下开头,让LLM进行补全。



















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











