






本文的写作来源于以下这篇稿子的学习:
YOLO系列算法精讲:从yolov1至yolov8的进阶之路(2万字超全整理)-优快云博客
西部延时,我们开始吧!
一、yolo v1版本的出现
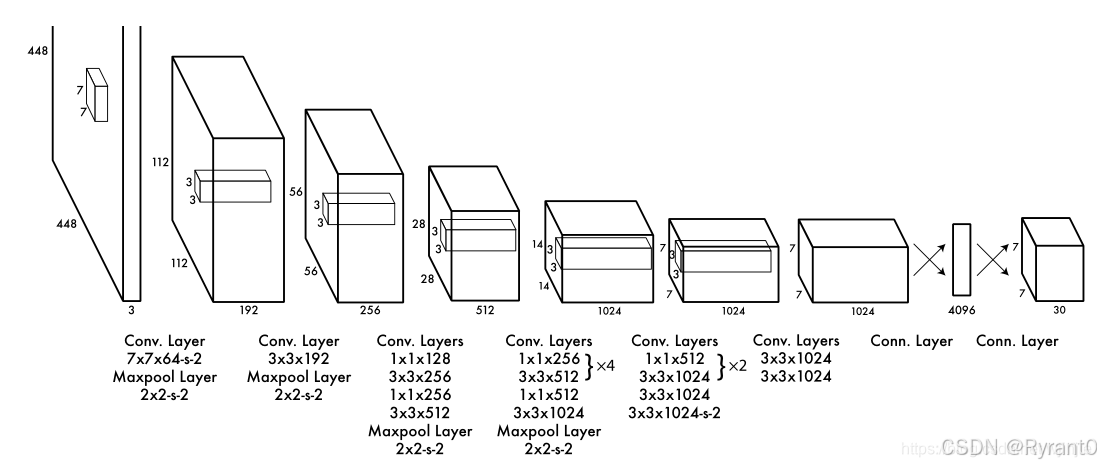
(1)首先,我们可以看到yolo的结构
YOLOv1的网路结构非常明晰,是一种传统的one-stage的卷积神经网络。
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
(2)具体实现过程如下:
①将一幅图像分成 S×S个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。(可以看到这时候的“先验框”还只是随机的)
②每个网格要预测 B 个bounding box,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。
③每个网格还要预测一个类别信息,记为 C 个类。
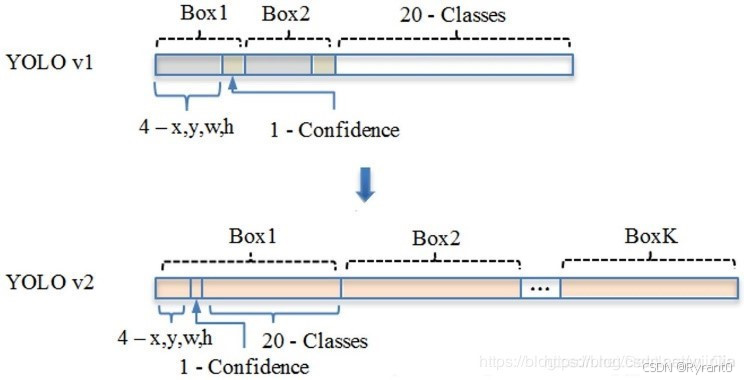
总的来说,S×S 个网格,每个网格要预测 B个bounding box ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C) 的张量。
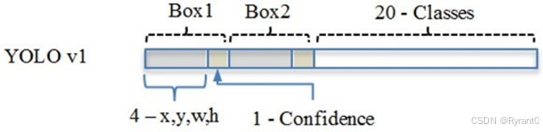
实际采用7 * 7 的网格,有2个box,20个类别,也就是7 * 7 * 30的张量。
(3)目标损失函数
建议直接AI解决嘿嘿😄
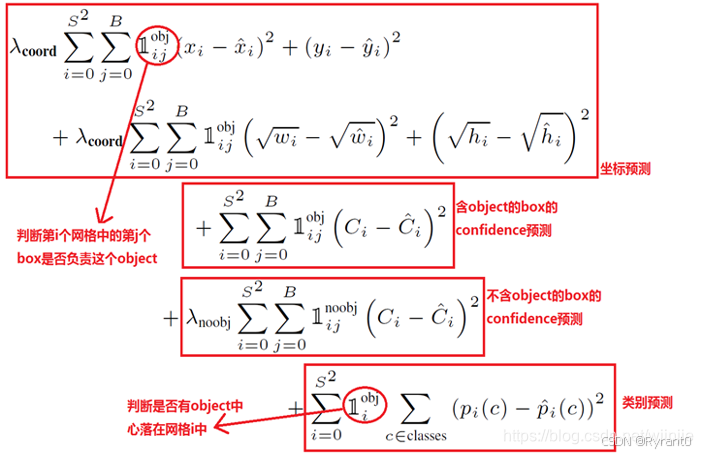
由3个误差组成:
坐标预测损失、置信度预测损失、类别预测损失。
采用的是数学的差方和误差。
二、yolo v2的加强
出现原因:重点解决YOLOv1召回率和定位精度方面的不足
解决方案:
(1)采用了Darknet-19作为特征提取的方法,
总结如下:
①与VGG相似,使用了很多3×3卷积核;
②并且每一次池化后,下一层的卷积核的通道数 = 池化输出的通道 × 2。
③在每一层卷积后,都增加了批量标准化(Batch Normalization)进行预处理。
如下图所示:

④采用了降维的思想,把1×1的卷积置于3×3之间(类似特征融合)Fine-Grained Features,用来压缩特征。
添加一个Passthrough Layer,把高分辨率的浅层特征连接到低分辨率的深层特征(把特征堆积在不同Channel中)而后进行融合和检测。
具体操作是:先获取前层的26×26的特征图,将其同最后输出的13×13的特征图进行连接,而后输入检测器进行检测(而在YOLOv1中网络的FC层起到了全局特征融合的作用),以此来提高对小目标的检测能力。
⑤在网络最后的输出增加了一个global average pooling层。
⑥引入 Anchor Box 机制:采用K-means聚类算法,提前筛选得到的具有代表性先验框Anchors,使得网络在训练时更容易收敛。
与传统K-means聚类算法不同的是,这里的距离度量公式用:
![]()
同时,根据原文做出的数据实验来看,采用K = 5是最优解。
如图,蓝色的是要预测的,黑色虚线是先验框。
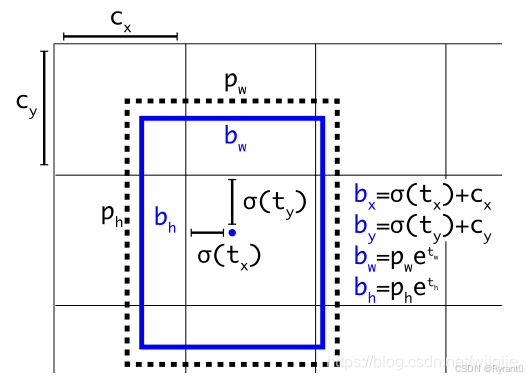
那么,引入Anchor Box 机制后,通过间接预测得到的 bounding box 的位置的计算公式为:
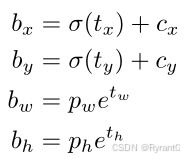
置信度ot 的计算公式为:
![]()
⑦总体上,变化还有如下图所示,即Convolution With Anchor Boxes
三、yolo v3的巅峰神作
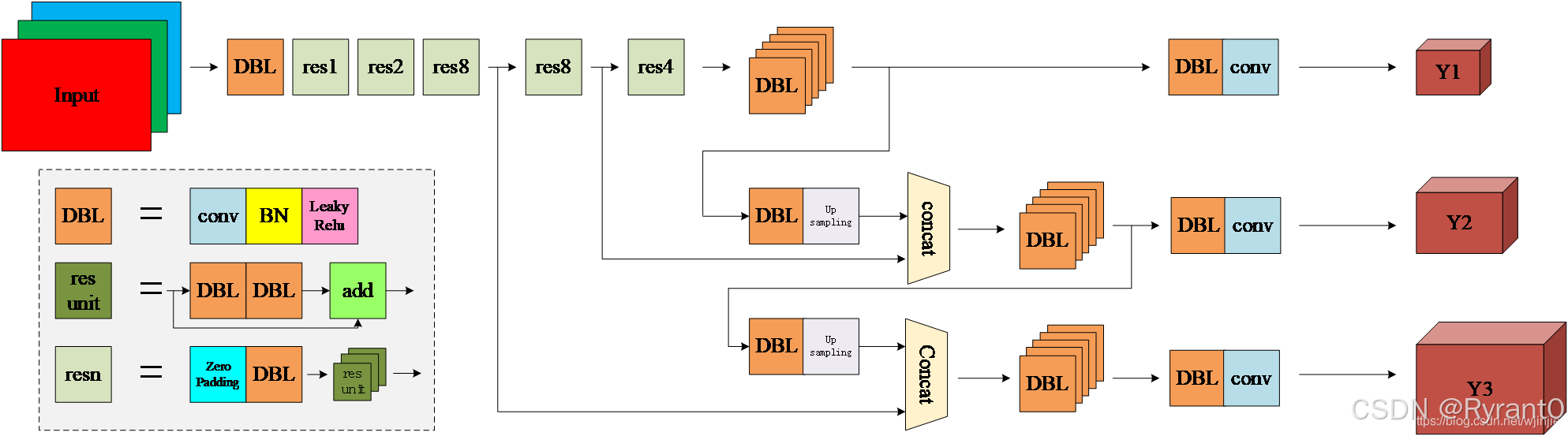
(1)网络结构再次升级
YOLOv3 将原来的 darknet-19 改进为 darknet-53:
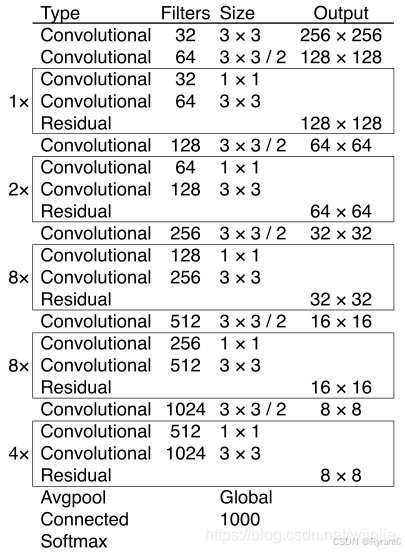
Darknet-53主要由1×1和3×3的卷积层组成,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两个部分的目的是为了防止过拟合。
卷积层、批量归一化层以及Leaky ReLU共同组成Darknet-53中的基本卷积单元DBL。
因为在Darknet-53中共包含53个这样的DBL,所以称其为Darknet-53。
具体结构如下图所示:

借由作者的分析,与darknet-19对比可知,darknet-53主要做了如下改进:
①不采用最大池化层,采用步长为2的卷积层进行下采样。
②为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU。
③引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
④将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。
(2)多尺度预测
采用了3种每种3个anchor:

(3)损失函数
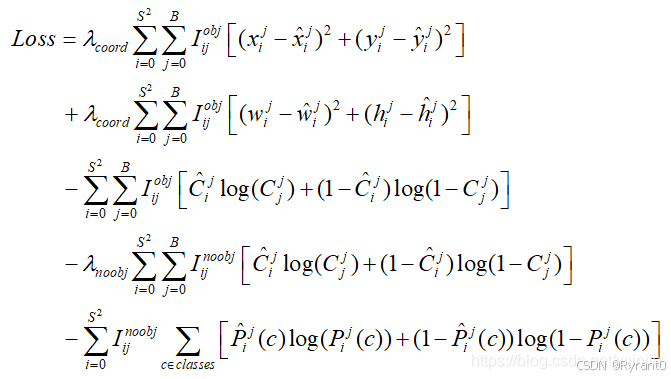
上面提到过损失函数由3种损失组成,这里,位置损失没有改变计算方式,但是置信度损失和类别预测均由原来的sum-square error改为了交叉熵的损失计算方法。
(4)多标签分类
具体来说,就是将YOLOv2中用于分类的softmax层修改为逻辑分类器。
softmax是将向量转化为类似概率的输出。
逻辑回归则是解决二分类问题。
从而使得网络可以对一个物体进行多分类而不局限于单一类别。

















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









