






本文的写作来源于以下这篇稿子的学习:
YOLO系列算法精讲:从yolov1至yolov8的进阶之路(2万字超全整理)-优快云博客
西部延时,我们开始吧!
一、YOLO v9创世纪再临
(1)更新原因:当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失(信息瓶颈和可逆函数)新概念呀。
看看信息瓶颈是啥呗:即输入数据在前馈过程中丢失信息的现象。

①作者提出了可编程梯度信息(PGI)的概念:
即通过辅助可逆分支生成可靠的梯度,使得深层特征仍然能够保持执行目标任务的关键特征
② 此外,还设计了一种基于梯度路径规划的新型轻量级网络架构——通用高效层聚合网络GELAN,两者都取得了优异表现。
GELAN的设计同时考虑了参数数量、计算复杂度、准确性和推理速度。这种设计允许用户针对不同的推理设备任意选择合适的计算块。
PGI和GELAN结合起来就是YOLO v9的优化之处啦!!!
(2)核心优化方法
①PGI主要包括三个组成部分:主分支、辅助可逆分支、多级辅助信息。
给个示意图来看看呀:
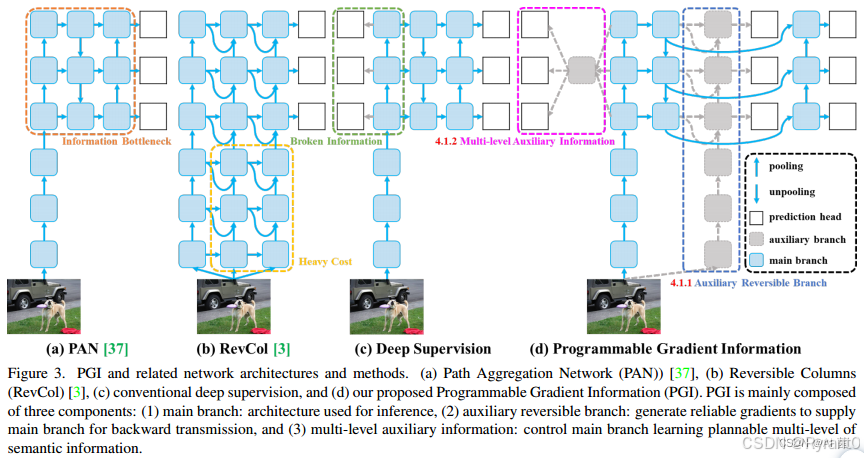
PGI的推理过程仅使用主分支,因此不需要任何额外的推理成本。
(以下仅用于训练阶段而不在推理阶段)
- 辅助可逆分支:是为了处理神经网络加深带来的问题而设计的。网络加深会造成信息瓶颈,导致损失函数无法生成可靠的梯度。
对于由于信息瓶颈而丢失重要信息的主分支深度特征,它们将能够从辅助可逆分支接收可靠的梯度信息。
聪明的读者一定会有一个问题,可逆架构在浅层网络上的表现比在一般网络上差,因为复杂的任务需要在更深的网络中进行转换。没错,作者并不强迫主分支保留完整的原始信息,而是通过辅助监督机制生成有用的梯度来更新它。这种设计的优点是提出的方法也可以应用于较浅的网络。
- 多级辅助信息:旨在处理深度监督带来的误差累积问题,特别是针对多个预测分支的架构和轻量级模型。
连接到深度监督分支后,会引导浅层特征学习小物体检测所需的特征,此时系统会将其他尺寸的物体的位置视为背景。然而,上述行为会导致深层特征金字塔丢失大量预测目标对象所需的信息。关于这个问题,每个特征金字塔都需要接收所有目标对象的信息,以便后续的主分支可以保留完整的信息来学习对各种目标的预测。
定义:在辅助监督的特征金字塔层次层和主分支之间插入一个集成网络,然后用它来组合来自不同预测头的返回梯度。多级辅助信息就是将包含所有目标物体的梯度信息聚合起来,传递给主分支,然后更新参数。
②GELAN:
通过结合采用梯度路径规划设计的两种神经网络架构CSPNet 和ELAN 就得到了呀!!!
(3)总结上:YOLO v9即提出使用PGI来解决信息瓶颈问题以及深度监督机制不适合轻量级神经网络的问题。本文设计了 一个高效、轻量级的神经网络GELAN。使得深度模型相比YOLOv8减少了49%的参数数量和43%的计算量,但在MS COCO数据集上仍然有0.6%的AP提升。
二、YOLO v10清华出品
YOLO v10 在原来版本的优良基础上再次对模型架构和后处理上进行了创新性改进,进一步提升了检测性能和效率。YOLOv10的核心贡献可以概括为以下几点:
①无NMS(Non-Maximum Suppression)训练:
新的一致性双重赋值策略(Consistent Dual Assignments),在训练时能够获得丰富的监督信号,在推理时则无需NMS即可实现高效的端到端检测。
该策略在训练时采用一对多的赋值方式提供丰富的监督信号,在推理时则切换到一对一的赋值方式。
我们来具体看看吧!
「双标签分配」结合了上述两种策略的优点。 YOLO 引入了另一个一对一 head。它保留了与原始一对多分支相同的结构并采用相同的优化目标,但利用一对一匹配来获取标签分配。在训练过程中,两个 head 联合优化,以提供丰富的监督;在推理过程中,YOLOv10 会丢弃一对多 head 并利用一对一 head 做出预测。这使得 YOLO 能够进行端到端部署,而不会产生任何额外的推理成本。
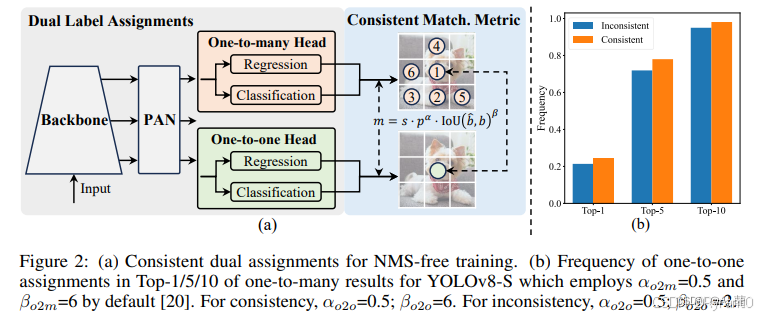
②全面优化的模型架构:
- 轻量级分类头:简化分类头的网络结构,减少计算量。
- 空间-通道解耦下采样:将空间下采样和通道变换操作分离,降低计算复杂度。
- 基于秩引导的模块设计:根据模型不同阶段的冗余程度,动态调整网络模块,提高计算效率。
③大核心卷积和部分自注意力模块:YOLOv10引入了大核心卷积来扩大感受野,并提出了部分自注意力模块(PSA),以较低的计算成本增强模型性能。不能再所有阶段都暴力的使用,这样会使得浅层特征被“污染”,so,在深阶段利用CIB中的大核深度卷积。具体上,将CIB中第二个3×3深度卷积的核大小增加到7×7。此外,本文采用结构重参数化技术引入另一个3×3深度卷积分支。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









