






 本文详细介绍了使用ESP-IDF进行ESP32开发的全过程,包括创建新工程、添加组件、设置目标芯片、配置项目、编译与烧录、监视器操作、擦除Flash、内存检查以及清理编译文件等内容。
本文详细介绍了使用ESP-IDF进行ESP32开发的全过程,包括创建新工程、添加组件、设置目标芯片、配置项目、编译与烧录、监视器操作、擦除Flash、内存检查以及清理编译文件等内容。
ESP32 IDF前端命令开发全过程
仅供本人查阅
开端
如需在 ESP32 上使用 ESP-IDF,请安装以下软件:
ESP-IDF Windows Installer Download
Linux 和 macOS 平台 Installer Download
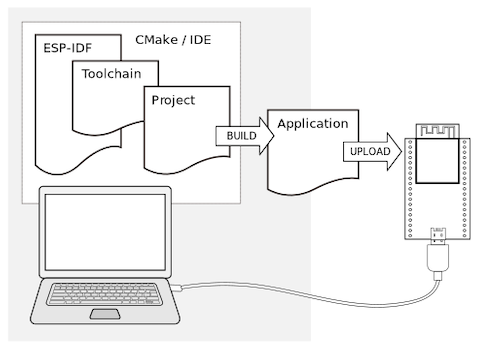
设置 工具链,用于编译 ESP32 代码;
编译构建工具 —— CMake 和 Ninja 编译构建工具,用于编译 ESP32 应用程序;
获取 ESP-IDF 软件开发框架。该框架已经基本包含 ESP32 使用的 API(软件库和源代码)和运行 工具链 的脚本。
1. 创建新工程(create-project)
“idf.py create-project-path ”是ESP-IDF提供的一个命令,用于创建一个新的项目目录结构,并将必要的义件和模板复制到该目录中。
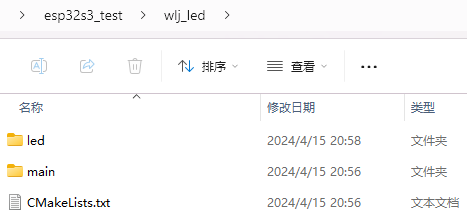
idf.py create-project wlj_led
── wlj_led
──├──main
────├──wlj_led.c
────├──CMakeLists.txt
──├──CMakeLists.txt
2. 创建新组件(create–component)
“idf.py create-component:”创建一个新的组件,包含构建所需的最基本文件集。一般存放第三方组件,如编写的驱动程序等。
下面是这个命令的参数解析和使用方法。
cd led
idf.py create-component led
── led
──├──include
──────├──led.h
──├──led.c
──├──CMakeLists.txt
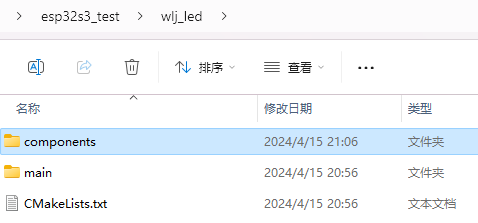
mkdir components
mv led C:\Users\93254\Desktop\esp32s3_test\wlj_led\components
── components
──├──led
────├──include
────────├──led.h
────├──led.c
────├──CMakeLists.txt
目前文件结构
── wlj_led
──├── main
────├── wlj_led.c
────├── CMakeLists.txt
──├── components
──├──├── led
──├────├── include
──├────────├── led.h
──├────├── led.c
──├────├── CMakeLists.txt
──├── CMakeLists.txt
3. 设置目标芯片
“ idf.py set-target ”命令用于设置工程的目标芯片。由于ESP-DF支持多款乐鑫SoC芯片,新建工程时默认会选择ESP2类型的芯片。因此,如果我们希望创建个针对ESP32-S3类型的工程,就必须使用此命令来指定该工程的目标芯片为ESP32-S3。
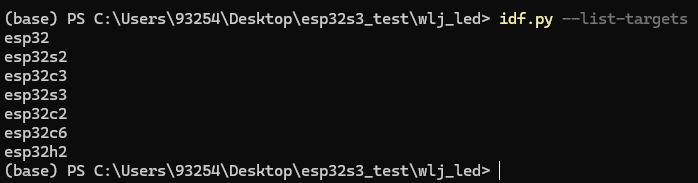
target :目标芯片,可使用“idf.py --list-targets”命令查看支持的芯片类型。
idf.py --list-targets
设置工程的目标芯片
idf.py set-target esp32s3
编译工程并生成 sdkconfig
注意:“idf.py set-target’”命令将清除构建目录,并从头开始重新生成sdkconfig文件。旧的sdkconfig文件将保存为sdkconfig.old。
4. 配置项目
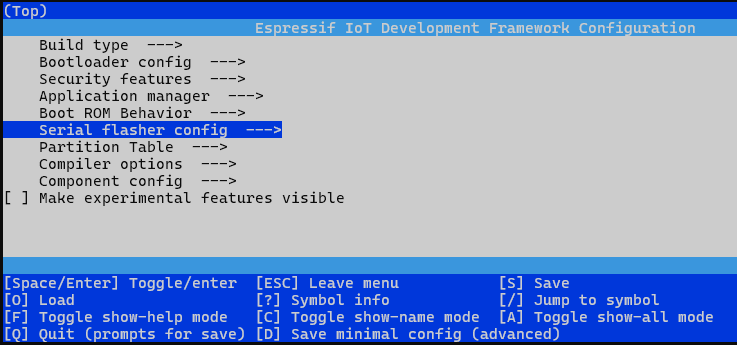
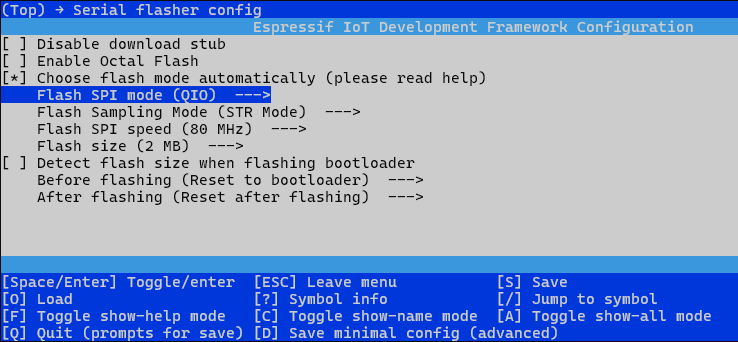
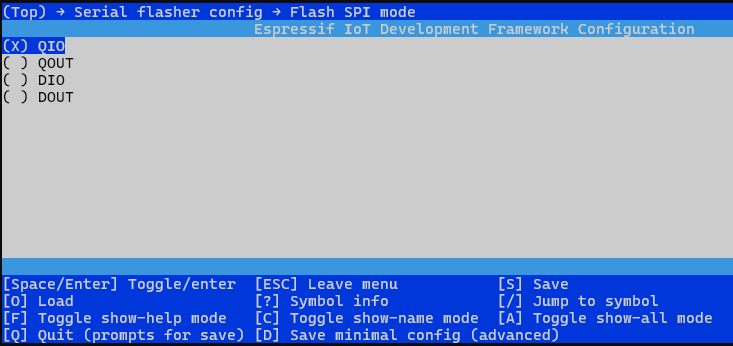
“idf.py menuconfig”这个命令会启动一个文本用户界面,允许开发者为他们的ESP32或其他Espressif SoC芯片系列的项目配置各种选项。如下图所示:
idf.py menuconfig
选择component config–>FreeRTOS–>然后单核就选中Run FreeRTOS only on first core,双核就不选。


5. 编译工程
编写wlj_led.c
#include <stdio.h>
void app_main(void)
{
printf("Hello MEIYOUYUDI");
}
“idf.py build”命令用来编译当前项目工程。如下所示:
idf.py build
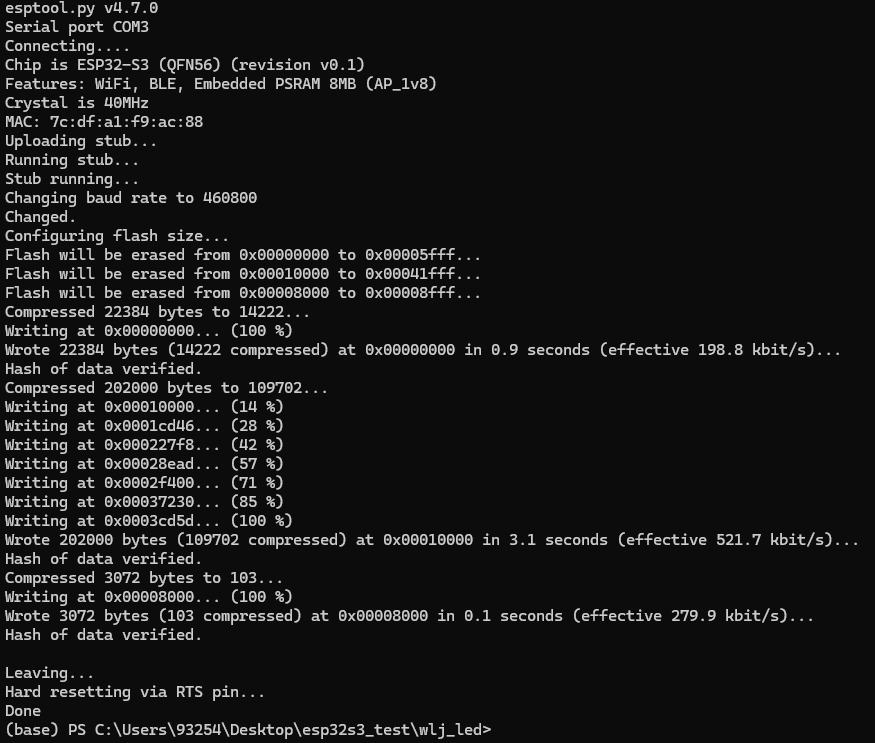
6. 烧录程序
“idf.py -p PORT flash”这个命令用来把编译出来的可执行文件烧录到ESP32-S3芯片当中。
注意:烧录之前必须调用“idf.py build’”命令编译项目工程,编译完成后方能烧录代码。
比如:windows下COM3口:
cd build
idf.py -p COM3 flash
linux下ACM0口:
idf.py -p dev/ttyACM0 flash
查询Linux下的烧录口:
输入指令:ls /dev/tty* 插上设备后多出来的就是对应的烧录口
ESP32烧录bin,乐鑫下载工具使用flash_download_tool
ESP32【分区表】
7. 打开监视器
“idf.py -p PORT monitor’”命令用来监控当前项目。监控之前必须安装USB虚拟串口驱动以及开发
板上的USB串口接入到电脑当中,才能监控当前项目工程。
注意:请按“Ctl+]”快捷键退出监控器
idf.py -p COM3 monitor
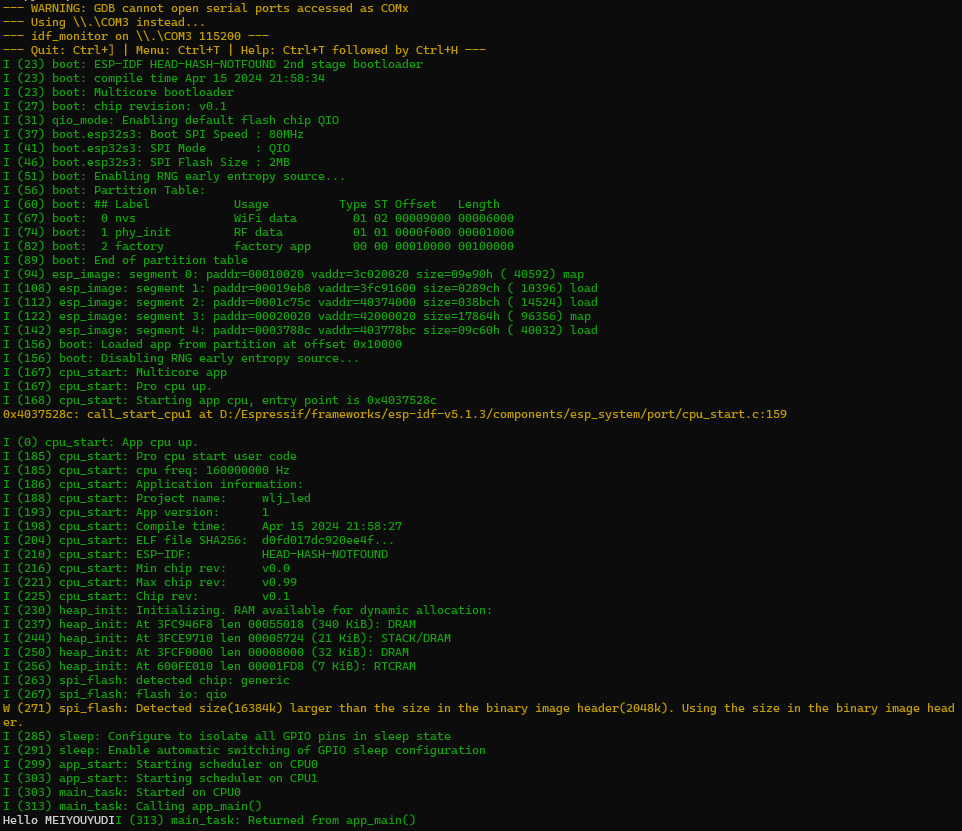
8. 一次性编译烧录并打开监视器
idf.py -p COM3 flash monitor
idf.py -p /dev/ttyACM0 flash monitor
9. 擦除设备flash
idf.py -p PORT erase_flash
10. 查询内存剩余
idf.py size
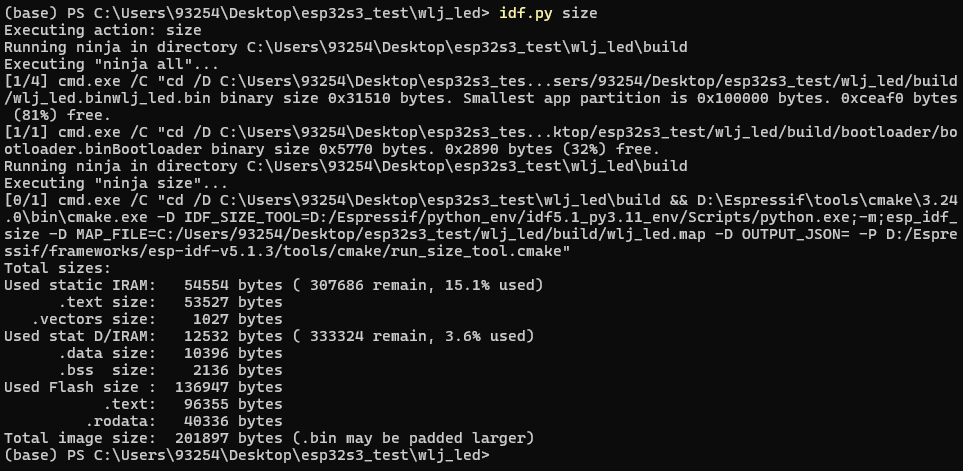
11. 清除编译文件
①“idf.py clean’”命令
②“idf.py fullclean”命令
②这个命令则更为彻底,它会删除整个build目录下的所有内容,包括所有的CMake配置输出文件。这意味若下次构建项目时,CMake将需要从头开始配置项目,重新生成所有的构建输出文件。
idf.py fullclean



















 1054
1054




 到【灌水乐园】发言
到【灌水乐园】发言









